Perchè un ennesimo articolo sulle pipeline? In rete si trova già molto materiale, e anche qui su Appunti Digitali Yossarian ha già scritto almeno due articoli al riguardo (qui e qui).
Tuttavia, avendo in programma di scrivere una serie di articoli sull’architettura di processori superscalari out-of-order, è necessario avere ben chiari alcuni concetti sulle pipeline in-order, per capirne funzionamento, prestazioni e limiti, e comprendere quindi cosa ha spinto i computer architect a cimentarsi con qualcosa di così complesso come i processori out-of-order.
In questo articolo farò un ripasso delle pipeline in-order, partendo da una visione “idealizzata” e andando poi a rimuovere queste idealità. Nel prossimo articolo vedremo come si costruisce una pipeline “reale”, che sia cioè non solo corretta ma anche veloce, e ne investigheremo i limiti.
Pipeline: una catena di montaggio
La tecnica di pipelining è la più vecchia, semplice ed efficace per aumentare le prestazioni di un processore. Il numero di stadi di una pipeline può variare moltissimo a seconda del periodo storico, del costo del processore, e dell’ambito di utilizzo: in applicazioni consumer si è andati dai soli 3 stadi di certi ARM ai 31 stadi della famigerata architettura NetBurst (nella sua ultima versione, quella del Prescott), mentre per certe applicazioni particolari vengono usate pipeline anche molto più lunghe (ad esempio il mostruoso migliaio di stadi del processore di rete Xelerated X10q).
Il concetto base è semplice: supponiamo di avere un processore single-cycle, ovvero che esegue una e una sola istruzione completa (dal fetch al ritiro) in un ciclo di clock. Evidentemente, c’è un grosso spreco nell’utilizzo della logica: dopo che l’istruzione è stata caricata ed è stata avviata all’unità di esecuzione, la logica di fetch sta a girarsi i pollici fino alla fine del ciclo; allo stesso modo, dopo che l’istruzione ha lasciato l’unità di esecuzione e si avvia alla fase di ritiro (ad esempio, aggiornare il valore di un registro), anche l’unità di esecuzione attende, senza produrre lavoro utile.
Molto più efficiente sarebbe applicare anche qui il principio della catena di montaggio: dopo che una istruzione lascia il fetch, subito cominciare il fetch della prossima, e così via. Per farlo, è necessario “spezzare” il processore in più sezioni indipendenti, che lavorano, nello stesso momento, su istruzioni diverse; le diverse sezioni sono isolate l’una dall’altra tramite buffer (nel caso più semplice, dei banchi di flip-flop (registri) che mantengono lo stato dell’istruzione man mano che essa procede lungo la pipeline).
Il ritardo di questi buffer si aggiunge al tempo di esecuzione dell’istruzione: il tempo per eseguire la singola istruzione è più alto, ma il throughput del sistema (che equivale alla performance) è maggiore, perchè più istruzioni vengono “lavorate” contemporaneamente.
Quanti stadi?
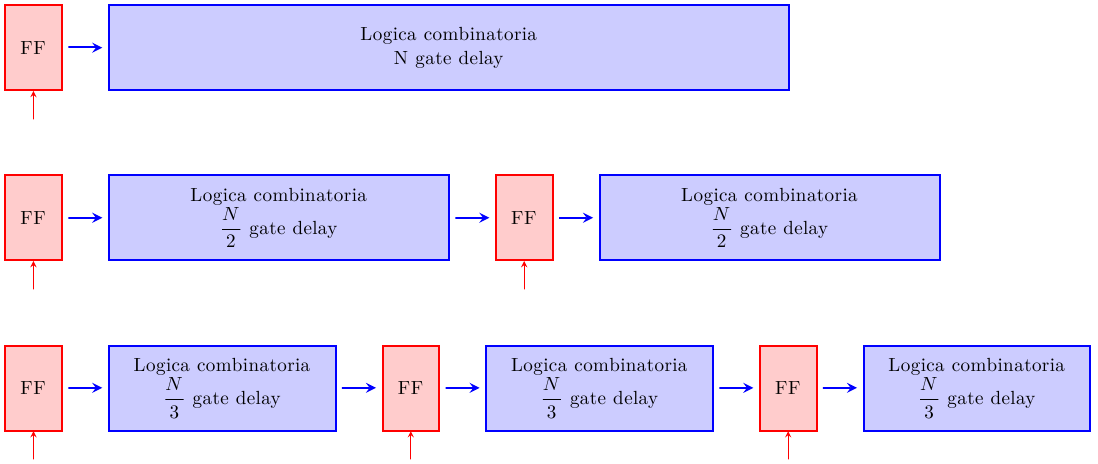
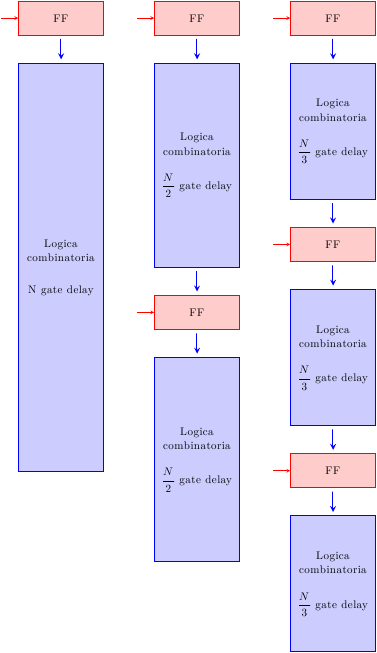
Appurato che suddividere il circuito in più stadi è vantaggioso, la domanda successiva è ovvia: quanti stadi? Un semplice modello che studia il tradeoff tra costo e performance (dovuto a Peter Kogge, 1981) è quello illustrato in figura:
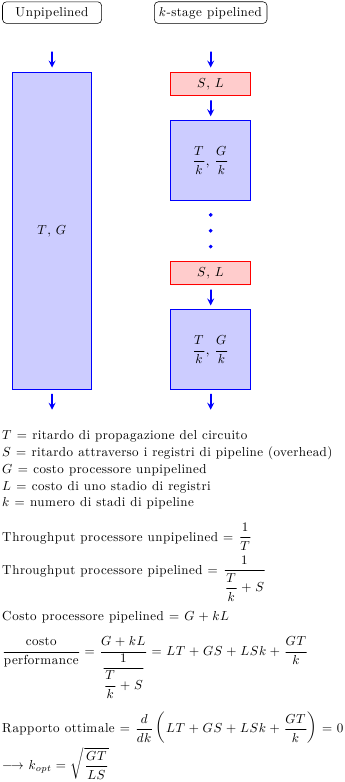
Si parta dal processore single-cycle (cioè senza pipeline), con un ritardo di propagazione T (e quindi un throughput di 1/T) e un costo hardware G. Ogni stadio di pipeline aggiunge dei registri, che hanno un ritardo S e un costo L. Il throughput e il costo del processore pipelined a k stadi è mostrato in figura, cosi’ come il punto ottimo.
La formula per k_opt è intuitiva: il ritardo e il costo dei registri stanno al denominatore, cioè più i registri costano poco, più conviene aggiungere stadi. All’inizio, aggiungendo pochi stadi si ottengono grossi incrementi prestazionali con poco costo. Man mano che si aggiungono stadi, il miglioramento prestazionale diventa via via sempre più piccolo (ormai gli stadi sono così piccoli che il tempo di ritardo è dominato dai registri di pipeline), mentre il costo hardware continua ad aumentare.
E’ importante ricordare che questa analisi non tiene conto dell’energia consumata dal processore: dato che l’energia cresce indicativamente col cubo della frequenza (a causa dell’aumento di tensione necessario a sostenere frequenze più elevate), pipeline con molti stadi diventano rapidamente svantaggiose, perchè non è possibile aumentare la frequenza oltre limiti ormai “bassi” (pochi Ghz).
Un semplice modello di pipeline ideale
Un modello generico è la pipeline a 6 stadi così costruita:
- Instruction Fetch (IF): la nuova istruzione viene caricata dalla memoria (generalmente, la cache L1 per le istruzioni) per cominciarne l’esecuzione
- Instruction Decode (ID): l’istruzione viene decodificata: bisogna capire che tipo di istruzione è, di quali unità funzionali avrà bisogno, che registri andrà a leggere e/o scrivere, se dovrà accedere alla memoria, eccetera
- Operand Fetch (OF): l’istruzione accede al register file per caricare gli operandi di cui ha bisogno
- Instruction execute (EX): l’istruzione viene “eseguita”: questo può voler dire utilizzare la ALU (se è un’istruzione aritmetico/logica), oppure calcolare un indirizzo di memoria (se è un load/store, o un branch), eccetera
- Memory Access (MEM): se l’istruzione è un load o uno store, in questo stadio accede alla memoria (generalmente, la cache L1 dati)
- Writeback (WB): se l’istruzione deve aggiorare il registro, lo fa adesso; dopodichè, l’istruzione ha terminato
Nella classica pipeline MIPS a 5 stadi, ID e OF sono fusi in un’unico stadio: la decodifica dell’istruzione RISC è così veloce che è possibile accedere subito al register file nello stesso ciclo di clock..
Idealmente, una volta che la pipeline e’ stata riempita e macina istruzioni a ritmo continuo, essa ha questo “aspetto”:
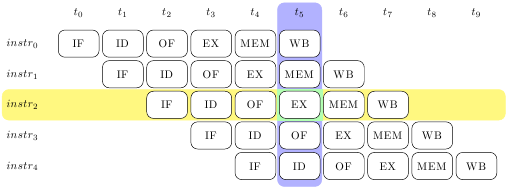 Ogni istruzione prende 6 cicli di clock per completare, uno per stadio, e attraversa tutti gli stadi in ordine. In ogni istante, tutti gli stadi sono occupati, ognuno con un “frammento” diverso di 6 diverse istruzioni.
Ogni istruzione prende 6 cicli di clock per completare, uno per stadio, e attraversa tutti gli stadi in ordine. In ogni istante, tutti gli stadi sono occupati, ognuno con un “frammento” diverso di 6 diverse istruzioni.
Come vedremo, però, questa visione idilliaca è ben lontana dalla realtà.
Rimozione delle idealità
Fino a questo punto sono state fatte alcune ipotesi implicite sull’idealità della pipeline. Esse sono:
- sotto-operazioni uniformi: le operazioni del processore possono essere arbitrariamente suddivise in sotto-operazioni di identica durata
- ripetizione di operazioni identiche: le stesse operazioni vengono ripetute identiche su un grande numero di input diversi
- ripetizione di operazioni indipendenti: tutte le operazioni, e tutti gli stadi, sono indipendenti tra loro (cioè non esiste alcuna dipendenza tra i dati, e nessuna scarsezza di risorse)
Sfortunatamente, tutte queste ipotesi sono false:
- le sotto-operazioni non sono uniformi: non è possibile “tagliare” i circuiti in punti arbitrari, ma solo ai confini delle unità funzionali (o di loro sottocomponenti) o, al massimo, delle porte logiche; è necessario far sì che i diversi stadi siano il più simili possibile, per evitare che gli stadi più veloci sprechino tempo per aspettare quelli più lenti (in quanto il clock deve essere tanto lungo quando lo stadio più lento)
- le operazioni non sono identiche: una ISA ha nell’ordine delle centinaia di diverse istruzioni; costruire una pipeline “multifunzionale” capace di eseguirle tutte vuol dire avere degli stadi dedicati a certe istruzioni, che dovranno essere attraversati (inutilmente) da altre istruzioni che non ne fanno uso; è necessario minimizzare il numero di questi stadi
- le operazioni non sono indipendenti: il più delle volte un’istruzione dipende dal risultato di una precedente (ad esempio, l’istruzione numero i genera un operando per l’istruzione i+1); è fondamentale scoprire e risolvere tutte queste dipendenze, pena l’esecuzione errata del programma
I primi due punti ci dicono qualcosa riguardo le prestazioni della pipeline. Rendere le sotto-operazioni il più uniforme possibile (dal punto di vista temporale) significa poter spingere il clock fino al limite massimo (esempio: se si divide un circuito che prende 1 ns in .3 ns e .7 ns, il clock dovrà per forza andare a .7 ns, cioè 1.4 GHz; ma se si riesce a spezzarlo in due stadi da .5 ns, allora si riuscirà a spingerlo fino a 2 GHz). Inoltre, minimizzare gli stadi “idle” per certe istruzioni significa rendere disponibili prima i loro risultati, risultati che saranno utilizzati dalle istruzioni successive.
Ma il terzo punto ci dice qualcosa di diverso: se non teniamo conto delle dipendenze tra le istruzioni, il programma non sarà lento, ma sbagliato! Il problema è che l’ISA ci dice di assumere che una e una sola istruzione sia in esecuzione in un dato istante, e che ogni istruzione deve essere completata (che significa aver eseguito e aver aggiornato tutti i registri e le locazioni di memoria che le competono) prima che l’istruzione successiva cominci l’esecuzione. In una pipeline, questo non è vero: per accelerare, cominciamo ad eseguire l’istruzione i+1 quando l’istruzione i non ha ancora finito. Se non ne teniamo conto, l’istruzione i+1 accederà ai dati sbagliati, lo stato della macchina verrà distrutto, e il programma fallirà.
Conclusioni
In questo articolo abbiamo ripassato le basi della tecnica di pipelining, e abbiamo visto le sue non-idealità in termini molto qualitativi. Nel prossimo articolo mostrerò le tecniche impiegate per costruire una pipeline “reale”: interlock e stalli per garantire il corretto funzionamento, e forwarding per spremere al massimo le prestazioni.







