La corsa alle prestazioni e, soprattutto, ai RISC era iniziata con la precedente generazione e proseguiva per dimostrare, se ancora ce ne fosse stato bisogno, che i CISC non erano affatto spacciati, come alcuni specialisti del settore avevano, al contrario, profetizzato.
L’80486 di Intel e il 68040 di Motorola avevano mostrato che eseguire la maggior parte delle istruzioni in un solo ciclo di clock era possibile anche per questi illustri rappresentanti della macrofamiglia, ma il prossimo scoglio si presentava arduo da superare: eseguirne di più in un solo ciclo con un’ISA avente opcode a lunghezza variabile.
Il problema nasce dalla necessità di stabilire dove finisce un’istruzione e, di conseguenza, dove inizia la successiva o, peggio ancora, le successive. I RISC hanno vita estremamente facile perché le loro istruzioni sono a lunghezza fissa (generalmente 32 bit; opcode più lunghi si hanno con le architetture VLIW, che però “impacchettano” più istruzioni), e risulta quindi banale individuare immediatamente l’istruzione corrente e tutte quelle successive.
Coi CISC calcolare l’inizio dell’istruzione successiva è già un bel rompicapo perché, manco a dirlo, bisogna prima conoscere la lunghezza di quella in esame; e così via per quelle a seguire. La difficoltà sta nel fatto che queste informazioni si possono recuperare soltanto a runtime, quando cioè il codice viene eseguito, perché limitandoci a leggere un blocco di dati dalla memoria non si sa se il primo byte è anche il primo di un’istruzione, oppure ci troviamo nel bel mezzo di una di esse (che, quindi, inizia nel blocco precedente e prosegue in quello attuale).
Non si tratta di problemi impossibili da risolvere, poiché allo scopo esistono soluzioni anche molto efficienti che gli ingegneri di Intel e Motorola prima, e AMD in seguito, hanno tirato fuori dal cappello per risolverli. Ma, come capita spesso, ciò è frutto di compromessi che, nello specifico, si traducono in un maggior numero di transistor da impiegare e consumi più elevati.
Con queste doverose premesse è Intel che, al solito, anticipa Motorola presentando l’arcinoto Pentium, CPU superscalare in order dotata di due pipeline (sebbene non simmetriche: soltanto la prima era in grado di eseguire tutte le operazioni). Il 68060, erede del 68040 (e non del 68050, come abbiamo avuto modo di appurare), arriva l’anno successivo, nel 1994, con caratteristiche simili.
Due milioni e mezzo di transistor per questa CPU sono più del doppio rispetto agli 1,17 del suo predecessore, ma ciò non si riflette in almeno un raddoppio delle prestazioni. Motorola, infatti, dichiara più di 110 MIPS e circa 18 MFLOPS a 75Mhz (in realtà ho trovato riferimenti per 12 MFLOPS a 50Mhz). Mentre un ipotetico 68040 a 75Mhz con la sua singola pipeline dovrebbe arrivare rispettivamente a 60 MIPS e 10,5 MFLOPS (anche se su queste misure mi riservo alcune osservazioni, in particolare alla fine dell’articolo).
Già da questi numeri risulta evidente che una superpipeline non può certo garantire un andamento lineare delle prestazioni. Bisogna sempre tener conto che tante volte esistono delle dipendenze fra le istruzioni che ne impediscono l’esecuzione parallela, costringendo il processore alla loro “serializzazione“.
Nonostante tutto e numeri alla mano il 68060 sembra fare un ottimo lavoro, ma ciò è merito anche della possibilità di eseguire un’istruzione di salto per ogni ciclo di clock oltre alle due intere, in modo da minimizzare l’impatto dei cambiamenti nel flusso dell’esecuzione. I salti, in sostanza, sono eseguiti “a costo zero” (zero cicli), ma a condizione che siano “predetti” correttamente. Per meglio comprenderne il funzionamento vediamo intanto il diagramma a blocchi:
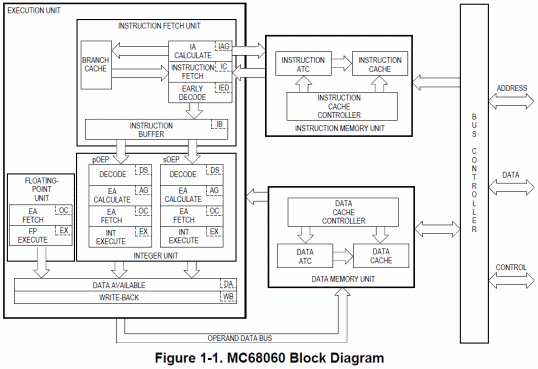
Come per il 68040, l’architettura è completamente Harvard, quindi con un’unità (e bus) dedicata per le istruzioni, una per i dati, e un controller per il bus esterno, tutti indipendenti. Le divergenze si cominciano a notare spostando l’attenzione verso il macroblocco a sinistra (quello dell’unità di esecuzione), che risulta a sua volta suddiviso in: un’unità per il fetch delle istruzioni, una con due pipeline per l’esecuzione delle operazioni intere, una per quelle in virgola mobile, e uno stadio finale per la scrittura dei risultati.
Un’altra differenza è rappresentata dalla presenza di ben 10 stadi per la pipeline intera, che risulta decisamente più lunga paragonata alla precedente a 6 stadi. Ciò si è reso necessario per separare nettamente la fase di fetch delle istruzioni (distribuita su 4 stadi) da quella della loro effettiva esecuzione (che adesso fa uso di due pipeline di 4 stadi allo scopo), disaccoppiando e rendendo (parzialmente) indipendenti le due unità.
Il funzionamento dell’unità di fetch è molto semplice. Il primo passo (o stadio che dir si voglia) riguarda ovviamente il calcolo dell’indirizzo virtuale dell’istruzione da eseguire, il cui risultato viene passato alla cache istruzioni. Il successivo si occupa di prelevare l’opcode dalla cache. Il terzo effettua una predecodifica dell’istruzione. Infine il quarto inserisce l’istruzione preelaborata in un’apposita coda delle istruzioni (IB, Instruction Buffer) pronte per essere eseguite.
In questo scenario s’inserisce il meccanismo di controllo (o predizione) dei salti facendo uso di una cache associativa a 4 vie che contiene fino a 256 indirizzi virtuali che rappresentano gli ultimi target processati. Quando l’unità di fetch predecodifica un’istruzione e si accorge che si tratta di un salto, va a controllare in questa cache se l’indirizzo a cui saltare si trova nella suddetta cache, e analizza la sua “storia”.
Se si tratta di un salto “taken” (quindi con elevate probabilità che risulti “preso”), la coda delle istruzioni da eseguire viene svuotata e procede immediatamente a richiedere alla cache le istruzioni a partire dal nuovo indirizzo. Se tutto va bene e il salto risulta effettivamente “preso”, l’unità di esecuzione nemmeno si accorge del cambiamento di flusso, in quanto si troverà a elaborare le istruzioni prelevate dal target.
In questo modo è come se l’istruzione di salto non venisse effettivamente eseguita, in quanto non arriva all’unità di esecuzione. Ovviamente questo meccanismo non funzionerà se non è possibile stabilire che il salto è “taken”, oppure se la predizione si dovesse rivelare non corretta, andando incontro a una più o meno pesante penalizzazione (fino a 7/8 cicli di clock, a seconda del tipo di istruzione).
L’elemento di giunzione fra l’unità di fetch e quella di esecuzione è rappresentato dalla coda delle istruzioni (IB). Si tratta di una coda di tipo FIFO (First-In, First-Out) di 96 byte, da cui viene prelevata una coppia di istruzioni da eseguire in ordine (come già detto, non si tratta di una pipeline out-of-order) nelle rispettive pipeline intere; se, invece, è riconosciuta un’istruzione che coinvolge l’FPU, viene passata a quest’ultima se non ci sono altre istruzioni in esecuzione nella pipeline dedicata, che può processarla in parallelo a quelle intere.
Il numero, 96, mi suona decisamente strano per diversi motivi. Il primo è che risulta un multiplo di una potenza di due. Il secondo è che, da buon programmatore di questa famiglia di microprocessori, so che una singola istruzione può arrivare alla bellezza di 22 byte di lunghezza. 96 non risulta divisibile per 22, per cui l’IB potrebbe contenere fino a 4 istruzioni “e cocci”. Il terzo è che le istruzioni presenti nell’IB sono a lunghezza fissa, ed è anche il motivo per cui l’unità di fetch le predecodifica: per portarle a una forma “canonica” facile da decodificare per l’apposito stadio presente nell’unità di esecuzione (ebbene sì: il 68060 fa uso di una sorta di unità RISC interne estremamente semplici per l’effettiva esecuzione!).
La soluzione a questo dilemma arriva soltanto spulciando lo user manual fino al capitolo dedicato ai tempi d’esecuzione delle istruzioni, in cui viene spiegato in che modo e in quali condizioni l’unità di esecuzione riesce a eseguire fino a due istruzioni nello stesso ciclo di clock.
Senza perdere tempo nella disamina dei diversi e numerosi casi, dipendenze e limiti (che esulano dallo scopo di quest’articolo), viene spiegato che un’istruzione di MOVE che esegue due accessi alla memoria (quindi entrambi gli operandi puntano a una locazione di memoria) viene divisa in due istruzioni più semplici: la prima per leggere il dato, e la seconda ovviamente per scriverlo.
Poiché la MOVE è l’unica istruzione a presentare la possibilità di specificare un qualunque indirizzamento complesso verso la memoria (ogni modalità d’indirizzamento arriva a richiedere fino a 10 byte per la sua codifica) per entrambi gli operandi, il conto è presto fatto (2 byte per l’opcode, più 10 ciascuno per i due operandi), e il motivo della suddivisione condivisibile (essendo l’unico caso, e il più difficile da manipolare).
Tolta la MOVE, una qualunque altra istruzione arriva al più a 14 byte (4 per l’opcode e 10 per la modalità d’indirizzamento). Da tutto ciò mi sono fatto l’idea che i 96 byte possano contenere 6 istruzioni da 16 byte fissi predecodificate, da girare poi alle unità di esecuzione “RISC” (chiamate internamente OEP, Operand Execution Pipeline). E i conti sembrano finalmente tornare.
Rimanendo su conti e numeri, è impressionante notare l’enorme lavoro fatto da Motorola per migliorare i tempi d’esecuzione delle singole istruzioni, che risultano decisamente ridotti anche confrontati col 68040, il quale aveva già stupito coi suoi 20 MIPS a 25Mhz.
Merito di una sezione di Address Generation Unit (AGU) particolarmente efficace, essendo in grado di calcolare gli indirizzi della stragrande maggioranza delle modalità d’indirizzamento richiedendo… zero cicli di clock (ovviamente perché il calcolo viene effettuato nell’apposito stadio di pipeline e, quindi, “mascherato”), com’è possibile vedere dalla seguente tabella:
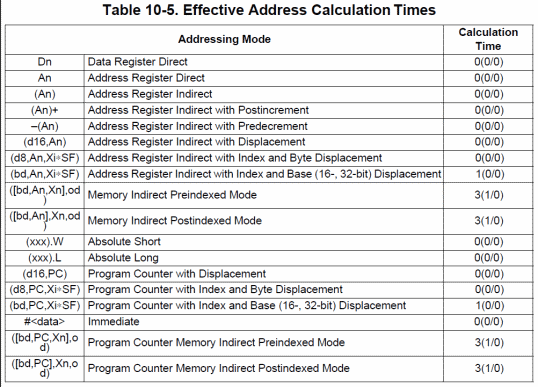
Giusto per dare un’idea, il suo predecessore era in grado di fare lo stesso soltanto con le 7 modalità più semplici, mentre con le altre le penalizzazioni cominciavano a diventare consistenti, tanto da arrivare a 11 cicli di clock per la modalità indiretta più complicata (l’ultima), per la quale i 3 miseri cicli di clock del 68060 fanno quasi sorridere (specialmente pensando a tutto il lavoro che viene svolto dall’AGU in questo caso).
Anche sul fronte delle singole istruzioni, come accennavo prima, molto è stato fatto. Basti pensare che una moltiplicazione 32×32->32 bit con le modalità d’indirizzamento “a zero cicli” (di calcolo dell’indirizzo, come già detto) richiede a malapena 2 cicli di clock (prima almeno 20), e lo stesso dicasi per l’istruzione CHK per il controllo dei limiti di un array (prima servivano almeno 8 cicli).
Persino le istruzioni che manipolano campi di bit sono diventate appetibili, richiedendo da un minimo di 6 a un massimo di 16 cicli di clock per le più complicate e che fanno anche uso delle famigerate modalità d’indirizzamento indirette verso la memoria.
In generale, fatta eccezione per il calcolo dell’indirizzo (per il quale fa fede la tabella sopra riportata), la stragrande maggioranza delle istruzioni richiede un solo ciclo. Motorola non si è risparmiata neppure per le istruzioni “legacy” (come quelle che operano su dati packed BCD), per quelle che manipolano i flag del registro di stato, gli shift, i singoli bit, ecc.
Per poter sfamare queste due “bocche” affamate è stato necessario raddoppiare le cache per il codice e i dati, che passano entrambe a 8KB a 4 vie, suddivise in 128 insiemi da 4 linee ciascuna di 16 byte. Rispetto al 68040 c’è un cambiamento per la cache dati, dove spariscono i 4 flag “dirty” (uno per ogni longword), rimpiazzati da uno soltanto, il quale indica che l’intera linea di cache va scritta in memoria (poiché modificata):

Si tratta di una soluzione più semplice, ma che purtroppo può risultare penalizzante perché obbliga a scrivere un’intera linea alla volta, anche se è stata cambiata una sola delle 4 longword. Per mitigare quest’effetto indesiderato, il 68060 fa uso di un nuovo meccanismo: il push buffer.
Una linea di cache dati che risulta “dirty” e dev’essere rimpiazzata (perché un’altra più nuova deve prenderne il posto) viene trasferita in un questo push buffer in attesa che il bus controller si liberi e possa, quindi, procedere alla sua scrittura in memoria, rendendo disponibile il posto per un’altra linea “dirty” da sostituire.
A questo utile strumento ne viene affiancato un altro, lo store buffer. Si tratta di una coda FIFO di 4 elementi, per un totale di 16 byte massimi, che si occupa di raccogliere le operazioni di scrittura generate dagli ultimi 2 stadi della pipeline. Non appena il bus controller si libera e non vi sono altre operazioni pendenti, il dato più vecchio viene finalmente spedito alla memoria.
Si tratta di una funzionalità che contribuisce all’aumento prestazioni generali della CPU, perché la pipeline è in grado di generare una scrittura per ciclo di clock, mentre il bus esterno in genere è più lento e nel caso migliore impiega 2 cicli di clock per memorizzare il dato in una qualunque zona di memoria. In questo modo pipeline e memoria risultano completamente disaccoppiate e possono lavorare al meglio nei rispettivi ruoli, eccenzion fatta nei casi in cui lo store buffer risulti pieno e si presenti una nuova scrittura (che comporta lo stallo della pipeline).
Un’altra differenza col 68040 è data dalla possibilità di bloccare il contenuto delle cache, comprese le ATC (Address Traslation Cache) delle rispettive MMU. Ben più interessante è, però, la possibilità di poter eseguire due accessi contemporanei alla sola cache dati. D’altra parte con due pipeline in esecuzione era prevedibile e auspicabile questa scelta.
Nonostante i tanti elementi attivi, Motorola s’è impegnata molto anche nel cercare di contenere i consumi, presentando apposite istruzioni per forzare la CPU a lavorare in una particolare modalità di “sleep“. Inoltre è possibile utilizzare soltanto metà delle cache, delle ATC delle MMU, disabilitare una pipeline e anche l’FPU, il tutto via software.
Proprio nei riguardi dell”FPU è possibile notare altri cambiamenti, in particolare le istruzioni di somma, sottrazione, moltiplicazione e conversione a intero richiedono soltanto 3 cicli di clock, mentre valore assoluto, cambio di segno, confronto e FMOVE soltanto uno. Non si tratta di cambiamenti eccezionali, ma tali da giustificare l’incremento dei MFLOPS di cui parlavo all’inizio dell’articolo.
Le note dolenti le ho riservate alla fine, perché mi riguardano direttamente come programmatore, in quanto certi rospi sono difficili da ingollare. Di fronte a tanto ben di dio, infatti, non posso che storcere il naso di fronte all’eliminazione di qualche istruzione dall’ISA (MOVEP, CHK2, CAS2, CMP2, moltiplicazioni e divisioni a 64 bit, e alcune istruzioni dell’FPU).
In ogni caso vale quanto già espresso nel precedente articolo sul 68040: si tratta di scelte dovute, di sacrifici necessari sull’altare dell’aumento delle prestazioni per le rimanenti istruzioni. La tendenza rimane, quindi, quella di eliminare le istruzioni più complesse, che avrebbero di conseguenza complicato l’unità di esecuzione deputata alla loro elaborazione (quella primaria).
Pur potendo utilizzare la seconda pipeline soltanto per le istruzioni più semplici (e la primaria per tutto il resto), l’idea che mi sono fatto è di un microprocessore eccezionalmente veloce, tenuto conto di tutto il lavoro effettivamente svolto (e con ciò ricordo che i MIPS, di per sé, non vogliono dire nulla, quando in una sola istruzione è possibile effettuare più “operazioni”).
Un autentico mostro, insomma, e tanto di cappello alla casa madre, ma certamente non per aver mandato prematuramente in pensione una favolosa architettura che ancora oggi gli appassionati rimpiangono amaramente.







