
Nella scorsa puntata avevamo visto, a grandi linee, come funzionano le operazioni di tessellation e quali sono gli stadi di una moderna pipeline grafica, che si occupano dei relativi calcoli. Volendo riassumere, in presenza delle operazioni di tessellation, lo schema a blocchi di una GPU, relativamente alla parte che si occupa delle geometrie, diventa questo
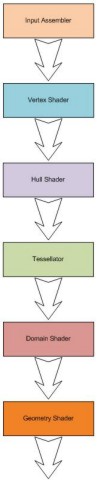
Vediamo, brevemente e con l’ausilio della grafica, più in dettaglio i vari stadi, partendo dall’input assembler
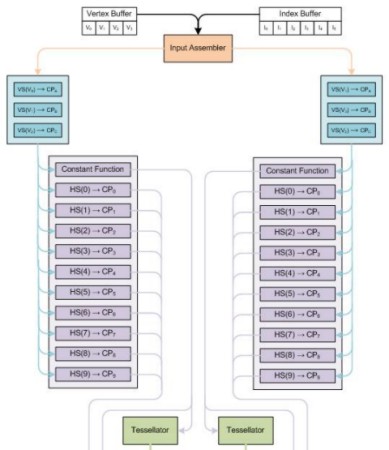
Dallo schema si vede come gli Hull Shader siano, di fatto formati da due elementi, uno, indicato come constant function (CF) e l’altro formato dalla parte programmabile. Il compito dello stadio CF è quello di definire i valori comuni a tutti i control point della patch in input e viene eseguito una volta per patch; il suo output fornirà informazioni sul tessellation factor, da inviare al tessellator vero e proprio. Lo stadio programmabile, invece, come indicano le frecce all’interno di ogni riquadro, in base alle posizioni dei control point iniziali forniti dai VS (vertex shader) ed alla funzione scelta per la tessellation, definirà una serie di nuovi control point da inviare ai domain shader. Dall’immagine, si vede come, in effetti, l’output della constant function diventi l’input del tessellator mentre quello degli Hull shader diventi l’input dei domain shader.
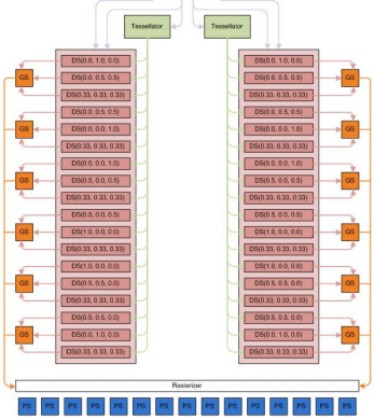
In questa seconda parte della pipeline con tessellator, dove, epr comodità ho riportato lo stadio di tessellation (in verde) presente anche nella prima parte, si vede come i domain shader abbiano in input i nuovi control point definiti dagli hull shader oltre al tessellation factor fornito dallo stadio di tipo constant function. In output dai domain shader, si hanno i nuovi vertici e le nuove primitive definiti dall’operazione di tessellation che sono inviati ai geometry shader. Questo stadio è rimasto del tutto immutato e non ha alcuna in formazione sulle operazioni effettuate in precedenza. Quindi, al contrario dei vertex shader, di fatto non interagiscono con il tessellator ma si limitano a riceverne l’output e ad elaborare le primitive ricevute, da inviare al rasterizer ed alle pixel pipeline.
Terminata questa breve trattazione sul tessellator in generale passiamo ora ad esaminare quella che è stata l’implementazione fatta da ATi e nVidia sulle loro GPU. Facciamo due doverose premesse: la prima è che le operazioni di tessellation non rappresentano una novità assoluta: Xenos, il chip grafico dell’X360 ha un tessellator e la prima implementazione in hardware di uno stadio atto ad aumentare il dettaglio poligonale di un frame risale al 2001 e ad R200 (la Radeon 8500 per i non addetti); la seconda è lo schema mostrato rappresenta l’interpretazione delle operazioni di tessellation che è stata data dalle DX11 che ne hanno ufficializzato l’ingresso nel mondo della grafica 3D di stampo videoludico ma che, da quello schema, è possibile ricavare qualsivoglia variante che si può adattare anche ad architetture fisiche che non ricalcano pedissequamente l’impostazione data da Microsoft.
Come detto, la tessellation seppure in forma primitiva, risale al 2001 ed al truform di R200. Molti ricorderanno l’effetto dell’applicazione delle n-patch in giochi come Morrowind, Half Life o i primi due episodi di Quake giocati con apposita patch. In effetti, il truform faceva uso di n-patch per incrementare il numero di poligoni e “arrotondare le forme”.
Il meccanismo con cui agiva questo tipo di tessellator era piuttosto semplice ed è illustrato nella figura in basso.
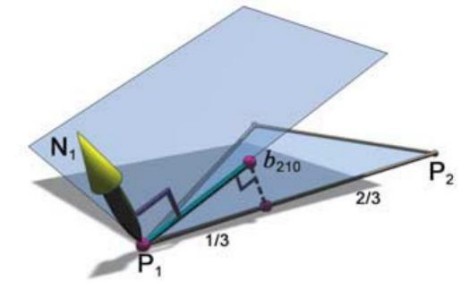
In pratica, da un triangolo in ingresso si prende la normale (N1) ad uno dei vertici (P1 nell’esempio) e il piano da essa definito; si seleziona un punto scelto su uno dei due lati del triangolo che convergono in quel vertice, in modo che questo nuovo punto si trovi ad una distanza pari ad 1/3 del lato su cui è preso, rispetto al vertice di riferimento. Quindi, si proietta il punto così ricavato, sul piano definito da N1. Si ripete lo stesso procedimento sull’altro lato, delimitato dai vertici P1 e P3 (non indicato in figura) e, ancora, lo si ripete per gli altri due vertci. I punti così ricavati definiscono le posizioni dei nuovi punti di controllo e il risultato epr il triangolo in oggetto è quello riportato in figura
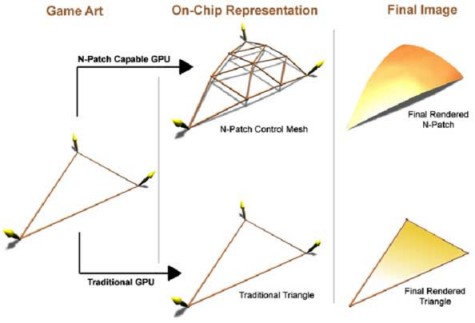
Era, inoltre, possibile porcedere a sezionare ulteriormente i triangoli, creando nuovi control point, sempre con lo stesso procedimento. Preposta ad eseguire questo compito, in R200 era presente un’unità dedicata.
Col passaggio ad R300 e l’aumento da 1 a 4 delle unità vettoriali di vertex shading, viene abbandonata l’unità dedicata e si preferisce demandare il compito alle unità di vertex shading stesse. I risultati sono tutt’altro che eccezionali: con le prime release di driver, R300 arriva al massimo a pareggiare i risultati ottenuti da R200, posizinandosi spesso al di sotto della 8500 (a volte anche di molto). Con le successive ottimizzazioni, la situazione migliora ma non drasticamente ed alla fine, la scelta dell’unità dedicata fatta con R200 si rivela migliore facendo un computo costi (in silicio) benefici, almeno relativamente all’uso del truform.
Nello stesso periodo, anche nVidia stava portando avanti studi sulle higher order surface ma senza implementare un concreto supporto di qualsivoglia tipo a questi studi teorici. A questo punto, si verificano una serie di circostanze, ad iniziare dalla scelta di non ricorrere all’unità dedicata su R300 e derivati e sulle successive due serie (R4x0 ed R5x0), per proseguire con la mancata adozione di una qualsivoglia strategia di sostegno all’uso delle n-patch presso gli sviluppatori, nonostante le n-patch fossero state incluse da Microsoft nelle specifiche D3D delle Dx9 per la generazioni di higher order surface (HOS); dall’altra parte, nVidia prosegue nel suo mancato supporto a qualsivoglia tipologia di implementazione delle HOS.
Insomma, si arriva ad un punto in cui, pur avendo per le mani un tool che potrebbe permettere dei miglioramenti nella qualità d’immagine dei giochi, nessuno spinge più di tanot perchè questo tool sia utilizzato. A dire il vero, la tecnologia su cui si basava il truform era poco evoluta e non permetteva di ottenere risultati particolarmente interessanti in prospettiva. Questo perchè permetteva una tessellation di tipo regolare, basata su fixed function, che non si adatta a rendere al meglio in ogni circostanza. Inoltre ATi stava sviluppando il chip dell’X360 e, di conseguenza, stava portando avanti lo sviluppo di un altro tipo di tessellation, questa volta programmabile.
Si arriva, dunque, alla pipeline DX9 modificata ad hoc per Xenos, come indicato in figura
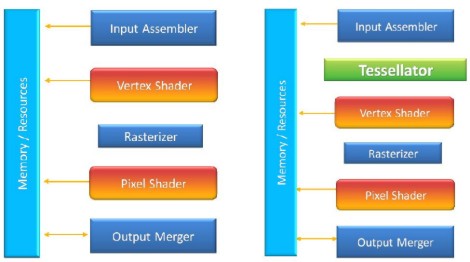
Sulla sinistra è raffigurata la classica pipeline DX9, sulla destra quella di Xenos, ovvero una pipeline DX9 con un’unità di tessellation non programmabile che lavora a 16 bit in virgola fissa. In base a questo schema, in input si ha una mesh “grezza” che viene sottoposta a tessellation di tipo regolare e a displacemnt mapping. In questo schema il tessellator non calcola direttamente i nuovi vertici e neppure li immagazzina in memoria; si limita a prendere una mesh in input, a trasformare le coordinate ricevute in coordinate di tipo parametrico e a calcolare i nuovi punti di questo spazio in base alle istruzioni ricevute.
Quindi passa il tutto, insieme alle coordinate dei control point (vertici della mesh originaria nel world space) ai vertex shader che svolgono la funzione di evaluation shader, ovvero fanno una vera e propria valutazione delle coordinate in input e calcolano le coordinate dei nuovi vertici posizionandoli nel world space. Infine trasforma il world space in clip space.
Insomma, volendo fare un paragone con lo schema che abbiamo visto per le DX11, il tessellator continua a fare il tessellator, mentre i vertex shader svolgono parte dei compiti tipici dei domain shader. Almeno a grandi linee. Questo tipo di implementazione permette, pur facendo uso di unità di tipo fixed function, di applicare la tessellation facendo uso di curve parametriche sia lineari che non lineari e, di fatto, il compito di ricostruire le nuove suoerfici è demandato, comunque, ad uno stadio programmabile della pipeline.
Con le DX10 ed R600, si introduce un nuovo stadio programmabile all’interno della pipeline grafica che sarà anch’esso usato per le operazioni di tessellation: i geometry shader e il tessellator sarà combinato con nuovi stadi acquisendo nuove potenzialità. Di questo e delle successive implementazioni fatte da ATi e nVIdia con le DX10.1 e le DX11 parleremo nella prossima puntata in cui faremo anche considerazioni di carattere prestazionale sull’uso del tessellator.








