La scorsa settimana ci eravamo fermati all’anno 2003, anno in cui si registrano un paio di eventi degni di nota: le DX9, con l’adozione di un linguaggio ad alto livello, ribattezzato HLSL (high level shader language) e destinato a sostituire l’assembly, promettono di semplificare la vita ai coder e di spianare, finalmente, la strada alla tanto attesa rivoluzione della grafica 3D; per la prima volta, dai tempi delle Riva TnT2, nVidia si trova ad inseguire, sul piano prestazionale, per un tempo piuttosto lungo. Già con R200 ATi aveva effettuato il sorpasso ai danni di NV20 ma, dopo poco tempo, nVidia, con NV25 aveva rimesso le cose a posto.
Questa volta, la serie derivata da NV30, nelle sue incarnazioni top di gamma, riesce a difendersi egregiamente in DX8 ma le prestazioni crollano miseramente, per i problemi elencati la scorsa settimana, quando si tentava di far partire applicazioni con path DX9. Tanto che ID Software, con Doom 3, decise di ricorrere ai calcoli in floating point solo lo stretto indispensabile, mentre Valve creò una apposita patch DX8 per le VGA con chip Geforce per Half LIfe 2.
Anche questa volta, però, nVidia era tutt’altro che fuori gioco e se NV30 sembrava un chip che strizzava l’occhio alla precedente generazione di cui conservava, a livello architetturale, troppi elementi (stesso livello di parallelismo, scarsa funzionalità delle unità di tipo fp, presenza di unità di tipo fixed function e di alu di tipo INT, ecc), il chip presentato a maggio del 2004 col nome di NV40 appare, invece, chiaramente votato alle nuove API, pur condividendo con NV30 alcuni dettagli architetturali.
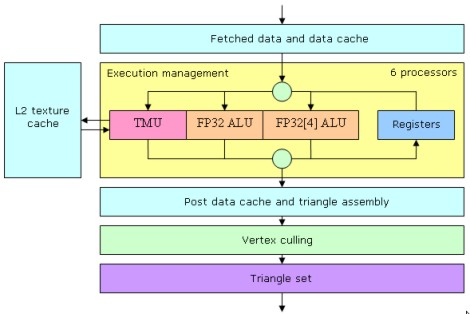
In primo luogo, NV40 ha un bus verso la memoria a 256 e architettura interna a 512 bit; inoltre, con NV40 è finalmente risolto il problema dell’insufficiente capienza dei registri temporanei; NV40 presenta 16 pipeline di rendering, ciascuna dotata di una tmu (adottando la filosofia che si era rivelata vincente in R300). Ma le analogie con R300 non sono finite: le 6 vertex unit (il doppio rispetto alla serie precedente) presentano, a fianco all’unità di tipo vect4 una unità scalare fp32, come si era visto su R300 e come mostra la successiva immagine
Come si vede dalla figura, la vertex unit di NV40 sono in grado di operare su un vettore completo con la alu fp32(4) e su un dato scalare, in parallelo, con la fp32; inoltre sono in condizione di effettuare operazioni di vertex texturing con una tmu in grado di accedere direttamente alla texture cache L2 di secondo livello. Quello che la figura non dice è che anche su NV40, al pari di NV30, sono ancora presenti unità di tipo T&L fixed function che nVidia abbandonerà, di fatto, solo con G80.
Con le DX9, si fissa a 16 il numero massimo di valori, da 128 bit ciascuno, in floating point, in input e output per le operazioni di vertex shading; questo limite permane anche nelle DX10 ed è innalzato a 32 con le DX10.1 e le DX11. Come NV30, anche NV40 è in grado di fare vertex texturing e, inoltre si avvale della funzione nota come Geometry Instancing
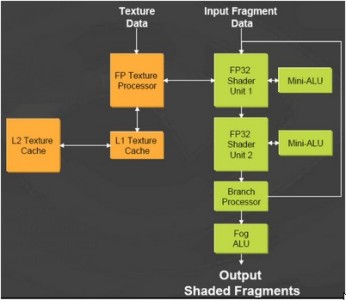
La vera rivoluzione, però, si ha a livello di pixel shader; contrariamente a quanto visto con NV3x, NV40 ha un numero e una capienza dei registri temporanei più che adeguata, un gran numero di registri constanti e, contrariamente a quanto visto per il suo predecessore, solo unità di calcolo di tipo floating point. Per l’esattezza, la pipeline di NV40 presenta l’architettura riportata in figura
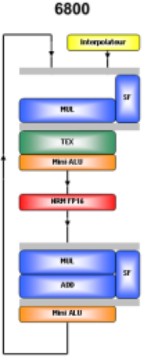
in cui sono presenti due alu, la prima delle quali è una MUL e la seconda una MADD (MUL + ADD), entrambe di tipo vect4, seguite, ciascuna, da una minialu e affiancata da una SFU (special function unit). La prima alu può eseguire una normalizzazione for free ma solo a fp16.
Anche in NV40, come nel successivo G70, la dipendenza della prima delle due alu dalle operazioni di texturing continua a rimanere; il diagramma va letto in questo senso: la prima alu può eseguira una MUL o un accesso a texture, oppure una delle operazioni tipiche di una SFU (radice quadrata, funzioni trigonometriche, ecc). La seconda alu può eseguire una MADD o una special function ops.
L’aver sacrificato una MUL sull’altare della dipendenza dalle operazioni di texturing ha permesso a nVidia di “svincolare” la seconda alu, quella in grado di eseguire una MADD, dalle stesse, trasformandola, di fatto, nella alu principale, anche perchè le MADD sono le operazioni più comuni. Le due minialu sono di tipo scalare e replicano la funzione della alu principale che le precede: la prima è quindi una MUL e la seconda una MADD, entrambe di tipo fp32.
In totale, ogni pipeline di NV40 può eseguire, a fp16, fino a 22 flops che calano ad un massimo di 15 a fp32 (una normalizzazione su un vettore completo equivale a 7 flops) e scendono ulteriormente a 11 in presenza di accessi a texture (si perde la MUL della prima alu).
Le alu, inoltre, operano in modalità co-issue, come quelle di R300 ma, rispetto a queste ultime, presentano una maggiore flessibilità, in quanto se quelle del chip ATi erano progettate in modo da eseguire calcoli su un vettore a 3 componenti e su uno scalare e, quindi, le configurazioni possibili erano 3+1 (RGB + A), 2+1 (due dei tre canali RGB e il canale alpha) e 1+1 (un canale RGB e alpha), le alu di NV40 possono operare anche in modalità 2+2 (RG+BA) ossia su due istruzioni indipendenti ciascuna relativa a due delle componenti di un vettore completo.
Inoltre, le alu di NV40 possono lavorare anche in modalità dual issue, ossia le due istruzioni indipendenti possono essere eseguite anche da differenti parti della pipeline di rendering, rendendo l’elaborazione ancora più flessibile in quanto non legata ad una singola alu.
Quindi, ricapitolanndo, NV40 supera molti dei limiti di NV30 (bus verso la ram e architettura interna raddoppiati, livello di parallelismo quadruplicato, abbondanza di registri interni, abbandono delle alu di tipo INT nelle pixel pipeline) e ne minimizza l’impatto di altri (tra tutti la dipendenza delle operazioni matematiche della prima alu dalle operazioni di texturing).
Altro miglioramento, rispetto ad NV3x, riguarda l’implementazione del MSAA che, finalmente, fa uso di pattern di tipo Rotated Grid; appare, invece, aver fatto un passo indietro l’implementazione del filtro anisotropico, rispetto all’ottimo esempio fornito da NV3x.
NV40 si fregia di essere DX9 shader model 3.0 full compliant, mentre, al contrario, R3x0 era compatibile con lo SM2.0a. Una delle caratteristiche di questa compatibilità è la possibilità di fare MRT (multi render target) sul color buffer. In particolare, NV40, come il suo successore, possono inizializzare fino a 4 differenti color buffer con la condizione che i quattro buffer abbiano lo stesso formato e le medesime dimensioni.
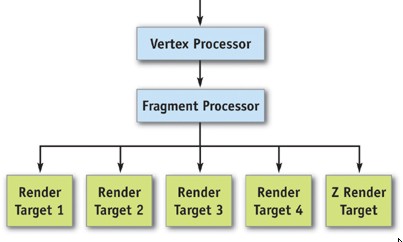
Il MRT è utile ogni qual volta è necessario salvare i dati su più locazioni di memoria, sia che si tratti degli stessi dati, sia che si tratti di dati differenti, purché conservino lo stesso formato (vedremo che dopo le DX10 è possibile utilizzare anche formati differenti e si può fare MRT anche sullo z-buffer).
Nella figura si notano i 4 color buffer e lo z-buffer. L’hardware DX9, come pure l’hardware DX10, è in grado di fare MRT sul color buffer ma non sullo z-buffer. Questo è un elemento importante di cui tener conto quando si parlerà di applicazione del MSAA con engine che fanno deferred rendering, per capire il perchè, in particolare, con HW DX9 è impossibile avere il MSAA box filter.
Le ROp’s, al pari di quelle di NV30, sono in grado di raddoppiare il pixel fillrate in presenza di soli valori contenuti nello z-buffer; nella figura sottostante, è evidenziato lo schema delle ROP’s dei chip nVidia delle serie NV3x, NV4x e G7x
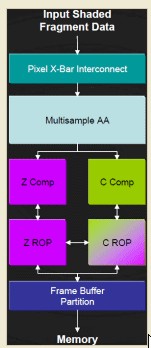
Come non si vede dalla figura, il motivo per cui i chip nVidia raddoppiano l’output in presenza dei cosiddetti “zixel” (only z value pixel) risiede nel fatto che i circuiti a sinistra della figura, ossia il Z compare e il Z ROP sono replicati anche dall’altra parte. Per cui i punti di spilling dei dati relativi allo z-buffer sono raddoppiati rispetto a ROP’s “tradizionali” che hanno un ramo che si occupa di color ed uno che si occupa di z ops.
Con queste migliorie e innovazioni, il divario prestazionale in DX9 tra NV40 e i suoi predecessori è abissale e il chip nVidia compete ad armi pari con la controparte ATi, rappresentato da R420, una sorta di R3x0 X2 a cui è stato aumentato il numero dei registri interni ed è stata aggiunta qualche funzionalità che lo renda compatibile con lo SM2.0b delle DX9.
Se, però, dal punto di vista prestazionale i due chip si equivalgono con, forse, una leggera prevalenza, nel complesso, di R420 con i titoli più vecchi, dal punto di vista tecnologico nVidia è, stavolta, notevolmente in vantaggio e questo vantaggio risulta evidente con l’utilizzo dei titoli più nuovi che fanno uso di feature non presenti sul chip canadese.
A questo punto, è ATi a trovarsi a dover di nuovo inseguire. Così, mentre il successore di NV40, denominato G70 – il chip da cui si ricaverà anche RSX, il chip grafico della Playstation 3 – è solo una mera evoluzione del precedente prodotto, come mostrano le sottostanti figure, relative alla singola alu del pixel shader core di G70 appunto
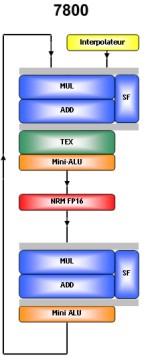
da cui si vede come alla MUL della prima alu si sia sostituita una MADD che porta il numero massimo delle flops teoriche a fp16 a 27, R5x0, successore di R4x0, con quest’ultimo condividerà solo l’architettura della singola alu che resta sempre di tipo co-issue 3+1 e delle unità di vertex shading, per altro uguali a quelle di nVidia con la sola eccezione dell’assenza, nei chip ATi della TMU interna, che li rende incapaci di fare operazioni di vertex texturing nella maniera prevista dalle DX9.
G70 ha 8 unità di vertex shading identiche a quelle di NV40, 24 pixel pipeline del tipo di quelle mostrate nelle due precedenti figure. Le ROP’s di NV40, come quelle di G70 e quelle di NV30, sono in grado di raddoppiare l’output quando si renderizzano i soli valori dello z-buffer.
La perdita del vantaggio tecnologico e prestazionale accumulato da ATi con R300, se da un lato ha permesso a nVidia di rimettersi in corsa, dall’altro è stata un sacrificio necessario; con NV30, infatti, nVidia aveva accumulato un vantaggio in termini di processo produttivo che ATi ha potuto recuperare proprio con la generazione di NV40 ed R420, mentre con la successiva generazione, quella che ha visto come protagonisti G7x ed R5x0, i canadesi sono riusciti addirittura a portarsi in vantaggio adottando uno shrink ottico dei 90 nm, quello a 80 nm, che ha permesso una più agevole transizione verso i 65 prima e i 55 nm in seguito, vantaggio che ATi tutt’ora conserva e che le ha permesso di pianificare con maggior calma il lancio e la commercializzazione dei chip DX10. 1 e DX11.
Di questo ed altro si parlerà, però, in seguito.







