Come anticipato la scorsa settimana, oggi ho intenzione di parlare, in breve, di una società che, pur non essendo tra quelle “sparite” dall’universo informatico, dopo aver vissuto stagioni di gloria si trova, da alcuni anni, relegata, quasi esclusivamente, in una nicchia un po’ particolare, ovvero quella delle applicazioni multimonitor. Questo in virtù dell’affinamento della tecnologia dualhead introdotta, per la prima volta, nel corso del 2000, sulla G400, lanciata nel settembre 1999. Per i pochi che non l’avessero ancora capito, sto parlando di matrox, società molto attiva nel portare l’intrattenimento multimediale nel mondo dell’home computing.
Non è mia intenzione ripercorrere la storia di questo glorioso marchio ma di focalizzare l’attenzione su alcuni modelli e, in particolare, quelli prodotti nel periodo di transizione tra l’era del 2D e quella del 3D. Anzi, per la precisione, su alcune caratteristiche architetturali di questi modelli, per certi versi, piuttosto peculiari o innovative.
Non credo sia un mistero per qualcuno il fatto che, per anni, matrox è stata sinonimo di qualità e di elevate prestazioni in 2D nel mondo consumer, anche se, nelle scorse settimane, abbiamo visto che altri marchi, non altrettanto noti al grande pubblico (ad esempio Chromatic Research, Tseng Labs o Number Nine, tanto per fare alcuni nomi) non avevano nulla da invidiare sia in qualità sia come accelerazione 2D alle famose millennium e mystique di matrox.
Ho ancora vivo il ricordo di alcuni miei amici e di come “sbavavano” davanti alle specifiche di ogni nuova vga che usciva a marchio matrox, confrontandole con quelle delle Trident o delle S3 Trio presenti sui loro pc. C’è da dire che, in effetti, matrox è sempre stata molto attenta alla qualità d’immagine, curando in maniera quasi maniacale la componentistica, delle sezioni di alimentazione e di output delle loro VGA e il layout del pcb (matrox progetta e produce in proprio le vga).
C’è, però, da ricordare che, come molti altri, anche matrox è stata, per certi versi, spiazzata dal passaggio dal 2D only al 2D/3D che ha portato, nel giro di pochi anni, ad avere l’accelerazione 3D come aspetto predominante nella progettazione di una gpu (si pensi che, ad esempio, la serie HD4xx0 di AMD non ha neppure un blocco dedicato al 2D che è gestito tramite lo shader core che integra funzionalità necessarie all’accelerazione dei flussi audio e video come le operazioni di integer bitshift). Non è un caso che il primo acceleratore 3D (3D only, sul modello delle Voodoo 1 e 2) uscito a marchio matrox, ovvero l’M3D, montava un chip della serie PCX2 di PowerVR.
Da quanto detto in precedenza, ai più attenti non sarà sfuggito il fatto che protagonisti di questo breve articolo saranno i chip prodotti a partire dal 1998, il primo dei quali è quello noto come MGA G200 (abbreviato oon G200). Questa doveva rappresentare la risposta di matrox agli acceleratori grafici della concorrenza e, in particolare, secondo l’intento di matrox, avrebbe dovuto competere con i chip della serie Riva 128 e con le Voodoo di 3dfx.
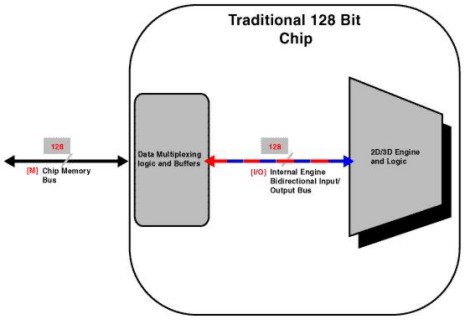
La G200 presentava alcune soluzioni interessanti a partire dal, cosiddetto, dual bus . Per capire di che si tratta, niente di meglio di qualche immagine. In basso un’architettura a 128, del tipo, per intenderci, di quelle di chip come il Riva 128 o il Riva TnT
Come si può vedere, sia il bus esterno che quello interno sono bidirezionali ma consentono il transito dei dati in una sola direzione per volta (all’epoca non esistevano ancora architetture di tipo crossbar) .
Al contrario, nella G200, l’architettura dei due bus si può schematizzare come segue
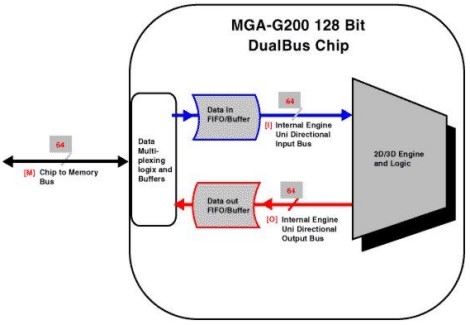
Il memory controller presenta un bus a soli 64 bit mentre l’architettura interna del chip ne ha due da 64 bit, ciascuno dei quali permette il transito dei dati in una sola direzione.
E’ un po’ come paragonare una strada a carreggiata unica con 4 corsie su cui la circolazione è a senzo unico alternato e una strada divisa in due carreggiate da due corsie ciascuna.
Un’altra caratteristica interessante dell’architettura di G200 riguarda le testure unit.
Prima di introdurre il discorso sulla capacità di texturing di un chip è, forse, opportuno spendere qualche parola sul fillrate o, meglio, sui due tipi di fillrate a cui si fa riferimento quando si parla di GPU: il pixel e il texel fillrate. Il primo è la capacità di un chip di “scrivere” i pixel nel frame buffer e, poichè le unità preposte a tale operazione sono le ROP’s (raster operation pipeline) o le RBE (render back end) che dir si voglia (entrambi i termini servono a definire lo stesso tipo di unità) il pixel fillrate è determinato dalla capacità di output di queste unità e si misura moltiplicando il numero di pixel scritti in un singolo ciclo (che non può mai essere superiore al numero di ROP’s, poichè, al massimo, una unità potrà elaborare un pixel in un ciclo), per la frequenza di funzionamento del chip o delle RBE qualora queste operino a frequenza differente dal resto del chip (caso non così raro). Ad esempio, RV770 ha 16 ROP’s e in caso di non applicazione dei filtri è in grado di elaborare, in teoria, 16 pixel per ciclo che restano ancora 16 con MSAA 4x e scendono a 8 con MSAA 8x; per ottenere il pixel fillrate teorico basta prendere questi numeri e moltiplicarli per la frequenza del chip. Il texel fillrate, invece, è funzione del numero di TMU, dell’impatto che l’applicazione dei relativi filtri (bilineare, trilineare, anisotropico) hanno sulla capacità di elaborazione delle TMU e, ancora, della loro frequenza di funzionamento.
Chiusa questa parentesi, mettiamo a confronto l’architettura della pipeline del G200 con quella, ad esempio, del Riva 128, con la prima delle due più a sinistra
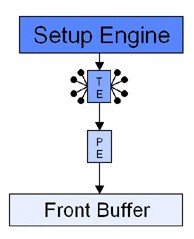
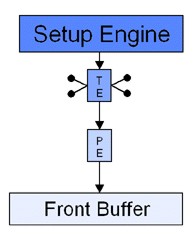
Come si vede, entrambe hanno una sola ROP’s e una sola TMU (indicata con TE in figura), la differenza sta nella capacità del G200 di elaborare 8 texel per ciclo contro i 4 del Riva 128, permettendo al primo di avere filtraggio trilineare “for free” mentre il secondo può beneficiare solo di filtraggio bilineare “gratuito”. Questo perchè il bilinear si ottiene interpolando linearmente una coppia di texel, mentre per il trilinear si deve ricorrere all’interpolazione lineare dei valori ottenuti da due precedenti filtraggi bilineari (si ottiene, quindi, attraverso 3 operazioni di interpolazione lineare che coinvolgono 4 texel). Ovviamente, il G200 presentava anche altre caratteristiche interessanti, come lo z-buffer a 32 bit e i 32 bit di precisione interna di calcolo.
Nel complesso un chip interessante ma afflitto da un problema non da poco: i driver OpenGL, a lungo latitanti in un primo momento e, successivamente, immaturi al punto da non permettere al G200 di eguagliare con quelle API le prestazioni sfoderate con le D3D. Inoltre nel giro di pochi mesi, si trovò a fare i conti con i nuovi nati di casa nVidia e S3, il Riva TnT (il primo chip di tipo consumer con doppia pipeline di rendering) ed il Savage 3D, che fornivano prestazioni mediamente superiori, soprattutto in OpenGL, oltre che con il Voodoo Banshee.
Di considerevole c’è che matrox ha fatto il suo ingresso nel mondo dei chip 2D/3D, per di più con un prodotto che presenta alcune soluzioni tecniche interessanti.
La generazione successiva fa segnare, con ogni probabilità, il punto più alto mai toccato da matrox nella corsa alle prestazioni 3D. Il suo G400, nella versione Max, non solo risulta competitivo nei confronti della concorrenza ma, spesso, quando si fa uso dei 32 bit e, soprattutto, in D3D, risulta superiore alla TnT2 Ultra e si avvicina alla Geforce 256 nella versione con ram SDR (grazie anche al fatto che quest’ultima, all’aumentare della risoluzione, risulta castrata dalla esigua bandwidth).
Il G400 ripropone le stesse soluzioni tecniche viste sul G200, ossia: dual bus ma, questa volta con interfaccia verso le ram a 128 bit e architettura interna composta da 2 bus da 128 bit ciascuno e VCQ2. In più, rispetto al G200, ha la doppia pipeline di rendering e una delle feature più pubblicizzate del momento: l’EMBM (environment mapped bump mapping), ideata dai Bitboys e “licenziata” a matrox ed altre, tra cui ATi e nVidia, introdotta nelle specifiche delle DX6 ma non supportata da chip DX7, come le Geforce 256 e le Geforce 2. L’EMBM prometteva (già da allora) mirabolanti effetti realistici come mostra l’immagine tratta dal gioco Expendable,
senza EMBM

e con EMBM

Purtroppo l’EMBM non fu l’asso nella manica di matrox, in quanto lo scarso supporto da parte degli sviluppatori produsse un numero esiguo di titoli che lo implementavano.
Sul piano architetturale, matrox aveva conservato il dual bus che si era rivelato vincente ma aveva anche rimosso il collo di bottiglia del G200, ovvero il bus di soli 64 bit del memory controller; questo mentre i rivali non avevano introdotto particolari novità (ad esempio, il Riva TnT non era altro che un Riva 128 con doppia pipeline e il TnT2 un TnT con frequenze più elevate). Quindi, mentre matrox poteva contare su un’architettura superiore nVidia si giovava di driver migliori e di frequenze di funzionamento più alte.
L’avvento delle cosiddette GPU, dotate di motore geometrico, fa segnare il passo a matrox che non ha le risorse economiche e umane per competere ad armi pari con ATi e nVidia. Salta a piè pari, quindi, la prima generazione, quella delle DX7, limitandosi ad affinare la tecnologia multimonitor con chip cloni di quello che equipaggia la G400, per fare un estremo tentativo di rientrare in corsa con la successiva. Con l’introduzione delle DX8 prima e, successivamente, delle DX9, matrox presenta, infatti, la Parhelia, il cui chip riprende l’architettura dual bus, questa volta facendo uso di un bus esterno e di due interni, tutti da 256 bit.
In basso, lo schema architetturale della matrox Parhelia
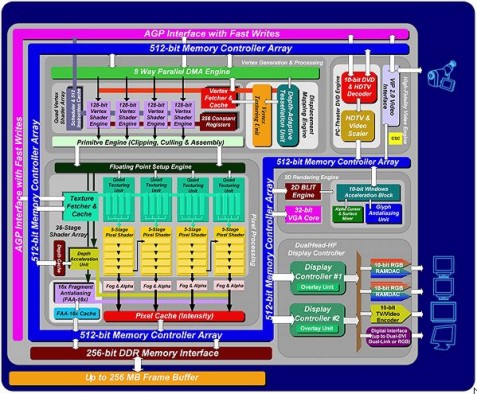
Dalla figura si vede chiaramente l’interfaccia verso la memoria, da 256 bit, e quella verso l’interno del chip (in blu), da 512 bit di tipo dual bus. Si notano anche altre cose, tra cui le 4 pixel pipeline dotate, ciascuna, di 4 TMU e le 4 vertex pipeline. La Parhelia risulta un ibrido, capace di supportare lo SM2.0 per le operazioni geometriche con la possibilità di fare displacement mapping tramite n-patches (come R200) e, addirittura, di eseguire operazioni di vertex texturing (previste dallo SM3.0) e ferma allo SM1.3 per le pixel pipeline (R200 supporta lo SM1.4, tanto per fare un paragone). Inoltre, ciascuna delle 4 TMU presenti su ogni pipeline, è in grado di operare “solo” su 4 subsample per ciclo, al pari di quanto visto per il Riva 128, mentre le 2 TMU di ogni pipeline di NV2x o di R200, sono del tipo di quelle viste per la G200, ovvero capaci di operare su 8 subsample. Questo significa che solo applicando il bilinear filtering la Parhelia, riesce, di fatto, ad applicare 4 texel per pixel per ciclo, mentre con l’uso del trilinear o dell’anisotropic il suo vantaggio nei confronti di NV2x e di R200 si azzera.
Tra le feature interessanti della Parhelia, il doppio ramDAC con la possibilità di collegare due monitor indipendenti e fino a 3 (in questo caso con diverse limitazioni), l’output a 10 bit per ciascuno dei tre colori RGB e 2 bit per il canale alpha, con la modalità 10,10,10,2, un gran numero di tipologie di antialiasing, dal classico supersampling al 16x fragment antialiasing (FAA) che, grazie all’abbinamento con un algoritmo di edge detect, permette l’applicazione del filtro solo su quei pixel attraversati dal bordo di un poligono); matrox ha previsto anche un antialiasing per i caratteri del desktop, il glyph antialiasing che riduce le scalettature nei testi.
Internamente, il chip che equipaggia la Parhelia lavora a fp32 per i vertex shaders e INT8 per i pixel shaders e le ROP’s.
Nel complesso si tratta di un prodotto interessante, arrivato, però, con troppo ritardo e, di conseguenza, poco competitivo sia a livello prestazionale che tecnologico. Rappresenta anche l’ultimo tentativo di matrox di proporre qualcosa di competitivo nel panorama consumer. Dopo l’esperimento Parhelia, matrox si dedica solo allo sviluppo di soluzioni multimonitor sempre più raffinate (e costose) destinate a usi per lo più di tipo medico-scientifico.
Il motivo dell’abbandono della rincorsa alle prestazioni da parte di matrox è lo stesso che ha portato alla scomparsa o all’abbandono da parte di quasi tutti gli altri competitor che, non più tradi di una decina di anni fa, affollavano il panorama dei produttori o progettisti di chip grafici: l’enorme aumento della complessità dei chip e, di conseguenza, l’enorme aumento dei costi (R300, nel settembre 2002, aveva circa 110 milioni di transistor, RV870, a settembre 2009, ne ha oltre 2 miliardi). Questo ha portato ad una ferrea selezione che ha prodotto l’attuale situazione che vede, in pratica, tre soli protagonisti contendersi la ribalta. Ma ha portato anche a prodotti infinitamente più veloci, raffinati e innovativi.
Questa conclusione potrebbe essere l’introduzione dell’articolo della prossima settimana che potrebbe avere per oggetto qualcosa di più “recente”.







