
Avere a disposizione un prodotto incredibilmente innovativo, a dir poco rivoluzionario, dovrebbe essere motivo sufficiente per spalancargli le porte del mercato e, magari, dominarlo. In realtà la storia ci insegna che non sempre i prodotti più avanzati sono poi quelli che hanno fatto strada.
Un esempio su tutti è la GPU P10 di 3DLabs, per la quale la casa madre coniò addirittura il termine VPU (Visual Processing Unit) per enfatizzare le sue strabilianti capacità, ma che fu relegata poi al solo mercato professionale a causa della complessità del chip e delle difficoltà a ottenere driver ottimizzati in grado di sfruttarlo come si deve.
Il campo dei microprocessori, come al solito, non fa eccezione, e ci presenta nel lontano 1981 una CPU a 32 bit progettata nientemeno che da Intel e pensata per implementare in hardware funzionalità utili la programmazione a oggetti (OOP), che all’epoca faceva timidamente capolino cercando di farsi strada in un mondo dominato dal paradigma imperativo…
In realtà questo processore non era costituito da un singolo chip, ma l’architettura era talmente complessa per l’epoca che ne richiese la suddivisione in tre. Due di essi, chiamati GDP (General Data Processor), costituiscono la CPU vera e propria (il primo si occupa del fetch e della decodifica delle istruzioni, mentre il secondo della loro esecuzione) e insieme contengono circa 160mila transistor. Il terzo, chiamato IP (Interface Processor) e che si occupa dell’I/O, ne contiene 49mila.
Come potete immaginare, più di 200mila transistor sono una quantità impressionante e rendono bene l’idea della dimensione di questo progetto, che sovrasta praticamente tutte le soluzioni disponibili all’epoca ponendosi necessariamente su un mercato privilegiato, che è quello dei minicomputer e mainframe. Quindi totalmente fuori dal mondo consumer.
Tanti transistor equivalgono anche a tanta roba implementata. Di ciò sicuramente la più grossa fetta riguarda, come già detto, l’implementazione in hardware di funzionalità atte ad accelerare la programmazione orientata agli oggetti (ma non soltanto).
Questo paradigma permea tutta l’architettura della CPU, e lo si vede in ogni dettaglio. Basti pensare che qualunque elemento/struttura di sistema è costituito da oggetti: dallo stato del processore allo stack, dalle subroutine all’elenco dei processi.
Come un sistema a oggetti che si rispetti, esistono diversi tipi di oggetti predefiniti / di sistema, e altri personalizzabili se ne possono creare all’occorrenza. C’è, infatti, un completo type system, con tanto di manager per ogni tipo di oggetti che ne gestiscono l’accesso.
Ovviamente non esistono soltanto gli oggetti, e a livello di manipolazione di dati questo microprocessore offre pieno supporto per i classici tipi scalari: caratteri, interi a 16 e 32 bit, numeri in virgola mobile a 32, 64 e 80 bit, strutture, vettori e campi di bit.
Questo tipi di dati è comunque memorizzato all’interno di oggetti primitivi, chiamati generic object, che sono costituiti da segmenti di memoria aventi una ben definita struttura:
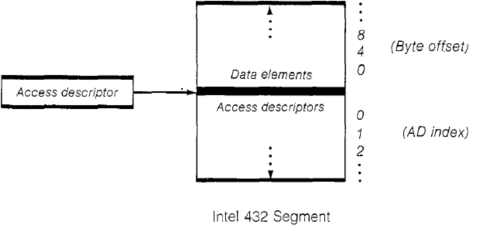
Come si può vedere, un segmento è diviso in due parti, chiamate rispettivamente data part e access part (che occupano al massimo 64KB ciascuna).
La prima, che si estende verso l’alto, contiene esclusivamente dati scalari. La seconda, che si estende verso il basso, contiene esclusivamente quelli che vengono chiamati access descriptor (AD) o, in gergo, capacità dell’oggetto (informazioni 32 bit tramite le quali si referenziano tutti gli oggetti presenti nel sistema).
Gli AD (che sono alla base di questa CPU) rappresentano anche il punto di collegamento con altri oggetti, visto che tutti i segmenti sono indirizzati tramite questo meccanismo. Considerato che anche le subroutine sono oggetti, si fa presto a parlare di metodi associati a un particolare oggetto.
Chi ha esperienza di design di compilatori di linguaggi OOP, oppure conosce i dettagli implementativi di basso livello del linguaggio di programmazione orientato agli oggetti che usa, sicuramente riconoscerà questo tipo di schema che separa i dati “grezzi” dalle informazioni “di servizio”.
Senza andare troppo nel dettaglio (ho preferito focalizzarmi sull’aspetto OOP del chip, altrimenti l’articolo sarebbe diventato chilometrico), altre caratteristiche (tutte implementate in hardware tramite particolari oggetti di sistema) di cui è dotato l‘iAPX 432 sono le seguenti:
- primitive di allocazione della memoria;
- garbage collector (di tipo mark & sweep);
- protezione della memoria;
- rigido e controllato accesso a qualunque risorsa (tramite access right e le già citate AD);
- accesso isolato a dati e AD (tramite apposite istruzioni che operano esclusivamente su uno dei due);
- capacità di multiprocessing (si possono realizzare sistemi con fino a 6 CPU collegate sullo stesso bus);
- scheduling degli oggetti process;
- messagebox per lo scambio di messaggi fra processi e/o processori.
Come si può vedere, si tratta di funzionalità che permettono di semplificare la scrittura dei sistemi operativi, oltre che migliorarne le prestazioni, grazie al supporto on-chip.
Singolare è anche l’ISA (Instruction Set Architecture), che è del tutto priva di registri. Infatti per le operazioni e memorizzare i risultati intermedi viene utilizzato lo stack (esattamente come avviene con molte macchine virtuali che, agendo in questo modo, sono chiamate appunto stack-based) oppure la memoria.
Può sembrare una grossa limitazione, ma dobbiamo anche considerare che, come dicevo in un precedente articolo, all’epoca le memorie erano più veloci dei microprocessori, per cui una scelta di questo tipo aveva senso.
E’ difficile da comprendere, invece, quella di codificare gli opcode delle istruzioni in termini di bit a lunghezza variabile. In pratica le istruzioni non occupano byte, ma bit (da 6 a più di 300), e possono essere posizionate a qualunque offset (di bit, ovviamente).
Se da una parte ciò consente di risparmiare spazio (codificando in maniera molto compatta gli opcode), dall’altra complica enormemente la loro decodifica, e riduce lo spazio a disposizione per i segmenti di codice (dove stanno le subroutine) a soli 8KB (perché viene utilizzato un offset a 16 bit per referenziare gli indirizzi del codice, che in termini di byte si traduce in 8KB di memoria indirizzabili).
Tra l’altro è singolare che si sia pensato a ottimizzare lo spazio per il codice quando i segment descriptor (strutture che racchiudono le informazioni fondamentali dei segmenti similmente alle più conosciute page directory entry), occupano ben 128 bit (16 byte).
A titolo di confronto, i segment descriptor (selector, per la precisione) di 80286 e 80386+ sono a 64 bit (8 byte). Le page directory entry per le architetture che utilizzano la paginazione sono a 32 bit per le ISA a 32 bit (4 byte), mentre per quelle a 64 bit sono a 64 bit (8 byte). E stiamo parlando di sistemi più recenti, non di roba del 1981…
E’ da soluzioni come queste, unite alle numerose e complesse funzionalità integrate (compreso un meccanismo di fault tolerance), che si può capire il perché del netto fallimento di questo microprocessore: era troppo lento.
Nonostante il notevole numero di transistor e le successive integrazioni di cache atte a ridurre i costi per l’accesso ai segmenti degli oggetti (similmente alle TLB delle PMMU), le prestazioni col codice tradizionale di quei tempi erano decisamente scarse, anche meno di 1/4 rispetto ad altri più economici e semplici chip concorrenti.
Il risultato è che l’iAPX 432 fu venduto in poche migliaia di esemplari, per lo più a università in cui la sperimentazione di nuovi sistemi operativi, linguaggi di programmazione, ecc. era (ed è) sempre molto fervida.
L’insuccesso di questa geniale (perché, specifiche alla mano, lo era) CPU dimostra che immettere un prodotto troppo innovativo (di OOP se ne parlava a malapena) senza che il mercato sia in grado di recepirlo (e, soprattutto, non bilanciando le innovazioni con le prestazioni) è una strada decisamente pericolosa.
Anche se una multinazionale come Intel certi buchi nell’acqua se li può permettere…







