
Having discussed the general advantages, and in particular code density and the number of instructions executed (topics covered in the previous article), let us take a look at the innovations that NEx64T brings compared to x86 and x64.
General-purpose / integer / scalar instructions
Let us start by saying that the architecture is mostly orthogonal, so that practically all instructions are structured in the same way (as we also saw in the second article), can use the same addressing modes, and any size can be specified for the data (from 8 to 64 bits: Byte, Word, Long, Quad).
The advantage in this case is that compilers are simpler to implement, as they do not have to take special cases into account and code generation is easier. This is even more important in the case where code must necessarily be written in assembly language, or using intrinsics, since it is the programmers (human beings!) who have to do this.
This means that instructions such as POPCNT, which on x86 / x64 can only handle data of certain sizes (16, 32, and 64 bits, specifically), can work, instead, with any size (so even 8 bits). Another example is ADCX, which on x86 / x64 only works with 32- and 64-bit data, while on NEx64T it can also do so with 8- and 16-bit data.
As can be guessed, a number of new instructions have also been introduced, which speed up the execution of fairly common tasks, which I will list briefly:
CCMPccandCTESTccto optimise the generation of flags in the evaluation of boolean conditions (more details in the appropriateAPXarticle);- generation of bit masks (all bits are either
1or0, depending on the condition tested or the comparison of two operands) or boolean flags (value0or1depending on the comparison of two operands); PUSH/POPof several registers on/from the stack, possibly adding space for local variables;- conditional jumping based on the content of a register or the comparison between two registers;
- calls or jumps to methods (using “compact” VMT tables);
- calls or jumps to function tables (“compact”. For switch/case instructions).
These are only a few instructions, but they can make a difference in terms of performance and/or memory space occupied (including data), several of which can be found in a similar way on other architectures (including L/S = Load/Store. The former RISCs).
Extending the instructions
Another peculiarity of the new architecture is that instructions (not all of them. e.g. not the “compressed” ones, which take up less space) can be extended to acquire new features. This is stuff we have already seen to some extent with x86 / x64, but which here undergoes a particular evolution that allows the instructions to be enriched.
A diagram allows a better understanding of what we are talking about (as well as presenting a new syntax for instructions):
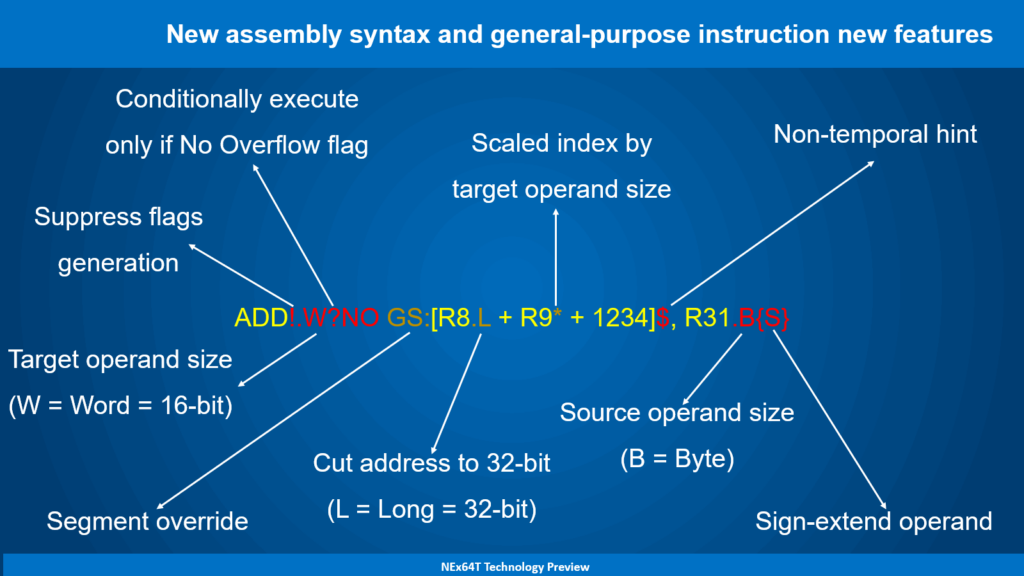
The instruction (ADD) and all its normal parts are highlighted in yellow. In orange, on the other hand, the following functionalities are highlighted, which are also present in x86 / x64 (with some slight differences for the last functionality):
- use of a different segment (
GS) to reference the memory, instead of the default one (DSorSS. The latter is used when the base register isSPorBP). On x86/x64, theGSprefix must be used. - truncation of an address from 64 to 32 bits (
.L), or from 32 to 16 bits. On x86 / x64 the prefix67(in hexadecimal) must be used; - use of index scaled according to operand size. On x86 / x64 the size is fixed and coincides with the size of the target operand, and the index is scaled by one of four selectable fixed values (1, 2, 4 or 8). On NEx64T, on the other hand, it is possible to scale the index solely by the size of the target operand (i.e. by a factor of 2, in this case).
So far, this is business as usual, since it is basically what is already possible with x86 / x64.
Things change with the new features, highlighted in red, which are exclusive to NEx64T:
- suppression of the generation of flags (
!) in instructions that generate them. Conversely, flags are forcibly generated in instructions that do not generate them. For example,MOV!would execute the normalMOV, but would set the flags by comparing the copied data with zero; - definition of the target data size (
.W). Normally this is already possible and is implicit with x86 / x64, but it takes on a different meaning when a size is also specified for the source operand (see below); - conditional execution of the instruction (
?NO), only when the overflow flag is not found to be set. The instruction, therefore, is not executed if the overflow flag is set (in this specific case. But you can select 15 of the 16 conditions available for x86 / x64); - data read and/or written by the instruction are not stored in any processor cache (
$). Which, therefore, are not “polluted” (taking away space from other data already stored) by data that it is not useful to keep; - Source data size definition (
.B). It is used in conjunction with the definition of the destination data size (see above) and the data extension mode (see below); - Selection of the extension mode of the source data with sign (
{S}) or with zero ({Z}. This is normally implied and does not need to be specified. It is reported here only for completeness). In this example, the least significant byte of registerR31is sign-extended and summed to the word (16 bits) referenced in memory.
These are, as can be seen, very common functionalities that require, in the absence of the extension mechanism made available by NEx64T, the execution of one or more instructions (for each specific functionality used/enabled) to emulate their operation, and in some cases even some support registers to calculate intermediate/temporary values.
This mechanism represents what, in my humble opinion, could be classified as the quintessence of CISC: being able to perform more “‘useful work” in a single instruction.
This is all to the benefit of the number of executed instructions (which is reduced, of course) and, often, also of code density (less space occupied due to the fact of executing fewer instructions), with consequent, beneficial effects in terms of performance and processor consumption.
Polymorphic instructions
Continuing in this vein, NEx64T sublimates the concept by introducing polymorphic instructions, which represent a further extension of what we might call “basic” instructions, which take on new “shapes”.
The idea is to abstract the operation of an instruction, thinking of it simply as an object that receives one or more input data, processes it in a certain way, and then delivers the final result. Where this data comes from and where the result ends up is neither relevant nor binding for the instruction, because the processor will take care of it: it only has to deal with doing the calculations it has been asked to do.
This generalisation of instructions has made it possible to mould more formats with which instructions are made available, as can be seen in the following table:

Still taking the famous ADD, we can see how this can be used in different shapes than the first, which is the only one available with x86 / x64. In fact, with this ISA it is only possible to specify two arguments, where the first always acts as both destination and first source; furthermore, one of the two must always be a register.
In contrast, the second format in the list above shows how it is possible to reference two elements in memory (thus using any addressing mode for each of them), mimicking one of the most famous representatives of the CISC macrofamily: Digital’s VAX.
The third is a common format in several L/S processors, where as many as three arguments can be specified for the instruction, although these must all be registers. This is because the format used here is the “compact” one (opcodes occupy 32-bits. Like most L/S).
This problem is already solved with the fourth format, which allows a location in memory to be referenced for the third argument (i.e. the second input source). The first and second must always be registers, however.
The fifth, sixth and seventh formats are, on the other hand, a generalisation of the fourth, in that they allow as many as two elements in memory to be referenced, while one must always be a register. In these cases, the three formats differ only on the position of the one register (i.e. which of the three arguments it must be).
The last format, finally, represents the generalisation of the concept of repeated instruction in x86 / x64, which with these processors was restricted to only a few, whereas NEx64T allows any “basic” instruction to be specified.
In this case, the operation is repeated a certain number of times (specified in the RCX register), and the three operands can freely be registers or memory locations (but only with a few usable addressing modes). This, however, will be discussed in more detail in a later article.
What has been illustrated for binary instructions (which take two arguments and return another as a result) also applies to unary instructions, which in this case also have the advantage of being able to have both operands (source and destination) in memory.
For example, the NOT instruction, which on x86 / x64 has only one argument used for both source and destination, can now also be used in this way:
NOT.L [RBX + RDX* + 1234], [RBP + RCX* + 5678]
where the 32 bits contained in [RBP + RCX* + 5678] are negated and the result stored in [RBX + RDX* + 1234].
I think it is clear that this new architecture allows for enormous flexibility as well as efficiency, since a single instruction in one of the above-mentioned formats allows even more than one to be replaced to emulate its operation, again benefiting performance (fewer instructions executed), code density (a single instruction replaces two or more), and power consumption.
With this we can say that NEx64T goes even further in the tradition of CISC, encoding much more “useful work” in a single instruction and recalling to a large extent the already mentioned VAX, which allowed, however, to better compact the space of complex instructions such as these, but paying the high price of a much more difficult and inefficient decoding (which is not the case with NEx64T, as we have already seen in one of the previous articles).
The comparison with Intel’s APX…
We have already talked about APX in a recent series of articles, which explored the innovations introduced by Intel with this new extension (which in reality, and as far as we have already covered, can be considered a new architecture).
APX also brings innovations, therefore, but they represent only a few minor additions compared to what was introduced by NEx64T. In fact, they are limited to only the following:
- new
CCMPccandCTESTccinstructions, and more generalCMOVccinstructions (without necessarily raising exceptions). Instead, NE64T allows any “basic” instruction to be executed conditionally (similar to someL/Sarchitectures. e.g. ARM); - new
PUSH/POPinstructions of only two registers (and no stack adjustment to reserve additional space); - suppression of the generation of flags only for some instructions and not for all those that generate them. Furthermore, it is not possible to “reverse” the process: to generate flags for instructions that do not;
- binary instructions that now use three arguments can and must only have one register for the destination. Ditto for unary instructions that have two arguments (the destination must only ever be a register).
These are good innovations, no doubt, but they are far more limited than what is offered by NEx64T, which in comparison to APX is a rich superset of its own.
Both new ISAs extend the number of general-purpose registers from 16 to 32, but APX has a steep price to pay: it has to resort to special prefixes that also greatly increase the size of the instructions, as we saw in the article on code density.
NEx64T, on the other hand, has an orthogonal structure and generally suffers no penalty in using any of the 32 registers, taking care that the registers are used appropriately (there are “short” instructions that operate only on precise subsets of them). This is particularly true if the ABI that has been defined is used.
…and with the old FPU x87
Lastly, we must also consider the very old x87 FPU which, although obsolete (it only has 8 dedicated registers), is still used as it has the not inconsiderable advantage of being able to work with floating-point numbers with extended precision (80 bits), while the other FPUs (apart from the glorious Motorola 68000 family, which works in a similar manner) provide at most double precision (64 bits).
In this case, it made no sense to extend this calculation unit further, as it is considered deprecated (the guidelines recommend using at least the SSE2 extension). Therefore, no further registers were added, although this was possible.
The only thing that would still have been useful would have been to give it the possibility of using it in a more modern and practical way, so that its instructions could access registers directly, instead of operating only as a stack-based machine.
Thus, and to give a practical example, it is no longer necessary to execute two instructions to load values onto the stack, and finally execute a third one which takes care of “consuming” the two values (which are at the top of the stack, precisely), actually performing the operation (of summing, for example), and finally depositing the result on the stack (also at the top).
NEx64T, on the other hand, allows everything to be executed in a single instruction if the operands are all directly addressable. So there is no problem if they are all in the FPU registers or at most two arguments in memory (and one register), similar to what we have already seen with polymorphic instructions (binary and unary).
The advantage is clearly performance-related, and that is generally the only advantage gained, since the new x87 instruction formats take up more space in memory: it is difficult to do better in terms of code density (the x87 FPU is really very compact!), but there is no doubt that it can be done far better in terms of performance (and, above all, without too many headaches for those who still have to work on it).
Conclusions
This concludes the general overview of the new architecture, limited to general-purpose instructions and the old FPU.
The next article will focus, instead, on the addressing modes made available, which bring a lot of meat to the fire and tidbits that considerably improve what can be done with memory-referencing instructions.
But… not only memory! NEx64T, in fact, goes far beyond what is allowed/coded by x86 and x64, to the benefit of code density, memory space occupied for data, and thus once again with positive effects on performance and consumption…







