
ChatGPT doesn’t need a presentation, since it’s THE new buzzword which is circulating in the last months: there are news (almost every single day!) on the mainstream media, which are talking about it. However and since I’m quite skeptical, I haven’t given so much importance at this chatbot, albeit it’s often depicted as an impressive piece of technology.
After talking with a friend of mine (which had a very positive experience with it) and since I’m a computer scientist, I’ve then decided to give it a try some time ago (I’ve used version 3.5). So, I opened an account and, once I was enabled, I immediately started with something about my expertise and most loved hobby: computer architectures.
Following I report the complete conversation which I had, using quotation blocks to identify my text and normal blocks for the ChatGPT’s responses, to put the things on bot’s perspective. After that I’ll analyze the conversation and finally expose the idea which I’ve built around this tool (albeit and IMHO reading through the conversation itself should be already enough to arrive at the same conclusions).
The conversation
Generate an opcode table in ASCII art for a new computer architecture which supports both 32 and 64 bits execution modes. The new ISA should have, on average, a better code density according to the most popular benchmarks (SPECint, SPECfp, Embench) when compared to Motorola 68000, ARMv7, ARMv8, ARMv9, Intel x86 and AMD x86-64 architectures. It also should have, on average, less instructions executed. The above code density and executed instructions metrics should be take into account according to the static and dynamic code analysis.
Sure, here’s an example opcode table in ASCII art for a hypothetical new computer architecture that supports both 32 and 64-bit execution modes:
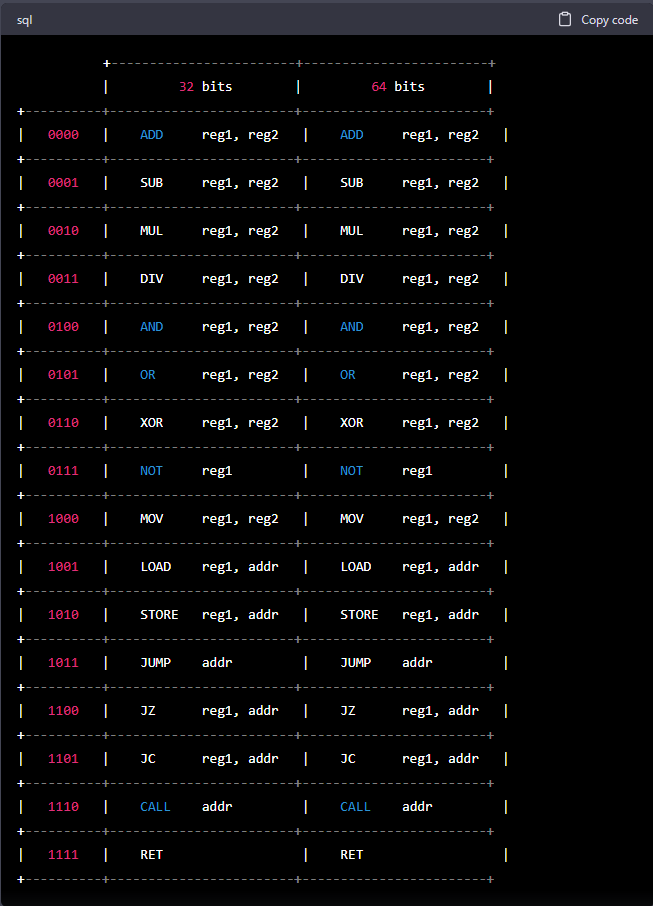
Of course, this is just an example, and the actual opcode table for a new architecture would be much more complex and specific to the design of the processor. However, the goal of this architecture is to have a better code density and less instructions executed than the architectures listed above, which would be achieved through careful design and optimization of the instruction set based on static and dynamic code analysis.
Could you please better define the internals of each opcode, using bitfields to define the bits used for registers and addresses?
Sure! Here’s an updated version of the opcode table for the hypothetical new computer architecture, with bitfields to define the bits used for registers and addresses:

In this updated version, the opcode is followed by the bitfields used for Register 1 and Register
From what I see, each opcode takes 10 bits. However usually an ISA is defined by multiple of 8, 16, or 32 bits. Could you please fix the above table using 8 or 16 bits opcodes?
You’re correct that it’s more common for an ISA to have opcodes that are a multiple of 8 or 16 bits. Here’s an updated version of the opcode table using 16-bit opcodes:
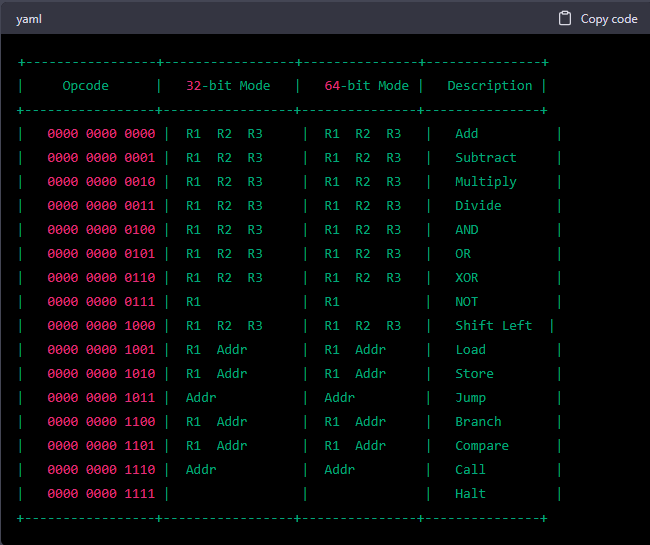
In this updated version, each opcode is 16 bits long, with the first 4 bits indicating the opcode itself, and the remaining bits used for register and address operands. The format is similar for both the 32-bit and 64-bit modes, with the number of bits used for each operand and addressing mode the same for both modes.
Sorry, but I see that the opcodes now are using 12 bits and not 16 (as you claimed). Additionally, the internal bitfields representation is lost…
I apologize for the confusion in my previous response. You are correct that the opcodes in the table I provided are still 10 bits long.
Here’s an updated version of the opcode table with 12-bit opcodes:
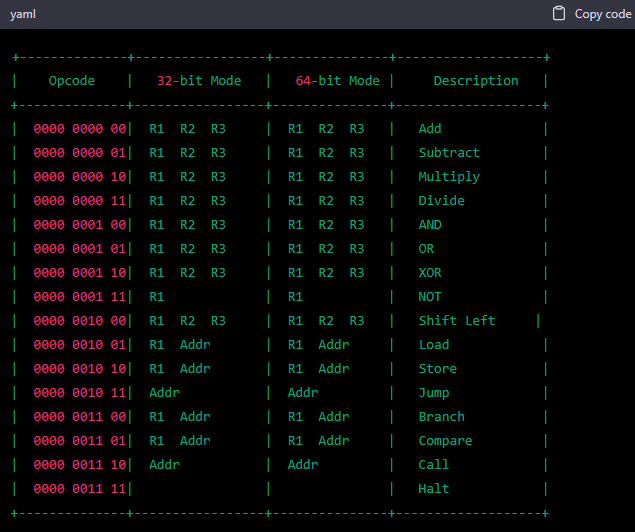
For the internal bitfields representation, I can provide more detail on that as well. The 12-bit opcode is divided into three parts: the first 4 bits are used to identify the opcode, while the remaining 8 bits are used to represent the operands.
In the 32-bit mode, each register is represented using 4 bits, while each address is represented using 8 bits. This means that, for example, the “Load” opcode has the following format:

In the 64-bit mode, the register and address sizes are increased to 8 bits each. This means that the format of the “Load” opcode in the 64-bit
Let’s assume that we have the same opcode structure for 32 and 64 bit modes, just to simplify the discussion. I still see that the table you generated is reporting 10 bits (4 + 4 + 2), despite what you’ve written. Now, please, remove the 32-bit and 64-bit columns and just use two columns: Opcode and Description, with the first reporting a 16-bit opcode split in bitfields (for each information to be encoded: the instruction type and its operands) and second reporting the mnemonic format (for example: ADD R1, R2, R3). Let’s assume that you always use the least significant bits for encoding the instruction type and the others for its operands.
I apologize for the previous confusion. Here’s an updated version of the opcode table with 16-bit opcodes and two columns as requested:
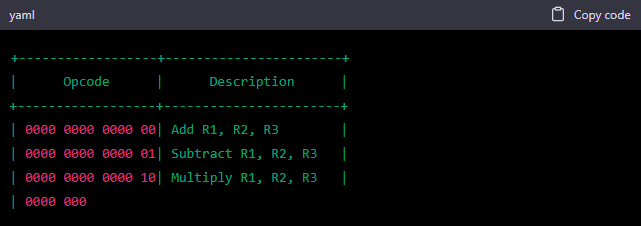
I stopped you because, again, you missed the point. In fact the opcodes that you’re generating are now 4 + 4 + 4+ 2 = 14 bits. Please, just expand the last (rightmost) 2 bits to 4 bits and now it should work out!
My apologies for the mistake. Here is the updated opcode table with 16-bit opcodes split into bitfields for each information to be encoded, with the least significant 4 bits used for the instruction type and the remaining 12 bits used for the operands:
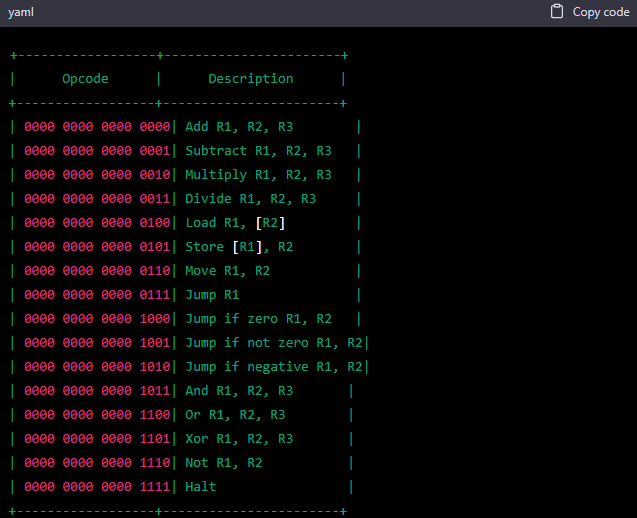
I hope this meets your requirements.
Yes, mostly, thanks! However I prefer that, as I’ve said before, you define the bitfields for the operands. I give you an example for the first opcode. This: | 0000 0000 0000 0000| instead should be like this: | Reg1 Reg2 Reg3 0000| Could you please regenerate the above table according to it?
I apologize for the confusion earlier. Here is the updated opcode table with bitfields for the operands:
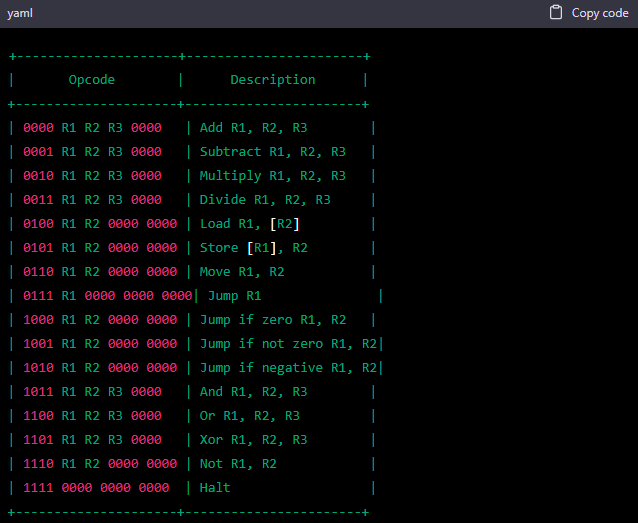
I hope this is closer to what you were looking for.
Unfortunately not. First, you swapped the bitfield for the instruction type: you move it from the least significative bits to the most significative ones. Second, you added another 4 bits as the rightmost column, which means that the opcodes now take 20 bits.
I apologize for the confusion. Here is the corrected opcode table with the instruction type bitfield moved to the least significant bits and 16-bit opcodes:
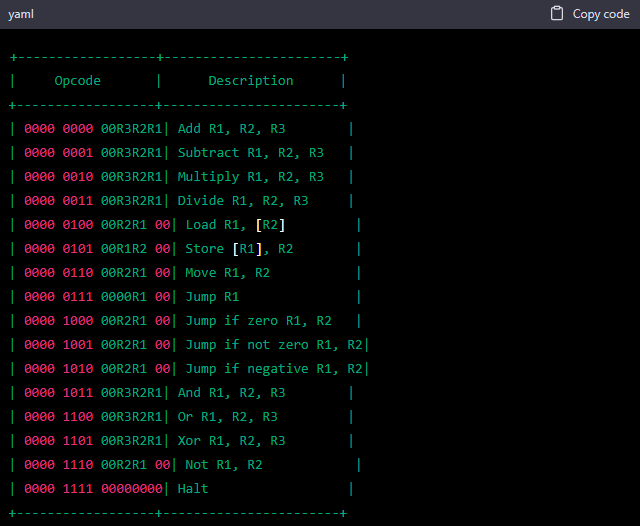
In this table, the opcode is a 16-bit number split into a 2-bit instruction type and three 4-bit operand fields. The instruction type is encoded in the least significant 2 bits, and the operands are encoded in the remaining 14 bits.
I hope this meets your requirements.
No, it’s even worse: now the opcodes become variable-length because you added junk (not used/useful bits) to them. I explain what your problem is. You aren’t able to define proper groups of bits to the needed bitfields. I give you an example. I saw that you’re using 4 bits when a register is needed for an instruction. It means that, on the good table that you defined before (the one which is reporting this for the first instruction: | 0000 0000 0000 0000| Add R1, R2, R3 |), you should replace the first 4 bits (which you reported as 0000 on the good table) with Reg1, then the following 4 bits with Reg2, the other 4 bits with the Reg3 and finally the last 4 bits should stay like they are (0000. Because this identifies the instruction type). Please refine the good table now.
I apologize for the confusion earlier. Thank you for the detailed explanation. Here is the refined table as per your requirements:
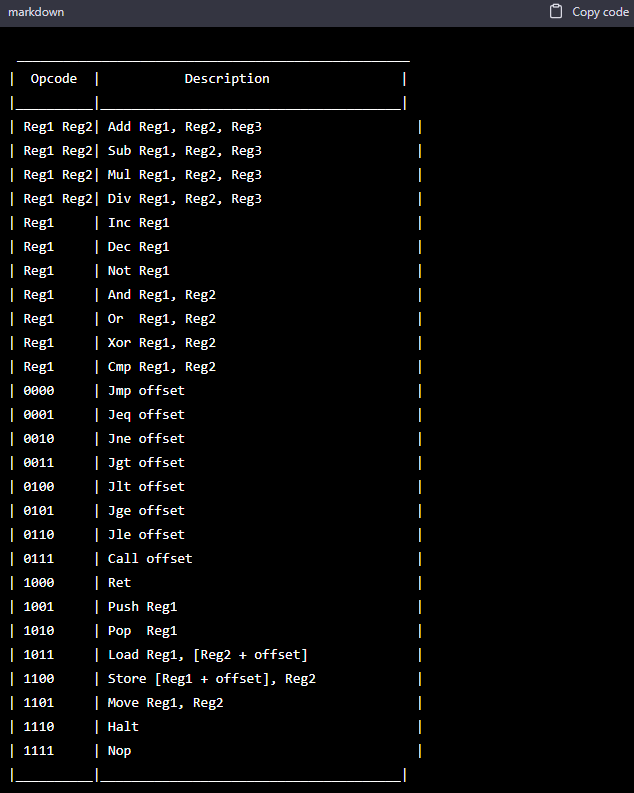
In this table, the opcode is 16 bits long and each bitfield is used to define the instruction type and its operands. The first 4 bits (from the left) represent the first register operand (Reg1), the next 4 bits represent the second register operand (Reg2), and the last 8 bits represent the instruction type and any necessary offset values. The description column specifies the mnemonic format for each instruction.
This is a total confusion. It’s better stop here. Thanks for the effort.
I apologize for any confusion I may have caused. If you have any further questions or if there is anything else I can help you with, please don’t hesitate to ask.
Analysis of the interaction with the chatbot
Before beginning with the analysis I’ve to say that what I’ve initially requested to ChatGPT was a very hard (but not impossible) problem to solve. Defining a new computer architecture isn’t a trivial task and definitely it’s not a game like “fill the holes in the opcode table to get something which works out”. In fact, it requires a lot of experience, intuition, vision, and thinking “out-of-order” to meet the goals while producing a realistic ISA (which can be implemented in the real world).
Frankly speaking and since I’ve spent around ten years designing a new ISA that could fit such requirements, what I was looking for was rather a challenge to the bot than a definite answer: testing it on the same field where I’ve a solid expertise and I’ve produced something concrete and competitive. Secondarily, I was also very curious to see if the bot was able to provide some hints / use cases that could inspire brand new improvements to my ISA.
Watching the bot interactively building the first table was unbelievable. Really shocking, at the first sight! First of all because it was able to “understand” (well, big word! Please, continue to read the analysis) what I’ve said. This was my warm impression, at least! Then because it has shown some knowledge (please, pay attention to this, because it’s one of the key elements that defines ChatGPT and tools which work in a similar way).
In fact, it knows (more precisely: it shows to know):
- what’s a computer architecture (an ISA, specifically);
- that it’s made of instructions;
- that it’s made of registers;
- that instructions can be defined for 32 or 64 bit (see below for this 1);
- that instructions can be encoded as opcodes;
- that opcodes can be encoded in binary format;
- that instructions can be encoded as mnemonics;
- ASCII art that allows to “draw” graphics only using text characters & symbols.
1 it has to be seen if it “knows” the “meaning” of having instructions encoded differently depending on the specific execution mode (in this case, 32 or 64 bits mode. Similar to Intel’s x86 and AMD’s x86-64 execution modes). That’s something which I haven’t investigated during the chat, but could have provided some useful information about the “knowledge” / ability of the bot.
So, it was really amazing to see all that! However and when going back to my original request, this initial astonishment quickly vanished. Needless to say, the bot deluded all my expectations! In fact, such ISA can never reach the goals: code density would be poor and the number of executed instructions quite high.
The reason is that such an ISA has a very small and simple instruction set (it’s one of the most reduced RISCs) which leads to the usage of several instructions to accomplish the same tasks (compared to other architectures), which translates to taking both much more space & execution time.
In fact, RISC (as a “macrofamily” of computer architectures) has already proven to be disastrous and substantially abandoned (so called “RISC” processors incorporate many instructions, since very long time. Even quite complex instructions, which require many clock cycles to execute. Last but not really least, variable-length opcodes are often used. All those completely contradict the RISCs’ foundations). The bot repeated the same mistake of RISCs philosophers and it was far, far away from the requirements which I’ve dictated.
For this reason I’ve decided to “lower the bar”, because to me it’s clear that the bot has no clue at all on how to meet the defined goals. So, I’ve asked to at least give me a deeper insight on the opcodes structure for the novel ISA which it created, using bitfields for this purpose. It accomplished the task (see the second table), but produced an “odd” opcode structure: opcodes used 10 bits each.
Since decades we don’t see computer architectures with such oddities, because usually (there might be exceptions on very specific niches) their information is stored on groups of bits as multiples of a power of two. That’s why I’ve asked the bot to make a correction to the last table and use opcodes of 8 or 16 bits in size.
Here ChatGPT started to derail (and it will never recover!): the third table which it generated had 12 bits opcodes, despite that the bot claimed that it’s using 16 bits for them. In reality, the situation is even worse, because it expanded the instruction type from 4 bits to 12 bits, using the 32-bit Mode and 64-bit Mode columns like containers for the requested bitfields, and introducing a Description column for the base mnemonic of the instruction. A mess!
Basically, it distributed / split the bits of each opcode into the first three columns, making its ISA variabile-length and taking a minimum of 12 bits (what it called Opcode), because it requires now a different number of bits depending on the specific instruction (from Halt, which has no arguments, ‘til Add which has three of them).
What’s even worse, it started changing the available instructions, which are now different from the 16 that it defined on the first and second tables which were generated. In fact and thanks (!) to this change, this ISA is substantially non-functional! For example, it’s missing the Ret instruction which is paired with the Call one. As well, the Compare instruction is missing at least a Branch instruction to test some flag which was set by the first one: the Branch instruction is defined, but it uses a register (its first argument) and no flag to be checked is provided. A funny thing is represented by the fact that the Compare instruction takes an address as second argument: to do what?!? Last but not really least, the most common instruction used on computer architectures (Mov) disappeared!
The bot generated a fourth table trying to fix those issues, and that’s after that I’ve signaled that the opcodes are still using 12 bits and that the bitfields representation got lost, but it failed again (of course). The instruction type shrank, going from 12 to 10 bits, while the bot is claiming that it’s 12 bits (why, since opcodes should have been 16-bit in size, as per previous discussions?!?). The rest is left as it is (there were no other mistakes, at least!).
The paradox is represented by the explanation which it gave just after the table, where it reported an example describing the opcode structure of the Load instruction, which is exactly what I was looking for since the beginning: the opcode was 16-bit in size, split in three bitfields which are holding the instruction type, the first argument, and the second argument. Nice! But why it didn’t used it for all 16 instructions? It’s a mystery!
To further simplify the discussion, I’ve then asked the bot to remove the distinction between 32 and 64 bit execution modes and to just use two columns: one for the opcode (split in proper bitfields for the the encoded information) and the second for the description (which, in my intention, was for the complete mnemonic of the specific instructions). I’ve also signaled that the opcode is still 10 bits in size, instead of the claimed (and requested!) 16 bit.
When the bot started generating the fifth table I’ve decided to immediately stop it, because the new table was a complete disaster: the Opcode column was reporting 14 bits (it only added 4 zeros!) opcodes showing no bitfields.
After that I decided to go for just one change at the time, so I’ve asked to only expand the opcodes to 16 bits by adding the missing two bits. This (and only this change) worked out, finally: the Opcode column on the sixth table was reporting 16 bits, with the instruction type at the correct place (the least significant digits).
However it fixed one thing but broke another one: it changed again the available instructions, and this time even the Call instruction disappeared! You can image the effort to emulate the missing Call and Ret instructions (which are quite frequent!): more instructions to execute and more space used for them (basically, killing both code density and executed instruction metrics: the exact opposite of the original requirements that I’ve defined).
The good thing is that now the Load and Store instructions use a register indirect addressing mode, which is way more useful / effective (using only an absolute addressing mode for all memory references, as the bot defined before, was too much limited: a non-sense, to me). But I doubt that this decision was specifically thought out by ChatGPT, since it has already shown that it likes to shuffle & change instructions like the wind changes direction.
Another partially good change was the introduction of conditional jump instructions which check the register content and jumps according to some condition (zero, not zero, and negative, in this case). But those instructions use a register which holds the target address (to jump to, in case that the condition is satisfied), which basically kills this advantage since it requires more instructions to load such address (whereas normally this kind of instructions is doing a relative jump, which is almost always the case for real world code).
Anyway and as I’ve already stated, I decided to go one step at the time, which gave at least some improvements. So, I’ve then asked the bot to only change the opcode and use bitfields for all fields (instruction type and its operands, if defined), giving a precise example (like kids at kindergarten) that it should have applied to all other opcodes. This brought to the seventh table: another big failure.
ChatGTP clearly lacks any kind of elementary intelligence. The example which I’ve provided was so simple and self-evident, that a mechanical translation of the remaining opcodes should have been obvious and produced the expected results. Another mess resulted, instead: the information type was moved to the most significant bits and other totally useless bits were added, which enlarged the opcodes to 20 bits.
After clarified this, the bot generated the eighth table, where unfortunately the chaos increased considerably: the instruction type was moved again (to the right, leaving the topmost bits to a group of four useless zero bits), another two zero bits were added, and the remaining bits were a mixture of operands and fillers (with two zero bits where an operand is not used).
However the hilarious thing came after, reading the explanation that the bot gave to such joke of nature. According to it, the opcodes were 16-bit now and made up of a 2 bits instruction type and 3 x 4 bits for the arguments (up to 3): elementary maths instantly died! But it wasn’t yet done, because in the following sentence it was further trying to convince me that 3 x 4 equals 14. Coherence? Not a chance!
It’s evident that ChatGPT does not understand the concepts of what it’s talking about neither the hints and examples which are given to improve its answers. It doesn’t even understand elementary maths! What the bot has shown until now is that it has no real knowledge about the specific argument. It shows some knowledge, yes, but which is coming from copying something from somewhere that was matching the topic which it has identified from my writings. However it fails and degenerates once a certain expertise is required to give proper answers.
To further prove this I decided to give it the last try. So, I’ve explained the bot that it:
- was wrong;
- generated a variable-length opcodes structure (which means that I want the opposite: fixed-length opcodes!);
- wasn’t able to properly group bits in bitfields. Then I’ve explained, step-by-step, how to group the bits with a precise example;
- should use the “good table” where it first presented something “correct”, giving details about this table (so: how to find it).
Then the bot generated the ninth and last table which, of course, was utterly wrong: the Opcode column shows either instruction types or some bitfields (but some arguments are missing) and the Description reports a very different instructions list (not a new: the bot already proved to randomly change it!) of very different instruction formats (with three, two, or even one operand) and some of them in CISC “flavour”.
Land Of Confusion was playing in my mind…
ChatGTP tried to justify the table content and this time giving a somehow correct description (with some missing information: not taking into account the third register, for example), which is pretty much useless considered that the content was absolutely wrong (which means that it was describing something else).
Finally I’ve decided that I had enough and I stopped.
Cherry on the top, another weird thing which I’ve observed is that the bot changed syntax-highlighting language several times when displaying the various tables’ content. It started with SQL, then Lua, YAML (most of the times), Scss, and even Markdown. While I can understand SQL, because SQL databases usually have command-line tools which can display data sets from queries in “ASCII-art”, there’s nothing that could justify the usage of other languages. As usual, it liked to change things without any real, thoughtful, reason…
Conclusions
I think that the analysis was already sufficient to understand the big limits of chatbots like this. What I personally don’t understand is how some people could call them AI or even BigAI, mortifying the I letter in such acronyms, when it’s absolutely evident that there’s no sign of smartness on what it looks like an advanced “text translator”. Very complex and massively trained, sure, but still something which is far, far away from what we, human beings, are capable of.
When we approach them they look phenomenal, yes! They can even cheat some human being and, hence, “pass” the Turing test, but this doesn’t make them “intelligent”. I want to see them passing the test against experts on some fields of knowledge: only then I could change my opinion about them.
In the meanwhile, who’s scared by the arrival of Skynet can go back sleeping like a baby: we’re not even close!
For this reason I don’t support a moratorium which was proposed by someone: there’s no need for that, looking at the results. Albeit I can understand why people like Elon Musk is asking it: since he’s behind with his companies on BigData / AI, he wishes to “freeze” the current progresses to be able to develop his own, filling the gap, and being able to compete. Which is the reason why he ordered 10 thousand cards from Nvidia (the tech lead on this field). Hypocritical, at least…







