In tutta la discussione sui meccanismi di branch prediction (e siamo ormai alla sesta puntata!) ho sempre lasciato intendere che si debba predire il bersaglio di salto, inteso come la singola istruzione puntata dal salto. L’ho fatto per semplificare il discorso, ma dato che il concetto alla base dei processori superscalari è quello di elaborare più istruzioni per ciclo di clock, è più corretto dire che il predittore deve fornire il prossimo fetch group, cioè le prossime N istruzioni che il processore dovrà eseguire.
Come avevo già discusso nel primo articolo, la cache (o meglio, un singolo banco) restituisce solitamente una singola linea per ogni accesso. Purtroppo, a causa dei salti, non tutte le istruzioni di quella linea potranno essere eseguite: ad esempio, se ci fosse un salto preso nella prima istruzione della linea, dall’intero gruppo di fetch riusciremmo ad estrarre una singola istruzioni utile (il salto). Per questo motivo aumentare la dimensione della cache line aiuta solo fino ad un certo punto, perchè la dimensione media del fetch group è limitata dal numero di salti presi nel programma.
Un paio di tecniche per risolvere questo problema sono il collapsing buffer, che permette di ottenere più cache line per ciclo di clock ed estrarre da esse le istruzioni utili, e la trace cache, che permette di costruire “tracce” on-the-fly in modo da far coincidere la successione logia delle istruzioni con la loro disposizione fisica.
Collapsing buffer
I meccanismi necessari per costruire questo sistema sono:
- un predittore (BTB, Branch Target Buffer) capace di predire più di un bersaglio per ciclo di clock (la prossima cache line e quella ancora dopo) e anche quali delle istruzioni di ogni linea sono effettivamente da eseguire
- una cache multi-banked capace di fornire più di una cache line per ciclo di clock
- della circuiteria per selezionare, allineare e compattare le istruzioni utili da ogni cache line
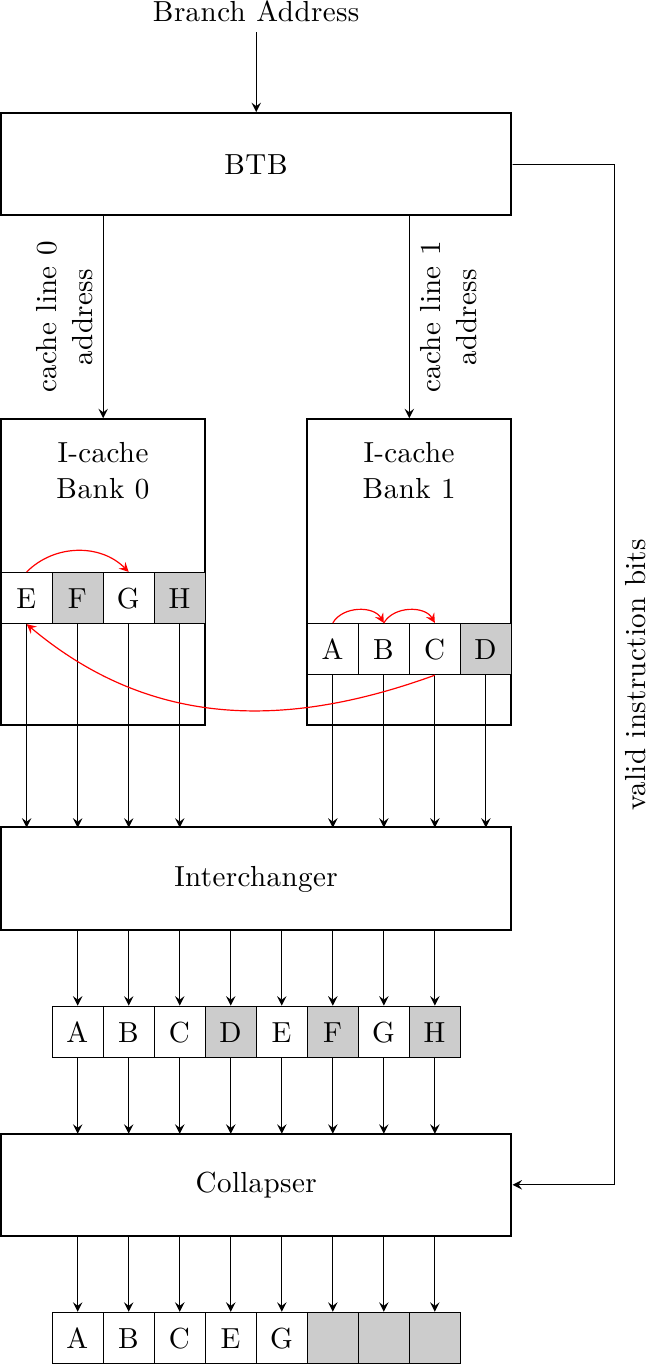
Dato che ogni banco della cache può fornire una cache line per ciclo di clock, se le linee predette dal BTB sono in banchi diversi la cache nel suo complesso può restituire più cache line per ciclo di clock. Facciamo un esempio dove la cache ha due banchi, ogni linea ha quattro istruzioni e il BTB ha predetto le due prossime linee nei due banchi, una per banco:
La prima linea, nella sequenza logica delle istruzioni, si trova nel secondo banco e la seconda linea nel primo; inoltre, la prima linea fornisce 3 istruzioni utili {A, B, C}, C è un salto ad E nell’altra linea ed E stesso è un salto intra-linea a G. Come primo passo, le due linee vengono passate alla logica di interscambio, che riallinea le cache line nella giusta sequenza nel caso siano invertite nelle cache (come nel nostro caso). A questo punto le istruzioni passano nel compattatore (che può essere realizzato con degli shifter) che prende in ingresso anche dei valid bit dal BTB (quindi predetti anch’essi!) che dicono quali istruzioni sono utilizzate e quali no (questi bit sono derivati dalla posizione dei salti e dai loro bersagli nelle cache line). Dopodichè le cinque istruzioni possono essere consegnate allo stadio successivo di decodifica.
Una cache capace di fornire una sola cache line per ciclo di clock avrebbe fornito solo tre istruzioni al primo ciclo e due al secondo ciclo, contro le cinque in un solo ciclo. La banda di fetch fornita da questo schema può essere molto superiore ed alimentare così macchine superscalari più larghe.
Val la pena notare che un singolo crossbar può assolvere la stessa funzione della logica di interscambio e compattazione, dato che può permutare gli ingressi in modo arbitrario:
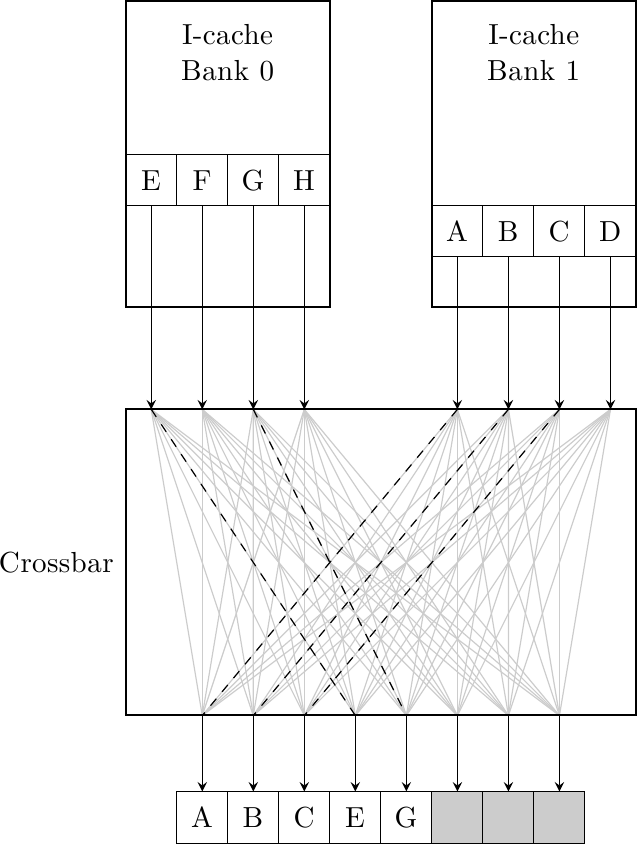
Da ultimo, bisogna sempre bilanciare la banda con la latenza: questo schema permette sì di avere una banda di fetch maggiore ma a scapito di una maggiore latenza nella consegna delle istruzioni allo stadio di decode dovuto alla logica di riordino. Questa latenza si manifesta sotto forma di stadi di pipeline addizionali nel front-end, che aumentano la penalità di branch misprediction. Queste due quantità vanno accuratamente bilanciate per ottimizzare le prestazioni.
Trace cache
Come visto per il collapsing buffer, il problema da risolvere è che la sequenza dinamica delle istruzioni (cioè l’ordine in cui vengono eseguite) non coincide con la sequenza fisica con cui esse sono disposte in memoria. Mentre il collapsing buffer cerca di fornire una sequenza più lunga di istruzioni successive tramite accessi multipli e riordino on-the-fly durante il fetch, la trace cache cerca di risolvere il problema creando delle “tracce”, cioè immagazzinando nella cache le istruzioni in ordine dinamico e non in ordine fisico.
Una traccia è quindi una sequenza dinamica di istruzioni:
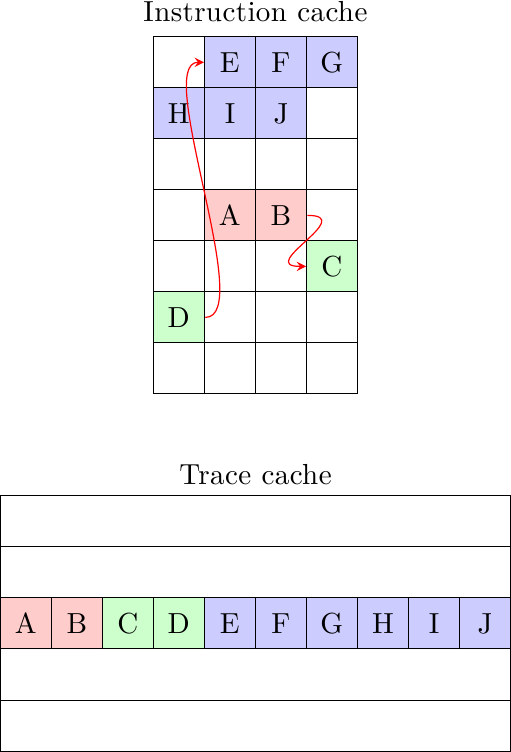
L’esempio mostra una sequenza di istruzioni di cui fare il fetch e la loro posizione nella cache istruzioni: l’istruzione B è un branch preso che punta a C; il blocco {C, D} è spezzato su 2 cache line diverse; D a sua volta è un branch preso che punta ad E, e il blocco di 6 istruzioni {E,..,J} non può che essere diviso su più linee, data la lunghezza. Un motore di fetch convezionale prenderebbe 5 cicli a caricare le 10 istruzioni, mentre il collapsing buffer ne richiederebbe minimo 3 (se le singole cache line si trovano in banchi alternati, in modo da poter caricare sempre 2 cache line per ciclo di clock). La trace cache invece potrebbe immagazzinare tutte e 10 le istruzioni in un’unica “traccia” contigua la prima volta che le istruzioni vengono incontrate e consegnarle tutte e 10 in un singolo colpo quando la stessa sequenza viene incontrata di nuovo.
Fondamentale per il funzionamento della trace cache è il meccanismo di costruzione delle tracce. Questo può avvenire in un paio di punti differenti della pipeline:
- alla testa della pipeline, durante il fetch: mentre le istruzioni vengono prelevate dalla cache convenzionale, un buffer immagazzina la sequenza dinamica di istruzioni; quando la sequenza è completa, il contenuto del buffer viene caricato nella trace cache e diventa una “traccia”
- alla fine della pipeline, durante il ritiro: quando le istruzioni vengono ritirate (in ordine) vengono caricate nel buffer di costruzione della traccia e il resto procede come nel caso precedente; questo sistema ha il vantaggio di non interferire coi normali meccanismi presenti nel front-end della pipeline, che deve essere il più compatto possibile
In entrambi i casi è necessario avere delle strategie per decidere quando definire una traccia “completa”: alcune di queste potrebbero essere la larghezza della trace cache (cioè il massimo numero di istruzioni in una linea della trace cache), o un limite al numero di salti nella traccia (più salti si attraversano speculativamente, più è alta la probabilità di sbagliare la predizione composita).
Una traccia non consiste solo di una sequenza di istruzioni, ma deve anche fornire un meccanismo per indicizzare e prelevare la traccia stessa: non è sufficiente fornire solo l’indirizzo della prima istruzione della traccia, perchè l’esecuzione potrebbe divergere a seconda della direzione dei salti che contiene.
Un modo può essere quello di immagazzinare, insieme alle istruzioni, gli indirizzi di tutte le prime istruzioni dei blocchi base contenuti nella traccia stessa e usare questo come tag durante il look-up: quello che succede durante il fetch è che il predittore fornisce predizioni multiple per tutti i prossimi blocchi base e i loro indirizzi vengono usati per accedere alla trace cache. È possibile avere anche dei match parziali: se il predittore predice che solo alcuni blocchi di una certa traccia verranno usati e altri no, la trace cache può restituire solo questi.
Un altro modo è quello di predire direttamente la traccia, cioè usare la traccia come unità base. Ogni traccia viene indicizzata tramite un ID unico che consiste nel Program Counter della prima istruzione e dalle direzioni di salto di tutti i branch contenuti nella traccia. Questo è il valore generato dal trace predictor, che sostituisce il classico branch predictor.
Ad ogni modo, è necessario fornire un qualche meccanismo di backup per quando il programma entra in una nuova sezione di codice e la trace cache non riesce a fornire alcuna traccia. Un meccanismo di predizione e fetch convenzionale (magari semplificato) è perfettamente adatto allo scopo.
La trace cache è famosa per essere stata usata nel Pentium 4. Questo non aveva alcuna cache convezionale di primo livello per le istruzioni e quindi le tracce dovevano essere costruite a partire dalla cache L2. Questo riduce la complessità del front-end ma aumenta la miss penalty della trace cache. Un’altra particolarità della trace cache del P4 è che non immagazzinava istruzioni x86, ma micro-istruzioni già decodificate: questo aumenta la dimensione della cache ma permette di saltare lo stadio di decode ogni volta che si prelevano istruzioni dalla trace cache, con risparmio di tempo ed energia.
Conclusioni
In questo articolo abbiamo visto alcuni sistemi per eseguire predizione e fetch di più istruzioni per ciclo di clock.
Nel prossimo (e ultimo!) articolo sulla branch prediction vedremo come ottenere questi risultati anche ad “alta frequenza”, cioè come organizzare la predizione e il fetch quando sia il predittore che la cache istruzioni sono spezzate su più stadi di pipeline (magari in numero diverso!) per continuare ad ottenere un flusso di istruzioni per ogni ciclo di clock.







