Nei precedenti articoli abbiamo visto come utilizzare una pipeline per aumentare l’efficienza di utilizzo dell’hardware e aumentare di conseguenza le prestazioni della macchina. Tuttavia, la semplice pipeline in-order soffre di una serie di limitazioni che non le permettono di sfruttare buona parte dell’Instruction-Level Parallelism (ILP) presente in un programma. Di conseguenza, le sue prestazioni non riescono a salire oltre un livello generalmente modesto, con un IPC (Instructions Per Clock) sempre minore di 1.
Il problema è che il listato assembly è una sovraspecifica del programma: l’ordine delle istruzioni specificato è condizione sufficiente ma non necessaria per ottenere il risultato voluto. Nella pipeline semplice le istruzioni vengono eseguite strettamente in ordine di programma, non potendo superarsi all’interno degli stadi, e questa è la causa del mancato sfruttamento dell’ILP.
Per risolvere il problema e aumentare ancora di più le prestazioni è necessario cambiare completamente paradigma: le istruzioni devono poter eseguire, all’interno della CPU, nell’ordine più veloce, indipendentemente dall’ordine specificato dal codice. La domanda naturalmente è: qual è questo “ordine più veloce”? Come lo si trova? Come lo si esegue?
Negli anni ’70 / ’80 queste domande alimentarono molta ricerca in ambito accademico, e produssero un paradigma di computazione chiamato dataflow architecture. L’idea base è di eseguire le istruzioni non in ordine di programma, ma in ordine di disponibilità degli operandi: appena un’istruzione ha tutti gli operandi disponibili, essa viene attivata ed eseguita. Questo è il limite ultimo raggiungibile di IPC: avendo a disposizione hardware illimitato, l’intero programma potrebbe essere analizzato ad ogni ciclo di clock, tutte le istruzioni pronte verrebbero eseguite, e il programma verrebbe completato nel minimo numero di cicli di clock possibile. Visto che tutte le dipendenze sono rispettate, il programma eseguirà correttamente e produrrà il risultato voluto, nonostante l’aggressivo rimescolamento delle istruzioni.
La conseguenza di questo paradigma è un’architettura insolita, molto diversa da quelle a cui siamo abituati. Innanzitutto non esiste un Program Counter, visto che le istruzioni non devono essere sequenziate in ordine di programma. Inoltre, la memoria non viene acceduta per indirizzo ma per tag unica: il compilatore assegna ad ogni operando e risultato una tag unica (che non si ripete per tutto il programma), e le istruzioni cercano i propri operandi tramite questa tag. Il cuore del sistema è quindi una Content-Addressable Memory (CAM) : ogni dato è in rappresentato in memoria come una coppia {tag, dato}, e per cercare una tag bisogna scorrere tutte le coppie fino a trovarla.
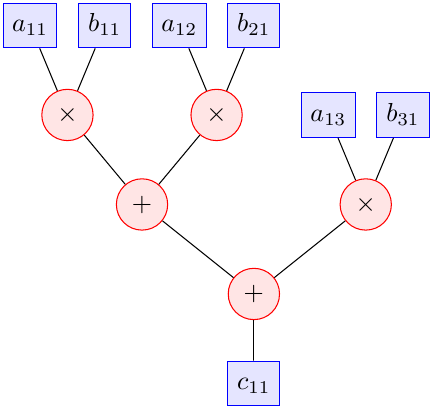
Per chiarire il concetto, consideriamo questa sequenza di operazioni
c11 <= a11 * b11 + a12 * b21 + a13 * b31
che potrebbe venire, ad esempio, dal prodotto tra due matrici. In pseudo assembly può essere tradotta come
r1 <= a11 * b11 r2 <= a12 * b21 r3 <= a13 * b31 c11 <= r1 + r2 c11 <= c11 + r3
In una pipeline semplice queste istruzioni verrebbero eseguite in ordine e, se la ALU avesse dei forwarding paths (come spiegato qui), verrebbero eseguite al ritmo di esattamente una istruzione per ciclo di clock. Tuttavia, è chiaro che si potrebbe fare meglio di così: le prime tre istruzioni sono indipendenti, e possono essere eseguite in qualsiasi ordine (quindi anche contemporaneamente). Il modo più semplice per rendersene conto è analizzare il grafo delle dipendenze tra le istruzioni:
L’altezza dell’albero è 3 (il ramo sinistro, composto da due somme e una moltiplicazione), e quindi, avendo a disposizione abbastanza hardware, sarebbe possibile eseguire quelle istruzioni in soli 3 cicli di clock. Ma come fare?
L’architettura dataflow risolve il problema riscrivendo il programma in memoria in questo modo (estremamente idealizzato):
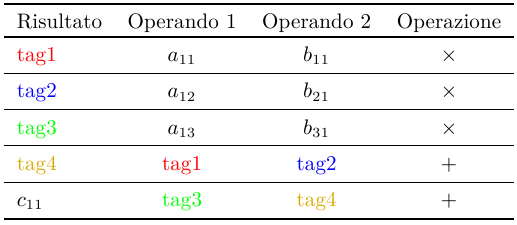
La memoria non viene più acceduta per indirizzo, ma per tag, tramite una ricerca completa della tag. L’esecuzione procede in questo modo:
- al primo ciclo di clock, le prime tre istruzioni sono segnate “attive” perchè tutti i loro operandi sono disponibili (supponiamo che fossero stati caricati in precedenza) e vengono eseguite in parallelo; i loro risultati, identificati dalle tag {1,2,3} vengono propagati all’intera memoria per essere “catturati” dalle istruzioni che hanno le stesse tag
- al secondo ciclo di clock, l’istruzione 4 è pronta ad eseguire perchè ha catturato i valori associati alle tag {1,2} al ciclo precedente; esegue e propaga il suo risultato
- al terzo ciclo di clock, l’ultima istruzione ha tutti i suoi operandi (prodotti nel primo e secondo ciclo), e può eseguire
In questo modo molto elegante è possibile eseguire sempre ogni programma nel minimo numero di cicli di clock possibile (cioè con lo IPC più alto possibile). Sfortunatamente, questo schema ideale mal si adatta alla realtà: non è possibile costruire una memoria di questo tipo che sia abbastanza grande da contenere tutto un programma (o una buona parte di esso) e abbastanza veloce da permettere buone prestazioni. In particolare, il parallelismo è a grana troppo fine (a livello di singole istruzioni) e il tempo di propagazione dei dati nella memoria è superiore al tempo di esecuzione delle istruzioni.
Per questi motivi le architetture dataflow pure sono rimaste esercizi accademici senza applicazioni commerciali. Ma i concetti principali sono confluiti nelle architetture Out-Of-Order, cuore di tutti i moderni processori ad alte prestazioni, di cui mi occuperò nei prossimi articoli.







