Con questa settimana, chiudiamo il discorso sulla tessellation facendo qualche breve considerazione di carattere prestazionale.
Partendo dalla breve disamina sulle architettura proposte da ATi e nVIDIA la volta scorsa, cerchiamo di capire quali siano i vantaggi e gli svantaggi di questo tipo di architettura, partendo dal flusso di dati.
Se pensiamo allo schema: VS->HS->tessellator->DS->GS notiamo che in una pipeline classica, come quella di RV870, dove c’è un’unità dedicata che contiene i tre stadi dedicati alla tesellation, i dati in ingresso debbano, inizialmente, essere trasferiti dai VS agli HS mentre in GF100 questo non avviene perchè le stesse unità si occupano di eseguire le istruzioni relative ad entrambi i tipi di shader; però abbiamo l’input assembler contenuto nel polymorph engine, ossia nello stadio di tipo fixed function della pipeline geometrica di Fermi.
Un trasferimento di dati comporta sempre un aumento di latenze e sarà necessario valutare l’impatto di questi due tipi di trasferimento e il modo in cui AMD e nVIDIA hanno provveduto a mascherare le latenze. Nel prosiequo dell’elaborazione, in RV870 i dati seguono un percorso interno all’unità di tessellation ed escono quando sono pronti per essere inviati ai GS.
In Fermi, al contrario, dai VS vengono inviati al polymorph engine dove sono sottoposti a tessellation e, di li, di nuovo allo shader core per le operazioni di DS e GS. Anche in questa fase avviene un trasferimento per parte ma a livelli differenti e valgono le considerazioni fatte in precedenza.
Con i chip DX11, allo shader core è affidato anche il compito di effettuare le operazioni di texture blending, ossia quelle operazioni necessarie ad applicare filtri come l’AF. Lo scopo di questa digressione è di puntualizzare un altro elemento che può costituire un punto di forza ma anche un punto debole della scelta di nVIDIA.
Lo shader core è chiamato a svolgere le operazioni di VS, PS, GS e quelle di texture filtering; in GF100 devono anche occuparsi di sosittuire HS e DS. Se da un lato questa scelta permette di avere una miglior granularità, ossia di avere più potenza quando serve, riducendo al minimo l’hardware dedicato alla tessellation, dall’altro ripropone il solito dilemma: meglio unità dedicate, specializzate e, quindi, più veloci nell’eseguire un particolare compito, oppure meglio unità generiche che possano essere riutilizzate anche per fare altro?
Da un lato, l’unità dedicata di ATi, qualora non si ricorra all’uso di Higher Order Surface, resta del tutto inattiva; dall’altro le unità di shading di nVIDIA, nel momento in cui parte un’operazione di tessellation, si trivano, per forza di cose, a rallentare le altre elaborazioni dovendosi dedicare, almeno in parte, alle operazioni di hull e domain shading.
E a quelli che pensano che il maggior peso dell’operazione di generazione di HOS gravi sul tessellator, consiglio di leggere questa interessante analisi delle prestazioni in game di Cypress (aka RV870) nella cui ultima parte si stabilisce che le operazioni che hanno il maggior impatto sulle prestazioni, durante e dopo la tessellation, sono quelle di Hull Shading e di Rasterization, mentre il tessellator occupa una parte minima del tempo della GPU. In basso, riporto la “torta” con le varie fasi dell’elaborazione
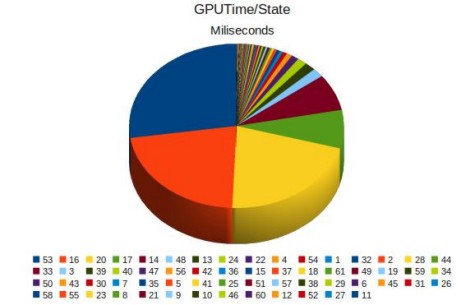
dove lo spicchio blu e quello arancione sono relativi alle due suddette operazioni mentre il giallo è dovuto ad un bug dei driver ATi nella gestione del LDS (ossia della memoria locale interna ad ogni cluster).
Il fatto che gli hull shader abbiano un grande impatto sulle prestazioni non deve stupire, in quanto in questa fase, come si ricorderà, ci si occupa anche delle operazioni di displacement mapping che richiedono accessi a texture (che equivalgono ad enormi latenze). Per quanto riguarda la rasterizzazione, c’è da tener conto che le operazioni di tessellation generano un gran numero di triangoli che vanno colorati e rivestiti (altri accessi a texture oltre alle operazioni di pixel shading).
Se poi il motore grafico, analogamente a quello del tool usato nel test (Unigine Heaven 1.0) causa un notevole overdraw di poligoni nascosti, è chiaro che il peso della rasterizzazione è destinato ad aumentare, in quanto la GPU renderizzerà anche quelle superfici che, non essendo visibili, sono destinate ad essere eliminate nell’ultima fase dello z-test all’interno delle RBE.
Concludiamo questa breve analisi prestazionale col dire che è difficile stabilire, a priori, quale tra le due implementazioni darà migliori risultati in game. Quella di nVidia sembra farsi preferire dal lato delle pure e semplici operazioni di tessellation ma potrebbe incidere negativamente sulle prestazioni nel momento in cui lo shader core fosse chiamato a compiere altre elaborazioni altrettanto onerose.
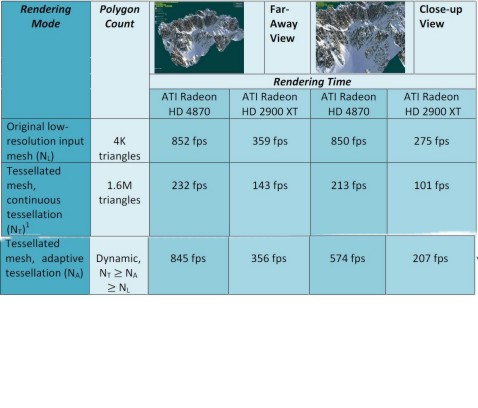
Inoltre, passando a chip di fascia inferiore, al diminuire delle unità di calcolo, mentre il tessellator di ATi può restare invariato (e quindi anche un chip di fascia bassa potrebbe avere la stessa capacità di eseguire questo tipo di operazioni di uno di fascia alta), nel caso di nVidia, al diminuire del numero dei PE e dei RE diminuisce anche la potenza di calcolo che il chip può dedicare alla tessellation ed il numero di vertici che possono essere gestiti dall’input assembler per ogni ciclo. A titolo di confronto, la seguente tabella mostra le prestazioni relative ad operazioni di tessellation con displacement mapping, in diversi casi:

Da questa tabella si può vedere come la soluzione nVIDIA sia sempre in vantaggio, mostrando una miglior propensione ai calcoli geometrici in generale (che non è argomento di questo articolo) e nella tessellation in particolare. Il vantaggio massimo lo raggiunge nel caso di utilizzo di tessellation ultra unità a displacement mapping.
Come avrete notato, la tabella riporta più voci relative alla tessellation ed il motivo risulterà chiaro a breve. Posso, comunque, anticipare il fatto che esistono due modi di fare tessellation, uno detto continuous mode ed uno adaptive mode, di cui parlerò tra poco e che dove è riportata la dicitura “tessellation” si fa riferimento al continuos mode mentre l’altra voce è, chiaramente, riferita all’adaptive mode. Entrambe le forme sono applicate facendo uso di due modalità con differente peso a livello di elaborazione.
Molto probabilmente, come sempre più spesso, purtroppo, avviene, si assisterà a situazioni che varieranno moltissimo da un titolo all’altro favorendo ora questo ora quel tipo di implementazione a seconda delle ottimizzazione di quello specifico software. Anche in questo caso, riporto due esempi di due giochi che fanno uso di tessellation e che danno risultati differenti con tessellation attiva: da un lato abbiamo Aliens vs Predator in cui è in vantaggio AMD

e per completezza riporto anche il risultato con MSAA attivo in cui la situazione si ribalta a favore di nVIDIA ma esclusivamente perchè le VGA con chip ATi vedono dimezzato, di fatto, il frame rate, a causa, molto probabilmente, di una non ottimale gestione della cache L2 (la stessa cosa accade anche a basse risoluzioni)

dall’altro Metro 2033 che, pur risultando, con i settaggi riportati in questa comparativa, ingiocabile con entrambe le soluzioni, vede un chiaro vantaggio per nVIDIA soprattutto se si fa riferimento al frame rate minimo, ma, in questo caso, il vantaggio pare determinato dal fatto che la soluzione proposta da ATi risulta frame buffer limited.

e, comunque, anche a risoluzioni inferiori, il vantaggio di Fermi appare piuttosto chiaro

Coma anticipato quanche riga più in alto, esistono, fondamentalmente, due modi di fare tessellation, ovvero i già citati continuous mode e adaptive mode. Per questo, vorrei proporre, in conclusione, un altro tipo di analisi prestazionale che, stavolta, non mette a confronto due scelte così radicalmente differenti come quelle operate da ATi e nVIDIA quanto, piuttosto, le due suddette implementazioni di tessellation, provate sulla stessa architettura.
Come i più smaliziati avranno capito, al termine adaptive corrisponde sempre una scelta che, lungi dall’andare nella direzione della qualità assoluta, cerca di conciliare, piuttosto, qualità (magari un po’ inferiore) con prestazioni. In effetti, come per l’AF e l’antialiasing, lo stesso vale per la tessellation.
Il continuous mode si basa su un unico livello di tessellation per ogni chiamata (quindi per ciascuna mesh o gruppo di mesh); questo significa che una mesh che presenta un determinato LoD avrà tutti i suoi poligoni con lo stesso livello di tessellation e che una mesh il cui LoD sia di poco inferiore sarà uniformemente tessellata (brutta italianizzazione del termine) con un livello di poco inferiore a quello della precedente.
Il risultato è che ciascuna mesh o gruppo di mesh che abbianno lo stesso LoD presentano una tessellation di tipo omogeneo e dello stesso livello mentre le trnsizioni tra mesh con LoD differenti saranno, comunque, sfumate; ciò si traduce in transizioni dolci nelle curvature degli oggetti e in una tessellation di tipo uniforme su interi oggetti. Questo tipo di procedura impegna molte risorse e comporta lo stesso livello di tessellation anche su superfici che, all’interno del frame, risultano poco evidenti e in scarsamente in risalto.
Contrapposto a questo metodo, c’è l’adaptive mode che prevede la possibilità di avere differenti livelli di tessellation per ogni edge o spigolo della mesh. In tal modo è possibile adattare il livello di tessellation non solo sulla base dei valori del LoD ma anche in funzione delle superfici che risultano più visibili (un esempio banale è una superficie completamente in ombra ma molto vicina al punto di osservazione).
Nell’adaptive mode è necessario specificare un livello massimo ed uno minimo di tessellation e, poichè si tratta di un metodo che prevede un’analisi di tipo dinamica, si deve calcolare, per ogni frame (at render time) il tessellator edge factor. Questo tipo di operazione avviene come operazione preliminare all’inizio di ogni frame e richiede un passaggio di rendering supplementare ma permette di ridurre notevolmente il numero di poligoni generati e il conseguente impatto delle operazioni di displacement mapping e rendering. A titolo di esempio, vi invito a guardare la seguente tabella
da cui risulta evidente come, a fronte di una qualità di’mmagine leggermente inferiore, l’adaptive tessellation di tipo dinamico permette di ottenere prestazioni quasi allineate a quelle raggiungibili con l’immagine priva di tessellation, soprattutto nella vista da lontano; questo perchè, ovviamente, nella vista da vicino aumenta il LoD e, di conseguenza, Na si avvicina al valore di Nt molto di più di quanto non avvenga con la visuale da lontano (in cui il valore è molto più prossimo a quello di Nl).
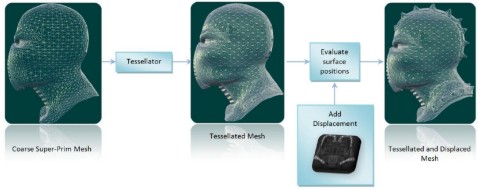
Concludiamo questa breve trattazione sulla tessellation con un altro dei vantaggi che questa tecnologia offre: il risparmio di risorse. Nella demo di froblins si fa uso di un modello in bassa risoluzione sottoposta a tessellation e displacement mapping in modo analogo a quanto indicato in figura
Nella tabella in basso si può apprezzare la differenza, a livello di occupazione dei memoria, tra il modello in “bassa risoluzione” ed il modello con “dettaglio elevato”
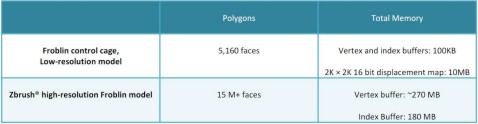
Nella seconda riga sono riportati i valori dell’occupazione di memoria equivalente qualora, anzichè ricorrere alla tessellation ed al displacemente mapping, si fosse fatto uso di un modello originario della stessa complessità di quello ottenuto al termine delle operazioni di tessellation stesse.
Da una parte abbiamo pochi KB di occupazione dovuti ai dati relativi ai vertici trasferiti dalla CPU alla VRAM e da quest’utlima ai vertex shader e i 10 MB dovuti alla texture a 16 bit usata per il displacement mapping; dall’altra i circa 450 MB occupati dai dati di tipo geometrico, corrispondenti agli oltre 15 milioni di poligoni che la CPU doveva generare e trasferire, attraverso il bus, alla VRAM.
Quindi, oltre che per aumentare il dettaglio poligonale, il tessellator può tornare utile per ottenere un notevole risparmio di banda e di memoria occupata; inoltre, altro vantagio non trascurabile, il fatto di poter operare questa “miracolosa” moltiplicazione dei poligoni on chip, invece di dover caricare quantità enormi di dati dalla vram, sommata agli atri due vantaggi precedentemente enunciati, permette di conseguire i vantaggi visti a livello di qualità d’immagine, oppure di avere prestazioni nettamente superiori a parità dei dettaglio.
Con questo, concludo, sperando di aver fatto cosa gradita a tutti coloro che, soprattutto, in questi giorni, con l’avvento delle DX11, stanno dibattendo sui forum di tutto il mondo se sia più efficace la tessellation si ATi o quella di nViDIA e su quanti e quali vantaggi questa feature possa portare.







