A tre anni di distanza, nel 1987 Motorola presenta il 68030, revisione del core introdotto col 68020, similmente a quanto aveva fatto in precedenza col 68000 e il 68010, in quello che sarà un ciclo pari-dispari che contraddistinguerà questa fortunata e apprezzata famiglia di microprocessori.
Revisione può sembrare un termine che sminuisce l’importanza di una CPU, ma non deve avere necessariamente un’accezione negativa. Al solito, bisogna guardare ai fatti e alle novità introdotte, tenendo in debito conto il contesto in cui ciò avviene.
Se gli 84mila transistor del 68010 rappresentano appena il 24% in più dei 68mila utilizzati dal suo predecessore, il 68030 coi suoi 273mila arriva a superare del 44% i 190mila del 68020, lasciando quindi immaginare che “sotto la scocca” un bel po’ di cose saranno state migliorate. Tutto ciò senza nulla togliere ai notevoli e apprezzati miglioramenti sul fronte della virtualizzazione che ha portato il 68010.
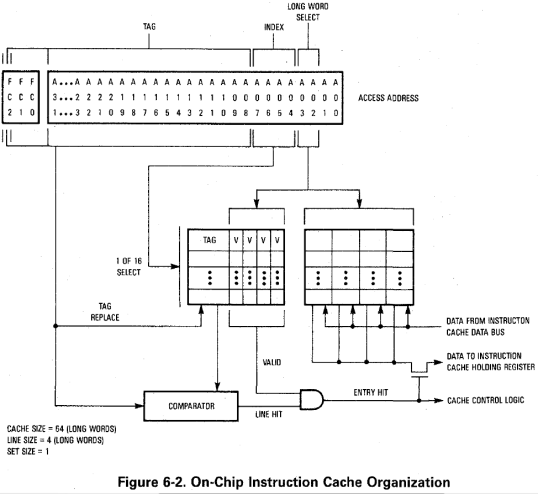
Cominciamo col dire che questa CPU è la prima della famiglia a integrare un’architettura (parzialmente) di tipo Harvard, in quanto l’unità centrale è in grado di leggere contemporaneamente le istruzioni dalla cache per il codice e i dati dalla nuova cache per i dati (utilizzando allo scopo, quindi, bus diversi e paralleli).
Infatti ai 256 byte di cache per il codice, il 68030 ne affianca altrettanti per i dati, ed entrambe sono in grado di fornire una longword (32 bit) in un solo ciclo di clock. Inoltre per mantenere coerenza con la memoria, se un dato presente in cache viene (sovra)scritto, la CPU provvede ad aggiornare contemporaneamente sia la cache che la memoria. E’ anche possibile decidere di memorizzare comunque il dato in cache (anche se in precedenza non era in essa presente), settando un apposito bit nel registro CACR (per la gestione della cache) che abilita questa politica di write allocation.
Rispetto al 68020 c’è, comunque, una grossa differenza che riguarda l’organizzazione dei dati nella cache. Mentre prima i 256 byte erano suddivisi in 64 “linee” (con ogni linea che conteneva una longword, un bit di validazione, un diverso indirizzo associato, e veniva indirizzata tramite i bit A7-3 degli indirizzi), adesso ne sono presenti soltanto 16:
Ogni linea indirizza logicamente 4 longword “contigue” (cioè condividono gli stessi 28 bit alti dell’indirizzo, A31-4, e tramite A3-2 si seleziona ognuna delle 4 dalla linea), ma ogni longword viene trattata e utilizzata in maniera indipendente (poiché a essa è associato un apposito bit per marcarne il contenuto come valido o meno). Quindi abbiamo sostanzialmente 16 (macro) indirizzi di memoria “cachabili”.
In teoria si tratta di un peggioramento, perché in precedenza le 64 linee erano completamente indipendenti, poiché potevano contenere 64 indirizzi diversi. In realtà bisogna tener conto della “località” delle istruzioni e dei dati, che generalmente tendono a essere aggregati a indirizzi di memoria “vicini”, per cui c’è più probabilità di leggere codice e/o dati sulla stessa linea da 16 byte, che da 4 linee a indirizzi completamente diversi.
In ogni caso la precedente cache istruzioni era più flessibile, in quanto poteva tranquillamente mappare 4 longword sia a indirizzi contigui, quindi funzionando esattamente come l’attuale, che ad altri completamente diversi, risultando quindi più performante nel casi di codice poco “lineare / locale” (con frequenti salti a indirizzi diversi).
Il motivo di questa scelta da parte di Motorola è semplice: privilegiare i casi più comuni / frequenti, mettendo a disposizione una nuova modalità di accesso alla memoria denominata “burst“, che assieme all’altrettanto nuova modalità sincrona porta a ben tre diverse possibilità di connettersi con la memoria o le periferiche:
- asincrona (la stessa e l’unica disponibile col 68020), che richiede almeno 3 cicli di clock per il completamento dell’operazione, e consente di interfacciarsi con qualunque dispositivo in qualunque configurazione e dimensione delle “porte” (8, 16 o 32 bit), ma soprattutto con frequenza di clock diversa da quella impiegata dal processore
- sincrona, necessita di 2 cicli di clock e la dimensione della porta obbligatoriamente a 32 bit (quindi possono essere trasferite soltanto longword), con allineamento del dato allo stesso tipo (gli indirizzi devono essere multipli di 4 byte)
- burst, simile alla precedente, ma che consente di trasferire fino a 4 longword, impiegando 1 ciclo di clock per ogni longword successiva alla prima (in pratica per i primi due cicli la CPU esegue un accesso sincrono e alla fine del secondo ciclo, se il dispositivo è in grado di fornire un’altra longword, si prosegue sfruttando soltanto il prossimo ciclo; e così via)
Ovviamente nelle due nuove modalità è previsto l’inserimento di appositi cicli di wait per memorie o dispositivi più lenti, in modo da terminare l’operazione in maniera corretta (e soprattutto con dati consistenti).
Si capisce bene, a questo punto, il perché della nuova organizzazione delle cache: grazie al “burst mode” è possibile riempire molto velocemente un’intera linea di cache (4 longword, 16 byte) impiegando soltanto 5 cicli di clock (2 + 1 + 1 + 1), quando in precedenza il 68020, nelle medesime condizioni, ne richiedeva ben 12 (3 * 4).
A far lievitare il numero di transistor ha provveduto anche l’integrazione di una MMU per la paginazione della memoria. Per la precisione si tratta di una versione più economica e con meno funzionalità del 68851 (chip che in precedenza Motorola aveva realizzato per 68010 e 68020), ma con l’aggiunta di qualche utile meccanismo.
Queste le caratteristiche di targa:
- dimensione delle pagine variabile da 256 a 32K byte (per potenze di 2, ovviamente)
- fino a 4 livelli per l’albero di traduzione delle pagine e ogni livello è configurabile per tradurre da 0 (inutilizzato) a 15 bit (32K pagine) dell’indirizzo virtuale, con almeno un livello obbligatoriamente da utilizzare; per confronto, a partire dall’80386 gli x86 hanno messo a disposizione un modello fisso a 2 livelli (di 1024 pagine ognuno) e dimensione fissa delle pagine a 4KB (soltanto più tardi, con alcuni Pentium, è arrivata una modalità con un solo livello e pagine di 2 o 4MB)
- 2 master page table (una per la modalità utente, e una per quella supervisore) per la traduzione degli indirizzi (eventualmente se ne può utilizzare soltanto una condivisa da ambedue le modalità)
- possibilità di definire 2 aree di memoria (con un taglio minimo di 16MB) non soggette alla traduzione degli indirizzi (caratteristica assente nel 68851; utile per mappare aree di memoria che, ad esempio, non devono essere soggette a caching, senza per questo definire per ogni processo delle apposite pagine)
- 22 entry nell’Address Translation Cache (ATC; cache “fully associative” utilizzata per evitare di decodificare un indirizzo virtuale ogni volta, effettuando il caching degli ultimi indirizzi virtuali già tradotti)
Essendo on-chip, i tempi per la decodifica degli indirizzi di memoria sono drasticamente ridotti in quanto quest’operazione viene eseguita in parallelo all’accesso alle due cache e alla memoria esterna. Per essere più chiari, quando al 68030 serve un dato a un certo indirizzo, questo può trovarsi:
- nella cache istruzioni
- nella cache dati
- nella memoria esterna
per cui l’unità centrale si attiva su tutti e tre i fronti (per semplificare), e per quest’ultimo oltre a iniziare un’operazione di accesso col bus esterno attiva anche la ricerca nell’ATC per vedere se l’indirizzo virtuale risulta già tradotto. Alla fine del ciclo (perché tutte e tre le operazioni richiedono un solo ciclo, appunto) è già in grado di sapere come proseguire:
- se ha trovato il dato in una delle cache, abortisce l’accesso alla memoria
- se ha trovato l’indirizzo nell’ATC, prosegue con l’accesso alla memoria se l’indirizzo è valido, altrimenti abortisce l’operazione e solleva un’eccezione
- se non ha trovato l’indirizzo nell’ATC, abortisce l’accesso alla memoria e inizia un ciclo di operazioni per recuperare l’indirizzo fisico partendo dalla master page table, e alla fine se l’indirizzo fisico ottenuto è valido fa partire un nuovo accesso alla memoria (se non è valido, solleva un’eccezione)
Rispetto al 68851 mancano parecchie funzionalità e soltanto poche istruzioni del coprocessore possono essere utilizzate (PFLUSH, PLOAD, PMOVE, e PTEST), ma il modello offerto dal 68030 ritengo sia sufficiente flessibile, col notevole vantaggio dell’integrazione on-chip che permette di velocizzare le operazioni di traduzione quando l’MMU risulta attiva (col 68851 la CPU doveva comunque iniziare un ciclo di lettura, l’MMU doveva poi prelevare l’indirizzo dal bus, effettuare tutti i controlli, e soltanto dopo decidere se e come proseguire).
Contrariamente alle informazioni che si trovano in giro, e in particolare nell’apposita paginetta su Wikipedia, le innovazioni introdotte col 68030 hanno portato a un generale miglioramento delle prestazioni, in particolare grazie al veloce accesso alla memoria, alla presenza della cache dati (per non parlare dell’integrazione della MMU, quando il sistema operativo la utilizza), e a un più efficiente meccanismo di “overlapping” nell’esecuzione delle istruzioni (di cui abbiamo parlato nell’articolo sul 68020).
E’ sufficiente confrontare l’apposito capitolo relativo ai tempi di esecuzione delle istruzioni nei manuali dei rispettivi microprocessori per rendersi conto che, perfino nel caso peggiore, il 68030 offre prestazioni quasi sempre migliori, anche sensibilmente (in particolare per gli accessi alla memoria), rispetto al 68020.
Tra l’altro la stessa Wikipedia si smentisce perché riporta in questa pagina 4 MIPS per il 68020 a 20Mhz, e 11 per il 68030 a 33Mhz. A conti fatti, un ipotetico 68020 a 33Mhz arriverebbe a 6,6MIPS (supponendo un incremento lineare rispetto alla frequenza di clock), che è decisamente inferiore…
Con questa CPU rimangono delusi, invece, i programmatori, in quanto non risulta alcuna nuova istruzione o modalità d’indirizzamento, ma si registra, invece, una defezione (l’eliminazione delle istruzioni relative ai “moduli”, CALLM/RTM). Fatta eccezione ovviamente per l’MMU integrata, che però rimane generalmente appannaggio del sistema operativo e, quindi, inaccessibile alle normali applicazioni.
D’altra parte le migliorie apportate con questo processore sono motivo sufficiente di apprezzamento nei suoi riguardi. Non bisogna neppure dimenticare che un’ISA come quella del 68020 risultava già sufficientemente complicata e colma di istruzioni, e vedremo che, per questo motivo, coi successi modelli la mannaia di Motorola tornerà ad abbattersi eliminando un po’ di “zavorra”…







