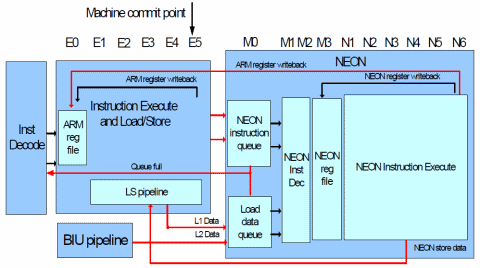
Coi Cortex-A8 ARM ha dato una svolta alla sua premiata e amatissima architettura, proponendo una serie di innovazioni che le permettono di rimanere al passo coi tempi e delle nuove esigenze sorte nel campo dell’elaborazione automatica.
Fra di esse e come abbiamo sottolineato è arrivata un’unità SIMD nuova di zecca (chiamata internamente Advanced SIMD e pubblicizzata come NEON), segno questo che il precedente approccio non era più sufficiente a garantire un adeguato ritorno in termini puramente prestazionali.
Le vecchie estensioni SIMD potevano andare bene in un’ottica di semplificazione implementativa e di risparmio della circuiteria dedicata (e sono state certamente utili in questo senso). Paragonata, però, a quella delle unità dedicate presenti in altri microprocessori, la velocità d’esecuzione ne soffriva particolarmente.
Anzi, possiamo tranquillamente affermare che erano giunte al capolinea in quanto non più ulteriormente migliorabili (a parte l’introduzione di qualche nuova istruzione) a causa delle intrinseche limitazioni (citate nell’articolo a esse dedicato), e che non potevano essere aggirate in alcun modo.
Il raggiungimento dell’obiettivo passava necessariamente per lo spostamento di questi tipi di calcolo in un’apposita unità di elaborazione che permettesse di superare il più grosso degli ostacoli, rappresentato dal numero e dalla dimensione dei registri utilizzati, cioé i medesimi della CPU: 16 (13 in realtà, visto che gli ultimi 3 sono, in genere, dedicati a precise mansioni) e a 32 bit.
Ciò non è esattamente vero, in quanto si poteva pensare di estendere a 64 bit l’architettura di questo microprocessore (considerato che la tendenza è ormai questa), ma ARM rimane saldamente ancorata ai 32 bit che finora le hanno fruttato fama e ricchezza. In ogni caso e per quanto sottolineato, avrebbe solamente rimandato il problema delle prestazioni per il calcolo SIMD.
La scelta di ARM è stata comunque conservativa, in quanto ha pensato bene di sfruttare l’area e l’ISA dedicata al coprocessore matematico (chiamato VFP, Vector Floating Point, nelle sue varie evoluzioni: VFPv1, VFPv2 e VFPv3) per mappare i registri e le istruzioni della nuova unità SIMD.
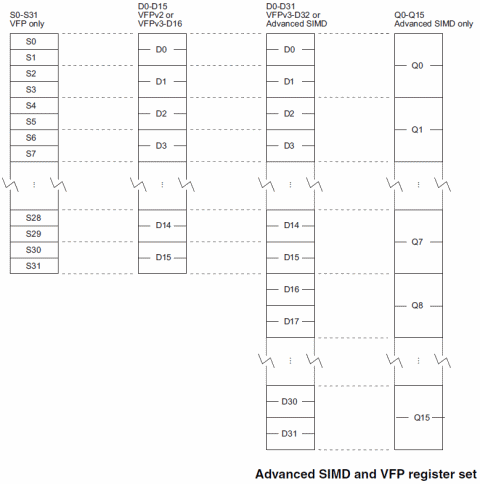
Rispetto all’ISA principale, il VFP aggiunge 16 registri a 64 bit che gli permettono di lavorare in maniera indipendente con valori in virgola mobile a 32 o 64 bit. Di questo coprocessore non abbiamo parlato in precedenza in quanto si tratta di un classica FPU, che presenta però un’interessante possibilità di lavorare anche con vettori di 2-4 valori (da cui il prefisso Vector).
Con l’arrivo di NEON e della contestuale versione 3 del VFP, alcune estensioni sono state apportate anche a quest’ultimo. In particolare il numero dei registri è raddoppiato, passando a 32, e inoltre è possibile supportare (ma ciò non è vincolate per le tutte implementazioni) valori in virgola mobile a 16 bit.
Questi ultimi sono utili in particolari ambiti applicativi: per ridurre lo spazio occupato, poter lavorare col doppio dei dati contemporaneamente, oppure sfruttare unità d’esecuzione piccole e veloci visto che richiedono moltiplicatori e sommatori ridotti specialmente a livello di quantità di transistor.
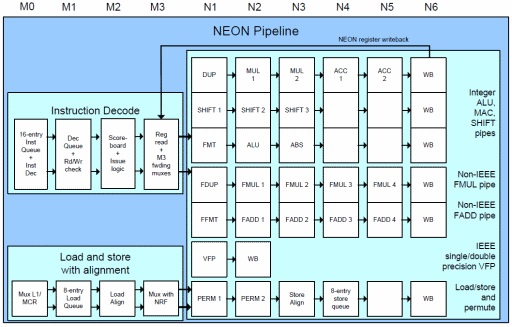
NEON e VFPv3 condividono dunque gli stessi 32 registri a 64 bit, come pure alcune istruzioni, ma possono lavorare in parallelo (anzi, in NEON è contenuto il VFP, in versione “light”, come si può vedere dall’immagine), a differenza di quanto avveniva con le estensioni VIS degli SPARC, le MMX di Intel e le 3DNow! di AMD, tutte accomunate dal fatto di avere sfruttato i registri dell’FPU per mappare i nuovi registri SIMD e di dover utilizzare apposite istruzioni di cambio del contesto a seconda dell’uso.
Preciso che ciò non rappresenta una grossa limitazione, poiché è molto difficile che nello stesso momento una CPU abbia la necessità di elaborare sia le classiche operazioni scalari in virgola mobile, che quelle vettorizzate (intere o in virgola mobile che siano): si tratta di pattern di utilizzo decisamente diversi. Inoltre le unità SIMD moderne permettono comunque di lavorare con dati scalari, per cui il problema decisamente non si pone (se non per lo spazio sprecato internamente per le implementazioni dotate di registri molto capienti).
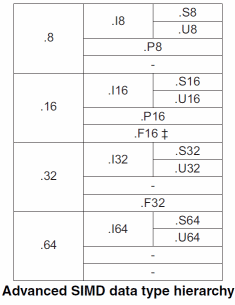 Come tipi di dato NEON ne supporta un discreto numero. Oltre ai già citati valori in virgola mobile a 32 e 64 bit (identificati generalmente come .F32 e .F64, quest’ultimo disponibile solo con VFPv3 e non con NEON), retaggio del VFP, ne è stato aggiunto uno a 16 bit (indicato con .F16) di cui abbiamo già parlato. Inoltre sono supportati interi a 8, 16, 32 o 64 bit, con o senza segno (e con o senza saturazione nelle istruzioni che lo prevedono).
Come tipi di dato NEON ne supporta un discreto numero. Oltre ai già citati valori in virgola mobile a 32 e 64 bit (identificati generalmente come .F32 e .F64, quest’ultimo disponibile solo con VFPv3 e non con NEON), retaggio del VFP, ne è stato aggiunto uno a 16 bit (indicato con .F16) di cui abbiamo già parlato. Inoltre sono supportati interi a 8, 16, 32 o 64 bit, con o senza segno (e con o senza saturazione nelle istruzioni che lo prevedono).
Singolare è la presenza di un tipo polinomiale, dove i singoli bit rappresentano i coefficienti di un polinomio di grado n – 1 (essendo n pari al numero di bit manipolati), con le operazioni fra polinomi che sono eseguite utilizzando la classica logica booleana (sfruttando però l’or esclusivo per le somme, comprese quelle parziali generate nelle moltiplicazioni). Utile per implementare algoritmi come il CRC.
E’ chiaro, però, che il massimo delle potenzialità lo si raggiunge sfruttando l’abilità di poter manipolare vettori di dati. In questo caso NEON consente, sfruttando i registri di dimensione massima (16 a 128 bit, identificati come Q0..Q15), di poter eseguire in un colpo solo numerose operazioni. In particolare, 16 con dati a 8 bit, 8 con dati a 16 bit, 4 con dati a 32 bit, e infine 2 con dati a 64 bit.

Da notare che sfruttando la dimensione a 128 bit, i registri sono soltanto 16 rispetto ai 32 (ma a 64 bit) messi a disposizione. Questo perché due registri consecutivi a 64 bit vengono utilizzati e visti come singolo registro a 128 bit. Quindi, ad esempio, Q0 viene mappato e fa uso di D0 e D1:
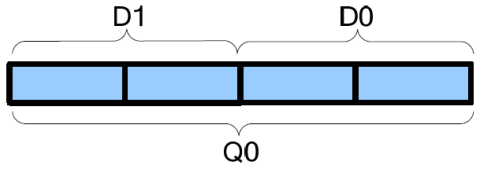
Ciò non deve far preoccupare, se consideriamo che i registri SSE introdotti da Intel erano, sì, a 128 bit, ma soltanto in numero di 8 (questo era il limite dell’architettura x86, a 32 bit). Con l’introduzione di x86-64 da parte di AMD e il raddoppio del loro numero, abbiamo finalmente 16 registri (a 64 bit) per l’ISA principale e altrettanti (sempre a 128 bit) per le estensioni SSE.
Il problema si porrà quando si penserà di estendere i registri a 256 o più bit per poter manipolare in un colpo solo molti più dati e, quindi, incrementare le prestazioni delle operazioni di vettorizzazione. Sia Intel che AMD hanno annunciato apposite estensioni, e in futuro si parla già di unità SIMD con 512 o più bit.
In questo caso ARM si troverebbe a dover mappare 4 registri a 64 bit in uno a 256 bit, ma il loro numero totale scenderebbe di conseguenza a 8. Potrebbe compensare introducendo nell’ISA il supporto ad altri 2 coprocessori, e quindi raddoppiando il numero di registri a disposizione, che passerebbero da 32 a 64 (infatti i 16 registri del VFP sono diventati 32 perché VFPv3 e NEON sono visti come due coprocessori distinti a livello di ISA).
Sarebbe una soluzione, certamente, che però complicherebbe l’architettura, e in ogni caso rimanderebbe il problema, perché non si può indefinitamente aggiungere nuovi coprocessori: al massimo ne sono a disposizione 16, coi primi 8 sono riservati alle estensioni dei partner, e gli ultimi due già sono sfruttati per il debugging e il controllo del sistema. In futuro, a mio avviso, servirà ripensare nuovamente l’approccio SIMD, ma passeranno diversi anni ancora…
Particolarmente interessante e versatile è la possibilità di caricare i registri con le informazioni presenti in strutture dati più complicate, dove risultano “impacchettate” e, per poterle manipolare in maniera omogenea nonché vettorizzata, è necessario prima “spacchettarle”. Un esempio è il seguente:
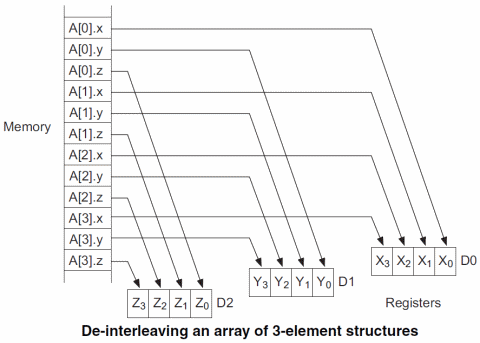
Come si può vedere, il vettore A contiene strutture che rappresentano punti in uno spazio tridimensionale con le coordinate x, y e z che ne conservano i rispettivi valori. Con una sola istruzione è possibile estrarre tutte le coordinate x e riempire un apposito registro, e fare lo stesso con le altre.
Un altro esempio potrebbe essere rappresentato dalla manipolazione dei colori, le cui componenti cromatiche (rosso, verde e blu, a cui si aggiunge eventualmente il canale alpha) risultano “impacchettate” sequenzialmente in strutture simili (formati RGB, RGBA, oppure codificati in altri spazi di colore) e presentano lo stesso problema.
Da sottolineare che NEON si occupa anche di gestire anche eventuali disallineamenti della memoria in maniera trasparente, sollevando il programmatore da operazioni di load, shift e mask per poter ottenere le informazioni allineate correttamente.
Purtroppo un grosso limite è, al momento, rappresentato dall’impossibilità di poter lavorare vettorialmente con dati in virgola mobile a doppia precisione. Va detto che le operazioni più comuni sfruttano quelle in singola precisione, ma negli ultimi tempi è affiorata l’esigenza di poter ottenere risultati più accurati per i calcoli.
E’ plausibile e auspicabile che in futuro ARM provveda a estendere le capacità di NEON, aggiungendone il supporto, e ciò non dovrebbe comportare particolari problemi (se non in ottica di una maggior complessità interna del chip). Il limite più grosso rimane, però, la dimensione massima (128 bit) dei registri, e questo, come già detto, comporterà problemi decisamente maggiori…







