Dopo la parentesi della scorsa settimana, riprendiamo l’analisi delle texture e del loro utilizzo. La scorsa puntata eravamo ritornati sulla modellazione delle texture con l’intento di dedicarci, nel prosieguo, agli effetti dell’applicazione di più texture sulla stessa mesh.
Prima di fare ciò, torniamo brevemente all’ultima parte dello scorso capitolo, dove avevamo introdotto, brevemente, la modellazione di texture a pattern regolare o stocastico. Entrambi i tipi di pattern sono generati partendo da
bitmap, ottenuti da disegni, immagini fotografate e acquisite, ecc, di cui si ritaglia una porzione (definita appunto pattern) e la si ripete, secondo le diverse modalità viste mercoledì scorso, per creare texture a pattern regolare o stocastico appunto.
Esiste, però, un altro modo per generare texture con pattern non perfettamente regolare anche se dotato di un certo grado di ripetitività, ed è quello che fa uso di algoritmi di tipo procedurale.
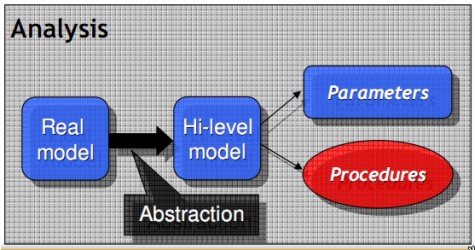
Alla base delle texture procedurali c’è la creazione di un modello virtuale che parta da un suo corrispettivo reale e, attraveros una serie di passaggi intermedi che prevedono l’analisi di un modello reale e portano alla codifica di algoritmi o procedure che ne definiscono le caratteristiche in modo che le stesse siano riporducibili nel modello sintetizzato, liberando il programmatore dalla necessità di definire specifiche dettagliate dello stesso. I vari passi sono riportati nelle due figure in basso
dalla prima immagine si vede come, partendo dall’analisi di un modello reale, si arrivino a definirne le caratteristiche attraverso un processo di astrazione. Da qui, il passo successivo è quello di ricavare i parametri che caratterizzano il modello ottenuto e gli algoritmi in grado di permettere di replicare quello stesso modello (variando, ovviamente, i valori dei parametri per ottenere effetti differenti).
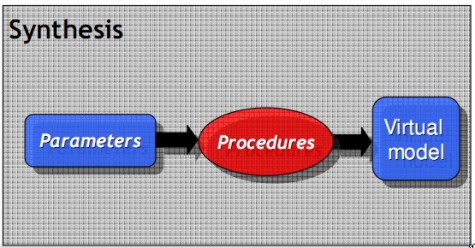
La seonda fase consiste, appunto, nell’inserie i valori dei parametri all’interno degli algoritmi così ottenuti e, al variare dei primi, sintetizzare differenti modelli virtuali basati tutti su un’unico set di caratteristiche di partenza.
La scelta del modello reale può avvenire in due modi: partendo da un campione reale, oppure dalle caratteristiche del modello che si vuole sintetizzare. La prima delle due tecniche, detta IBR (image based rendering), ha il vantaggio di conservare un campione della texture di origine durante l’intero processo e di permettere la generazione di texture on the fly. La seconda (texture synthesis) semplifica la fase di analsi perchè permette di avere facile accesso alle proprietà del modello che si vuole riprodurre.
Ovviamente, anche questa tecnica, come tutte le altre, ha dei pro e dei contro. Tra i maggiori vantaggi, l’occupazione di banda e in memoria pressochè nulla (non si deve memorizzare o trasferire un array di valori), possibilità di modellare un gran numero di enntità similari ma non identiche, elevato dettaglio indipendentemente dallo zoom. Tra i contro, la difficoltà ad individuare le caratteristiche del modello reale che l’algoritmo deve riprodurre (per la IBR) e, qundi, la definizione dei suoi parametri, la difficoltà di avere un totale controllo sul risultato finale.
Per cercare di ridurre le difficoltà nell’individuazione delle caratteristiche del modello d’origine, si fa ricorso ai, cosiddetti, algoritmi genetici, in grado di eseguire l’operazione in automatico. In basso è riportato, a grandi linee, lo schema di funzionamento di uno di questi algoritmi
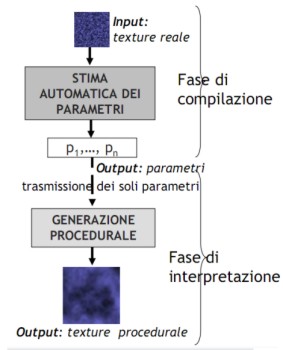
In input abbiamo il modello reale da riprodurre; l’algoritmo genetico opera una analisi dello stesso in cui individua i parametri caratterizzanti e li fornisce in output. Qui, facendo uso di differenti procedure, è possibile variare questi parametri in modo da ottenere un vasto range di modelli sintetici. A valle di tutto, un algoritmo si occupa di confrontare il modello sintetizzato con quello originario per vagliarne la verosimiglianza.
Per cercare, invece, di aumentare il controllo sul risultato finale, si può prevedere un’interazione ad alto livello del coder con il processo di sintesi. Il modello di sintesi proposto in precedenza e definito “automatico”, in quanto non prevede alcun intervento dall’esterno, è sostituito da quello riportato qui in basso, detto “semiautomatico”
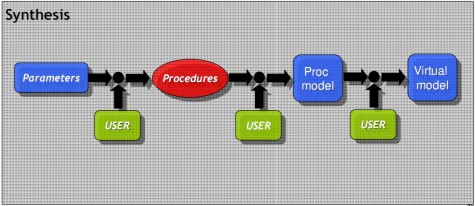
dove sono evidenziati tutti gli step in cui è possibile un’interazione da parte del programmatore.
Una volta ottenuti i parametri del modello reale, si deve scegliere il tipo di algoritmo da adoperare per farli variare. Non mi dilungherò su questo aspetto ma mi limiterò a citare i principali:
- sintesi di Fourier
- metodi di suddivisione frattali
- modelli statistici, adoperati sprattutto per lo studio delle “tessiture naturali”
- introduzione di qualche forma di disturbo
In particolare, l’ultima tecnica è una delle più comuni. Basata su un’idea di Perlin, consiste nello scegliere una primitiva come funzione di noise e nel fare una convoluzione tra questa e la funzione che fornisce il pattern della texture, facendo variare alcuni parametri del noise (come ad esempio, ampiezza o frequenza). In post produzione è possibile modificare, mediante tecniche di filtraggio, alcuni parametri, come, ad esempio, la smoothness.
Le texture 3D sono un particolare rappresentante della famiglia di quelle procedurali. Impossibili da ricavare come astrazione di una mappa reale, sono generate attraverso algoritmi di texture synthesis. L?adozione della terza dimensione permette di modellare tutto lo spazio occupato da una figura solida. Se la texture 2D è scomponibile in una serie di texel ugualmente bidimensionali (si pensi alla schematizzazione con tanti quadratini), una texture 3D la si può immaginare scomposta in un insieme di texel tridimensionali (ad esempio tanti cubi di lato unitario). Il risultato è quello visualizzato nella figura in basso

in cui si vede come le venature del legno proseguano anche all’interno del cubo. Usate dagli anni ’80 nei programmi di grafica, sono entrate a far parte del mondo dei videogame con l’adozione delle DX8 anche se, soprattutto agli inizi, hanno avuto scarso impiego poichè molto esose in termini di bandwidth e memoria occupata.
L’adozione della quarta dimensione ha portato un po’ di insana confusione nella terminologia adottata per le tecniche di filtraggio. Così, ad esempio, quello che in 2D è un filtro di tipo lineare, in 3D diventa un trilinear ed effettuare un filtraggio anisotropico è una delle operazioni più onerose dopo quella di immagazzinaggio di una texture 3D.
Il notevole aumento di potenza di calcolo, l’adozione di tecniche di texture compression sempre più sofisticate e gli incrementi vertiginosi di banda passante uniti a tecniche di ottimizzazione e qualche trucco atto a rendere meno pesante la gestione delle texture 3D, ha reso queste ultime sempre più utilizzate anche perchè molto più funzionali delle corrispettive texture 2D in molti ambiti (si pensi, ad esempio, alla mappatura di un oggetto solido che presenta cavità o fessure).
Con questo accenno alle texture 3D, chiudiamo questa parentesi di tipo qualitativo sulle texture procedurali e passiamo a parlare, brevemente, del cosiddetto multitexturing. Ovvero vediamo cosa succede quando applichiamo più texture su una stessa superficie.
Introdotto nel 1998, rappresentò una delle maggiori novità delle DX6. La possibilità di applicare più texture su una stessa superficie aprì nuovi orizzonti agli sviluppatori che, da quel momento, ebbero un nuovo potente strumento per creare nuovi effetti. Il contro, nell’immediato, fu determinato dalla non elevata potenza di calcolo dei chip grafici e dalla loro incapacità di applicare più texture in un solo ciclo. Più passate significava tanti cicli di clock spesi e prestazioni a picco. Con la generazione DX7, uscirono i primi chip dotati di più texture unit (il primo fu NV15) o, comunque, in grado di applicare più texture per pixel in una sola passata (anche se in più cicli) sfruttando un buffer di accumulazione interno (come il Kyro di PowerVR).
Ma non vi starò a tediare con la storia del multitexturing e la relativa evoluzione delle capacità di texturing dei chip grafici. E’ sufficiente sapere che, dopo la fase in cui, per avere maggiori prestazioni, si preferiva mettere più TMU (texture management unit) sulla stessa pipeline (la Matrox Parhelia ne vanta, addirittura, 4 per pixel pipeline), si è passati a quella in cui, sempre per conseguire le migliori performance velocistiche, si è preferito mettere una sola TMU per pipeline e aumentare il parallelismo delle pixel pipeline stesse, sfruttando buffer interni per accumulare i risultati delle operazioni internedie di texturing, alla stregua dei chip Kyro. Precursore di questa nuova tendenza è stato R300. I chip compatibili con le ultime API sono, ormai, in grado, di applicare fino a 128 texture per pixel in una singola passata (che equivale a diversi cicli).
Abbandoniamo la storia del multitexturing per vedere alcune delle sua applicazioni: uno dei primi effetti creati riguardava l’illuminazione; prendendo una mappa di base e una dark map con effetti di illuminazione e applicandole una sull’altra, si potevano ottenere effetti come quello in figura

Un altro degli effetti ottenibili con l’applicazione di più texel per pixel è noto come bump mapping, su cui non mi dilungo e vi rimando, come anche per il displacement mapping, all’articolo appena linkato. Mi limiterò solo ad integrare quanto già detto sull’EMBM (environment mapped bump mapping) nel capitolo dedicato alle higher order surface. Questa tecnica è usata per simulare le riflessioni in alternativa al raytracing. Questo perchè, pur essendo il raytracing concettualmente semplice da implementare, risulta molto pesante per applicazioni grafiche che devono girare il tempo reale a frame rate, possibilmente, elevati. Il più delle volte, i risultati sono sodidsfacenti e, con superfici piane o convesse e in assenza di gruppi di linee parallele. Vi posto solo alcuni esempi di confronto tra i risultati ottenibili con raytracing e con EMBM sugli stessi soggetti.
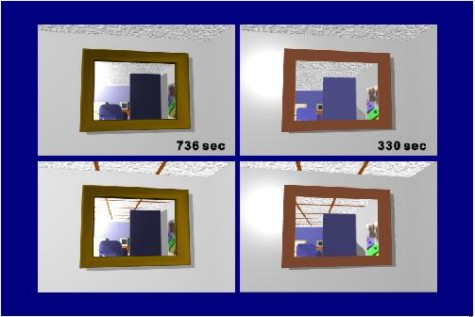
A sinistra le immagini elaborate in raytracing e a destra quelle con EMBM. Al di là del fatto che, a giudicare dagli fps, il sistema adoperato non pare di ultima generazione, si vede come, nel confronto tra le due immagini in alto, quella con EMBM restituisca, tutto sommato, un risultato apprezzabile. In quelle in basso si nota, invece, come in quella con EMBM risulti un mancato allineamento tra le linee parallele riflesse e quelle sul soffitto; allineamento presente, invece, nell’immagine con raytracing.
Per chiudere, faccio brevemente cenno ad un’altra delle applicazioni possibili grazie al multitexturing, ovvero la creazione delle trasparenze. Se si vuole raffigurare un oggetto posto al di là di un reticolato o parzialmente nascosto da un cespuglio o dalle fronde di un albero, oppure creare affetti lente attraverso un vetro, si può far ricorso alla tecnica del multitexturing utilizzando una texture di base, con l’oggetto posto sullo sfondo), una texture trasparente con disegnato, ad esempio, un reticolato; facendo un’operazione di blending tra le due e utilizzando, all’occorrenza, opportune maschere (per cui si può far ricorso ad altre texture) è possibile creare oggetti con parti trasparenti e parti opache, dietro i quali si intravedono altri oggetti; oppure generare effetti di rifrazione attraverso vetri o lenti, come l’esempio sottostante

Con ciò chiudiamo questa breve trattazione che non ha l’ambizione di essere un tutorial sulle texture ma ha il solo scopo di farne conoscere l’utilizzo a chi si avvicina al mondo della grafica 3D. Per questo motivo ho usato molte immagini, a titolo di esempio, corredate da qualche chiarimento.
Con il prossimo capitolo chiuderemo il discorso sulle texture facendo un rapido cenno alle tecniche di texture filtering ed alle unità che dentro una gpu si occupano del loro trattamento e che vanno sotto il nome di TMU (texture management unit).







