Nei precedenti articoli abbiamo avuto modo di apprezzare l’architettura ARM, analizzandone caratteristiche peculiari e funzionalità, focalizzando l’attenzione sugli elementi che l’hanno contraddistinta e sulle modifiche apportate dalla casa madre nel corso degli anni.
Il 2005 segna l’introduzione di una nuova famiglia di microprocessori, con la quale ARM introduce novità, ma anche un po’ d’ordine fra le varie sigle, famiglie, architetture, estensioni, riduzioni e quant’altro abbia contribuito a generare confusione fra una moltitudine di prodotti e relative etichette.
Cortex, questo il suo nome, è presente in tre gruppi, ognuno contraddistinto da una lettera che ne richiama l’appartenenza: Application (A), Realtime (R) e Microcontroller (M).
L’idea è quella di avere un core comune da specializzare specificamente in base al target d’utilizzo. Il più ricco è il gruppo A, che include tutta una serie di caratteristiche ed estensioni necessarie per l’utilizzo in ambito “tradizionale” (desktop, server, smartphone): Thumb-2, Thumb-EE (Jazelle RCT; per Java e altri linguaggi dotati di Virtual Machine), Vector Floating Point (VFP, per calcoli in virgola mobile), Advanced SIMD (NEON), cache L1 ed L2, PMMU e TrustZone (per la sicurezza e i DRM).
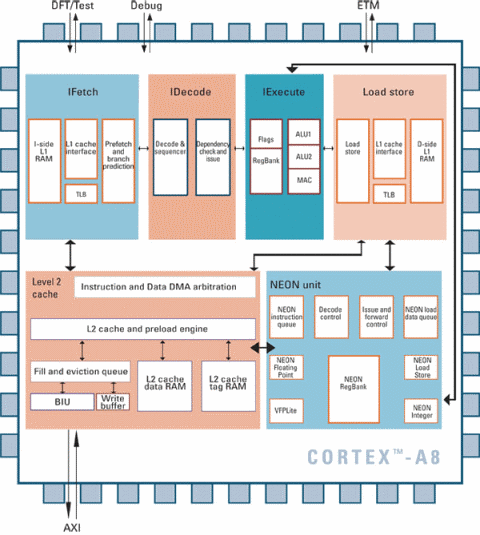
Il gruppo R è pensato per le applicazioni realtime, per le quali la maggior parte di queste funzionalità non è necessaria. Thumb-2 viene implementato ed eventualmente l’unità VFP, per le cache c’è spazio per selezionarne la configurazione, e infine per la protezione della memoria è opzionalmente disponibile un’unità estremamente ridotta (l’MPU, che integra soltanto alcune caratteristiche della ben più complessa PMMU).
Infine il gruppo M, essendo dedicato ai microcontrollori, implementa soltanto il Thumb-2, non è prevista nessuna cache, e l’unità MPU è opzionale. E’ interessante notare che implementando esclusivamente l’ISA Thumb-2, si elimina la classica e tradizionale ARM. La CPU diventa, quindi, a tutti gli effetti un CISC, come abbiamo avuto modo di appurare nel precedente articolo parlando di questa nuova ISA.
Rispetto alla versione 6 dell’architettura le novità di rilievo sono le seguenti:
- NEON, un’unità SIMD dedicata al calcolo di operazioni su vettori di 64 o 128 bit (su registri dedicati) contenenti valori interi (16 o 32 bit) o in virgola mobile (a precisione singola, 32 bit), che opera in maniera indipendente dalla pipeline principale (dalla quale comunque attinge le istruzioni da eseguire)
- VFPv3, che raddoppia il numero di registri (portandoli a 32) dell’unità di esecuzione in virgola mobile e aggiunge qualche nuova istruzione
- Thumb-EE, una versione derivata da Thumb-2 nata per soppiantare Jazelle (la precedente tecnologia per accelerare l’esecuzione di codice Java) e utilizzata per implementare il nuovo modello di esecuzione per macchine virtuali chiamato Jazelle RCT
- TrustZone, che introduce una nuova modalità di esecuzione definita secure per implementare l’esecuzione di codice “fidato” (trusted, che in genere fa ricorso a certificati) e meccanismi di Digital Rights Management (DRM)
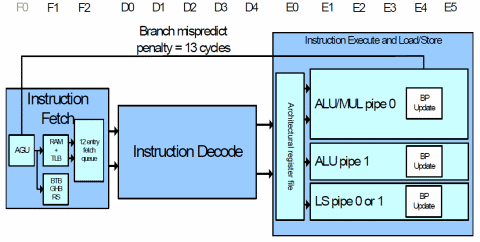
- pipeline superscalare costituita da 13 stadi e in grado di eseguire due istruzioni in-order
Notiamo subito un punto di rottura col passato rappresentato dal fatto che l’approccio usato in precedenza per implementare funzionalità di tipo SIMD è stato molto più “morbido”, modificando il core aggiungendo nuovi flag e istruzioni per accomodare l’applicazione di operazioni (in genere dello stesso tipo) su più dati al medesimo tempo, ma continuando a sfruttare i registri del processore.
Altro cambiamento sensibile è dovuto alla sostanziale rimozione della vecchia modalità Jazelle. In realtà viene mantenuta per retrocompatibilità, ma nessun bytecode viene accelerato in hardware: ognuno di essi comporta l’invocazione dell’handler che si dovrà occupare della sua interpretazione e relativa esecuzione. Al posto di Jazelle si sfrutta una modifica a Thumb-2, che offre un ambiente più flessibile e generale (non legato esclusivamente a Java).
Non sarà gradita a molti, invece, la soluzione rappresentata da TrustZone. Quanti avevano pensato di abbandonare x86 & affini a causa della famigerata tecnologia Trusted Computing o Palladium, confidando quindi nella “liberazione” grazie ad ARM, si ritroveranno già ad ardere nella brace del software “trusted“, magari senza neppure saperlo e addirittura vantandosi dell’acquisto.
Ma il futuro, checché se ne dica e ci si stracci le vesti, è rappresentato da questi meccanismi che non sono e non vanno visti esclusivamente in ottica “liberticida”. Per cui il mio personale consiglio ai “fanatici integralisti” è quello di farsene una ragione fin d’ora e accettare quella che sarà, alla fine dei conti, la realtà (che non è buia e triste come credono) con cui avremo tutti a che fare…
Piacevolissimo e sicuramente apprezzato da tutti è stato, invece, l’arrivo della superpipeline. A vent’anni dall’introduzione del primo esemplare della famiglia, e dopo che tante altre case sono saltate sul carro dell’esecuzione di più istruzioni per ciclo di clock, ARM compie un passo storico e sceglie la soluzione che, 12 anni prima, ha reso famoso il Pentium di Intel: eseguirne due in ordine.
Non che fosse impossibile farlo prima, sia chiaro, ma considerato il mercato di riferimento di Acorn prima e di ARM Ltd poi, la ricerca delle prestazioni elevate a tutti i costi non era certo uno dei suoi obiettivi, per cui ha preferito conservare le peculiarità della sua architettura (in primis un core ridotto all’osso: sui 35mila transistor circa), aggiornandola, estendendola, passando a processi produttivi migliori e innalzando il clock.
Certamente negli ultimi anni e con la sempre più larga e variegata adozione dei suoi microprocessori, è diventato sempre più pressante per lei aumentarne la velocità di esecuzione. Infatti uno dei suoi cavalli di battaglia, la pipeline corta (appena 3 stadi), era stato sacrificato già da qualche tempo sull’altare della frequenza del clock.
Si sono già viste, infatti, CPU con pipeline lunghe da 5 fino a 9 stadi, e sappiamo bene i problemi che ciò comporta: il rischio di uno svuotamento della pipeline con relativo nuovo caricamento delle istruzioni è sempre dietro l’angolo, e il decadimento prestazionale assicurato.
I Cortex segnano il record assoluto per questa famiglia, arrivando a ben 13 stadi. Tanti (troppi, direi io, considerata la sua storia), se pensiamo che un vecchio Athlon ne aveva 10, e 12 i più recenti Athlon64. Ciò ha richiesto l’introduzione di meccanismi di branch prediction efficaci (una global history di 512 entry, un branch target di 4096 a 2 bit, e un return stack di 8).
ARM dichiara il 95% di predizioni corrette: un risultato di tutto rispetto, che garantisce un ottimo livello di prestazioni raggiunte. A titolo di confronto, un Athlon raggiunge gli stessi risultati, ma con una branch history di 2048 entry, un branch target di altrettanti elementi, e un return stack di 12.
C’è però da dire che gli Athlon hanno raggiunto frequenze elevatissime (2,3Ghz con un modello della serie Barton) considerati gli appena 10 stadi e il fatto che si siano fermati a un processo produttivo “da preistoria” (130nm), mentre i Cortex-A8 (primi rappresentanti di questa famiglia) finora hanno toccato il Ghz, ma credo ci sarà ancora molto spazio per scalare in frequenza.
Tornando alla pipeline superscalare, l’implementazione in-order è molto semplice: la prima istruzione viene smistata alla prima ALU (la 0) e quella seguente alla seconda (ALU 1). Può sembrare una forte limitazione, ma entrambe le ALU possono eseguire qualunque operazione (a parte la moltiplicazione, affidata soltanto alla prima, ma si tratti di un’operazione rara) e possono accedere all’unità di Load/Store.
Si tratta di un design conservativo, ma anche molto semplice e poco costoso da implementare, che può garantire un buon miglioramento prestazionale specialmente se i compilatori faranno il loro dovere cercando di ridurre le dipendenze dei risultati e smistando le istruzioni alle due ALU in maniera ottimale.
Concludendo possiamo dire che con la famiglia Cortex-A8 ARM si rende sicuramente più aggressiva nei confronti di realtà più blasonate, che se prima dominavano incontrastate e indisturbate nei segmenti desktop e server, adesso devono fare i conti con una soluzione che presenta un eccellente rapporto fra prestazioni e costumi, e che in futuro, specialmente con le versioni multicore, è destinata a ritagliarsi sempre più spazio…







