
![]() Da giorni non si parla d’altro nei forum, nei blog e nei siti che in generale sono legati al mondo della programmazione. Considerato il nome della rubrica e la sete di conoscenza che caratterizza tipicamente i coder smanettoni, l’occasione, come si suol dire, è stata ghiotta.
Da giorni non si parla d’altro nei forum, nei blog e nei siti che in generale sono legati al mondo della programmazione. Considerato il nome della rubrica e la sete di conoscenza che caratterizza tipicamente i coder smanettoni, l’occasione, come si suol dire, è stata ghiotta.
Essendo poche e di carattere molto generale le informazioni che sono circolate, mi sono fiondato sul sito ufficiale ad attingere dalla documentazione fornita a corredo: Language Design, FAQ, Tutorial, Language Specification e infine Effective Go sono state rispettivamente le letture che mi hanno tenuto compagnia le nottate passate.
In attesa di poterci smanettare (purtroppo al momento gli unici s.o. supportati sono Linux e Mac OS X) per carpire qualche altro utile dettaglio che in genere viene fuori con un po’ di pratica, alcune considerazioni si possono comunque già fare…
Non si soffermerò troppo sulla sintassi, che può piacere o meno a seconda dei propri gusti personali (sui quali è sempre bene non discutere), ma c’è da dire che sicuramente molti avranno storto il naso. Gli affezionati di C & derivati, perché se ne discosta abbastanza, e gli altri perché… sembra il solito linguaggio ispirato al C.
A prima vista con le famigerate parentesi graffe per racchiudere i blocchi di codice, i classici operatori del C, il for, lo switch, lo struct, e i tipi di dato (int, float, e perfino i puntatori), sembra di trovarsi di fronte a un degno rappresentante della famiglia.
Passando però in rassegna tutto, si scopre come l’impronta sia fortemente pascaliana. I package richiamano sicuramente alla memoria Java, ma anche le unit del vecchissimo UCSD Pascal e dei ben più noti Turbo Pascal e Delphi di casa Borland. La dichiarazione delle variabili, fatta eccezione per l’assenza dei due punti che separano l’elenco delle variabili dal tipo, è spiccicata quella del Pascal (come pure l’operatore di “dichiarazione con inizializzazione”, di cui parlerò dopo, che usa il simbolo := ).
Per definire nuovi tipi si usa, in maniera similare, la keyword type; idem per le costanti. Il punto è virgola non è obbligatorio per terminare un’istruzione, ma è un separatore e può essere omesso in alcune occasioni. Attorno alle condizioni (nell’if, for, e switch) non sono obbligatorie le parentesi tonde, l’istruzione case può specificare un elenco di valori, e la dichiarazione dei parametri permette di raggrupparli per tipo.

Probabilmente avrò dimenticato qualcos’altro, ma l’obiettivo non era quello di una comparazione puntuale di ogni singolo costrutto sintattico messo a disposizione del linguaggio, i cui autori comunque ammettono senza problemi le loro fonti di ispirazione (C, Pascal, Modula, Oberon e principalmente; questi ultimi due della stessa famiglia del Pascal), anche se personalmente ho trovato qualche traccia di Python (slice, mappe/dizionari, funzione range per gli iteratori, assegnamento multiplo).
Sintatticamente, quindi, è un linguaggio che prova ad accontentare tutti, credo con scarsi risultati. La domanda che ci si pone di fronte a un nuovo linguaggio, però, è un’altra: quali innovazioni porta con sè? Quali nuovi concetti permette di esprimere che in precedenza non fosse possibile con altri?
Francamente non ne ho trovati. I punti di forza di Go sono ovviamente ciò che chiama goroutine, uno strumento più raffinato di ciò che in letteratura viene chiamata coroutine (una subroutine che si può lanciare e sospenderne l’esecuzione in maniera programmatica) da più di quarantanni e che si trova implementata in diversi linguaggi di programmazione in qualche forma (tasklet, generatori, iteratori, pipe, ecc.).
Mi piace comunque il modo in cui sono state implementate, con l’utilizzo di quelli che vengono definiti come channel per spedire e ricevere informazioni (sempre di un solo tipo) fra le varie goroutine, che richiamano alla mente il concetto di pipe (o del classico modello produttore / consumatore).

Trovo la sintassi semplice e concisa, e sarà apprezzata da chi smanetta con la parallelizzazione del codice. Anche se, come dicevo, sono concetti già noti e implementati in altri linguaggi (Stackless ha esattamente lo stesso modello, incluso il nome channel per i “canali” di comunicazione).
Altra caratteristica interessante è rappresentata dalle interfacce. Anche questo è un concetto ben noto, e permette di definire in maniera precisa un insieme di operazioni (metodi, per la precisione) per modellare delle funzionalità. Non è necessario, come in altri linguaggi, che un tipo di dato implementi specificamente un’interfaccia: è sufficiente che fornisca gli stessi metodi con lo stesso nome e signature per essere utilizzabile in qualunque posto dove viene utilizzata una determinata interfaccia.

Questo è sicuramente molto comodo, ma noto in quest’approccio una tendenza dei progettisti di Go a cercare di separare a tutti i costi la definizione dei tipi di dati dal codice che li riguarda, evitando accuratamente di parlare di ereditarietà anche quando a tutti gli effetti ci si trova davanti (un’interfaccia può riferirsi al suo interno ad altre interfacce, dalle quale “prende in prestito” l’elenco dei metodi definiti; in Go viene chiamato “embedding“).
Detto ciò, e per come si presentano, mi sfugge al momento il modo in cui è stata implementata questa caratteristica. E’ possibile che, tramite reflection (supportata da questo linguaggio), si riesca a risalire ai metodi di un certo tipo e, quindi, a referenziali dove l’interfaccia ne fa uso. Altra possibilità è che venga creata dal compilatore una tabella dei metodi se si accorge che un determinato tipo viene utilizzato in un’interfaccia. Entrambe le soluzioni hanno pregi, difetti, e relativi costi, ma il meccanismo è in ogni caso utile e flessibile.
Per quanto riguarda i tipi di dati, Go ne mette a disposizione parecchi di tipo intero, dagli 8 ai 64 bit, con o senza segno, un paio (con e senza segno) che hanno la stessa dimensione della word dell’architettura (quindi a 32 o 64 bit; al momento), e infine uno che ha la stessa dimensione dei puntatori (32 o 64 bit). E’ presente un tipo booleano, un tipo virgola mobile a 32 e 64 bit, e uno che può essere a 32 o 64 bit a seconda dell’architettura.
Ovviamente è possibile definire delle strutture di dati eterogenei (come le struct di C e derivati), ma più interessanti sono le stringhe (immutabili, come in Java, Python, e altri linguaggi), e gli array di cui è possibile definire degli slice (cioè prenderne un sottoinsieme) da passare a funzioni; non ne viene fatta una copia (come in Python, ad esempio), ma l’array viene referenziato internamente.
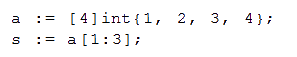
Estremamente utili sono poi le mappe, che permettono di definire degli hash/array associativi/dizionari tramite una coppia chiave-valore che può essere anche di tipo diverso. Sono presenti i puntatori, con una sintassi simile al C, ma la nota dolente per gli affezionati di questo linguaggio è che ne manca del tutto l’aritmetica. Quindi niente giochetti sommando interi per far avanzare puntatori: è roba “unsafe“, mentre Go si pone come linguaggio robusto che non vuole riproporre l’incubo dei segmentation fault.
E’ anche possibile definire costanti, tipi funzione (da passare usualmente come parametri), le funzioni anonime che tanti programmatori Java sognano per la versione 7 (tranne PGI-Bis, eccentrico utente della sezione Programmazione del forum di hardware upgrade), si possono passare argomenti in quantità e tipo variabile, ed è anche dotato di parecchi operatori.
Tornando ai punti di forza che vengono messi in evidenza dai creatori, fra questi c’è la velocità di compilazione che deriva dal fatto che il linguaggio non è molto complesso (ad esempio mancano le eccezioni, l’overloading di funzione ed operatori, i generic, l’ereditarietà) ma soprattutto dall’utilizzo dei package per modularizzare il codice. Niente file include come il C, quindi, ma è possibile compilare i package e importare velocemente quanto serve.
La modularizzazione del codice non è però, esclusiva di Go, ma è anch’esso un concetto molto vecchio (Modula e successori ne sono un’evidente testimonianza). Idem per i tempi di compilazione: linguaggi come Turbo Pascal prima e Delphi macinano milioni di righe in pochi secondi e implementano tante funzionalità che a Go mancano. Non serviva, quindi, un nuovo linguaggio per ottenere ciò che la storia ci ha consegnato già da un pezzo, anche se linguaggi come il C continuano imperterriti e masochisticamente a farne a meno aggrappandosi al preprocessore.
La compattezza nella definizione e assegnazione di valori alle variabili è un altro pallino che si porta dietro questo linguaggio. Chi lavora con gli oggetti, template / generic, array, ecc. sa quanto estremamente verboso possa risultare il codice che ne fa uso, visto che il tipo di dato dev’essere specificato sia nella dichiarazione della variabile che nella creazione dell’oggetto vero e proprio.
Go risolve il problema con l’operatore := (di pascaliana memoria), che richiede il solo nome della variabile a sinistra (per la sua dichiarazione), e ne recupera il tipo dall’espressione alla sua destra (per la creazione), utilizzando quello che tecnicamente viene chiamato type inference (anch’esso già utilizzato in altri linguaggi). Codice più corto, ma anche più leggibile, ed è sicuramente un pregio.
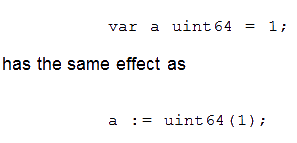
La velocità d’esecuzione è un altro tema molto caro ai creatori di Go, che sulla carta dovrebbe raggiungere prestazioni simili al C. Al momento manca una nutrita suite di benchmark, ma qualche appassionato si è cimentato e i risultati sono dir poco sorprendenti: proprio nell’uso delle go/coroutine Go mostra prestazioni di molto inferiori a Stackless (un branch di Python che elimina l’uso dello stack e implementa nativamente questo meccanismo), che al contrario di Go non fa uso di codice compilato nativamente, ma si affida a una classica Virtual Machine.
Sarà colpa dell’esempio (preso, comunque da un talk sul linguaggio tenuto dagli autori), o magari del progetto che è ancora relativamente immaturo (tanto che Google non lo utilizza ancora in produzione nei suoi sistemi), ma certamente non è una buona carta di presentazione per chi è interessato principalmente alla velocità. D’altra parte l’uso disinvolto dei tipi da parte di Go lascia pensare che una qualche forma di “dinamicità” sia in esso presente, e ciò ovviamente si paga.
Altra nota dolente è la robustezza del codice, anch’essa propagandata come caratteristica di punta del linguaggio. Go si propone spesso come safe, e per lo più lo è sicuramente, ma lascia aperte delle pericolose porte delegando al programmatore il rischio di alcune scelte. Se ciò può andar bene per il C, che di questa presunta “totale libertà” del programmatore ne fa anzi un vanto, non la ritengo accettabile per un linguaggio che si propone come “sicuro”.
Tre i punti critici rilevati finora. Uno dagli stessi autori, che ammettono senza mezzi termini che l’uso delle mappe non è thread-safe per questioni puramente prestazionali (leggasi: chi ne ha bisogno utilizzi dei lock). Un altro dal precedente link sui benchmark che sottolinea come l’uso delle interfacce non mette al sicuro da utilizzi impropri delle strutture manipolate (e fa l’esempio dell’ordinamento di un vettore, che però potrebbe cambiare proprio durante quest’operazione).
Un altro l’ho scovato leggendo la guida Effective Go, in cui vengono mostrati degli esempi di utilizzo del linguaggio, e riguarda le mappe. A quanto pare l’accesso a una mappa con una chiave non presente in essa causa il crash dell’applicazione. Viene, pertanto, suggerito un metodo alternativo e “sicuro”. Personalmente trovo incredibile che sia presente quello che ritengo un grave e pericoloso bug del linguaggio, per la facilità con cui può capitare.
Chiudo questa rassegna focalizzando l’attenzione su un altro dei punti di forza propagandati per questo linguaggio. Gli autori citano senza mezzi termini la programmazione di sistema e di come possa essere frustrante. Ma Go utilizza estensivamente un garbage collector; la gestione della memoria (dis/allocazione) è, infatti, interamente affidata a questo collaudato (utilizzato anch’esso da tempo in altri linguaggi) strumento.
Conoscendo i vincoli che si porta dietro questo settore, non mi trovo assolutamente d’accordo con quanto alacremente affermato. La programmazione di sistema richiede un fine e preciso controllo della gestione della memoria, che non può certo essere demandato a un garbage collector.
Mancano, tra l’altro, appositi handler che il C++, ad esempio, mette a disposizione proprio per avere un totale controllo di come dis/allocare la memoria in precise parti del codice. Non è, inoltre, prevedibile quando un oggetto sarà distrutto e le relative risorse rilasciate.
Concludendo, che dire di Go? Posto che siamo di fronte a un nuovo prodotto che maturerà in futuro (ricordiamoci che dietro c’è un colosso come Google), per il momento mi lascia un senso di déjà vu, quindi di qualcosa di già visto, vissuto. Per essere chiari, non ritengo sia il linguaggio che sconvolgerà il mondo e prenderà il posto di C/C++ o anche Java/C#.
Penso che, risolti i problemi di velocità delle goroutine che sembrano attanagliarlo, troverà la sua naturale collocazione nella realizzazione di server semplici da scrivere ma che devono sopportare elevati carichi di lavoro. Ma la mente a questo punto si ferma ad Erlang, che… esiste già da parecchio tempo e si presta molto bene allo scopo.
Déjà vu, appunto, ma almeno un’occhiata la consiglio ai programmatori C (non di sistema) che sono frustrati dalla povertà di questo linguaggio che ancora oggi presenta costrutti sintattici e tipi di dato da età della pietra informatica…







