
Con Alessio Di Domizio condividiamo la passione per i microprocessori, e non poche volte abbiamo affrontato il tema sia qui sia su Messenger, dove abbiamo speso fiumi di parole in chattate sui più svariati argomenti a esso attinenti.
Se parliamo molto è anche perché a volte non c’è piena sintonia, ma questo non è certamente un difetto, quanto un pregio, perché la diversa esperienza vissuta e i diversi punti di vista offrono ai lettori di AD una panoramica a più ampio raggio e una maggior ricchezza di informazioni, fortificando il proprio bagaglio culturale.
Su un punto, però, abbiamo trovato assoluto e pieno accordo fino dall’inizio: l’eccessivo consumo di potenza dei microprocessori della famiglia x86 rispetto ai ben più parchi ARM, tenendo ovviamente conto delle prestazioni…
Sull’argomento è intervenuto qualche giorno fa il CEO di VMWare (nota azienda che opera nel campo della virtualizzazione) a ribadire il concetto in maniera abbastanza dura, secondo il quale l’architettura x86 si porterebbe dietro anni di pezze (termine mio; lui parla molto più gentilmente di complessità) che fagocitano potenza (consumata).
Fin qui non afferma nulla che gli addetti ai lavori non sapessero già, ma tira anche in ballo l’architettura StrongARM (poi evolutasi in XScale) realizzata da Intel per entrare nel mercato dei dispositivi a bassa potenza, ma anche, a suo dire, poco profittevoli, che ha poi dismesso.
Infatti la divisione ARM fu poi venduta a Marvell qualche anno fa, ufficialmente per dedicare le risorse al suo core business (ovviamente gli x86) e alle tecnologie wireless.
Tutto bene, salvo poi tornare nuovamente in questo settore, presentando la sua piattaforma Atom e andando a ripescare il design del… buon vecchio Pentium (ma con l’ISA aggiornata, hyperthreading e altre migliorie), che è un processore in-order, anche se superscalare (dotato di due pipeline di esecuzione, quindi due istruzioni eseguibili entrambe in assenza di dipendenze, o ancora in thread diversi nel caso di Atom).
Questo perché, che Intel lo voglia ammettere o no, i dispositivi embedded, gli smartphone e i netbook sono tutt’altro che “poco profittevoli”, visto il giro d’affari enorme che ruota attorno a essi. Rispetto a soluzioni server sicuramente i guadagni sono di gran lunga inferiori, ma in questo campo è il gran numero di pezzi venduti a fare da “moltiplicatore” generando utili consistenti.
Insomma, un modello di business completamente diverso, ma molto interessante per una società che rimane pur sempre votata al lucro. E Intel con la sua forza non avrebbe certo avuto problemi a entrarvi prepotentemente, se non fosse che questi dispositivi non richiedono soltanto componentistica più economica, ma spesso anche un’autonomia molto più elevata e, di conseguenza, la necessità di consumi decisamente ridotti, vera piaga di x86 e dintorni.
Torniamo pertanto al nocciolo del problema citato dal CEO di VMWare, le cui radici affondano lontane nel tempo, risalendo fino al progenitore della famiglia, l’8086. Questa CPU fa parte della grande famiglia dei CISC, per cui è dotata di un set d’istruzioni a lunghezza variabile che le consente di “compattare” l’informazione maggiormente utilizzata, risparmiando quindi sulla dimensione del codice.
Al contrario i RISC sono dotati di un’ISA a lunghezza fissa, che racchiude istruzioni abbastanza semplici in un preciso spazio, e pertanto risulta una sorta di compromesso fra quelle maggiormente utilizzate e quelle più rare, richiedendo, quindi, uno spazio maggiore rispetto ai CISC.
Due filosofie completamente diverse, insomma, e ognuna rispettabilissima negli intenti e nel pensiero di chi le ha sviluppate, ma che pone i RISC in posizione di netto vantaggio per quanto riguarda la decodifica delle istruzioni, che risulta molto più facile e impiega una logica anch’essa ridotta. Meno logica di decodifica significa meno transistor, minor consumo di corrente, e meno calore generato.
Viceversa, i CISC richiedono una logica di decodifica tanto più complessa quanto più contorta risulta l’ISA del microprocessore, e l’8086 (ma soprattutto i derivati) penso sia secondo soltanto a un’altra creatura di Intel, lo iAPX 432 di ho parlato di recente proprio in questa rubrica.
A prescindere dall’ideologia che vi sta dietro, è pacifico che un processore possa eseguire i compiti richiesti dall’istruzione soltanto se è in grado di “conoscerla” per intero, cioé se è in possesso di tutte le informazioni necessarie per poterla “servire”. Sembra una cosa lapalissiana, ma tanto ovvia non è, perché per arrivarci può esserci molto lavoro dietro, ed è qui che si cominciano a marcare le differenze fra RISC e CISC.
In particolare, come si può vedere dal datasheet dell’ARM alla pagina A3-2 (68), lo schema della codifica delle istruzioni è estremamente semplice e abbastanza lineare. La dimensione utilizzata per gli opcode è sempre di 32 bit, per cui eseguitone il fetch il processore ha già tutto ciò che gli serve: sa cosa deve fare, quali registri sono coinvolti, se deve leggere o scrivere dalla memoria, se deve saltare, ecc..
E’ uno schema che si ritrova in maniera similare in tantissimi altri RISC, ed è talmente semplice che spesso nella fase di decodifica viene già eseguito anche l’accesso ai registri (vedi “Modern processor design” di Shen & Lipasti), risparmiando uno stadio della pipeline (quello che generalmente viene indicato come register access) proprio perché c’è talmente poco da “decodificare” che si può già pensare di “andare avanti” col lavoro.
Lo schema degli x86 è invece talmente complesso che non basta di certo una paginetta per descrivere tutti i casi e le famiglie di istruzioni, complice anche una codifica pseudo-causale delle stesse (in pratica gli opcode sono stati inseriti sostanzialmente “dove c’era spazio”; non trovo altra spiegazione logica alla cosa).
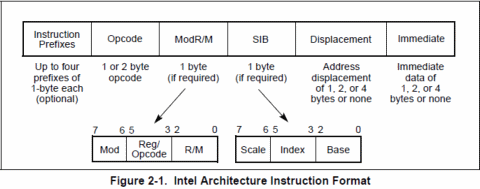
Da quello generale qui sopra riportato risulta già evidente che il processore è costretto a “sbirciare” in diversi “posti” per poter risalire sia alla lunghezza completa dell’istruzione che a tutte le informazioni che si trascina dietro. La parte più complicata rimane, comunque, quella iniziale, cioé dei prefissi delle istruzioni.
I prefissi sono dei particolari opcode che occupano esattamente un byte e che vengono utilizzati per alterare il normale funzionamento dell’istruzione vera e propria. Attualmente ne esistono di cinque tipi (un sesto, chiamato REX, è stato aggiunto da AMD con gli x86-64 e, se usato, deve necessariamente seguire gli altri prefissi, denominati spesso legacy):
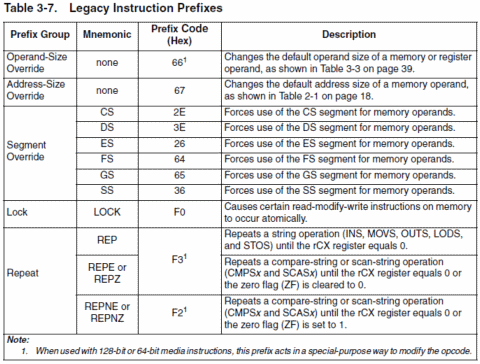
Ogni istruzione x86 può specificare fino a quattro prefissi (quello di LOCK e quelli di ripetizione sono mutuamente esclusivi: non possono essere usati entrambi nella stessa istruzione) in totale (cinque per x86-64, come già detto) e in qualunque ordine.
Ma se ai tempi dell’8086 ciò era facilmente implementabile e a un costo irrisorio (le istruzioni richiedevano anche diverse decine di cicli di clock; inoltre i prefissi “abilitavano” precise caratteristiche), oggi che le prestazioni si “misurano” col numero di istruzioni eseguite per singolo ciclo di clock questo schema risulta non soltanto obsoleto, ma particolarmente castrante, richiedendo non poche risorse già soltanto per la decodifica delle istruzioni.
Giusto per rendere l’idea, Jon Stokes nel suo “Inside the machine” parla di una stima pari a circa il 30% dei transistor per la sola logica di decodifica delle istruzioni del primo Pentium (P5), e di ben il 40% per il suo successore, il PentiumPro (P6). Numeri che sono a dir poco impressionanti, in quanto buona parte del chip sono dedicati esclusivamente per questa funzionalità.
Tra l’altro si tratta di una circuiteria che non si può certo “spegnere”, come si fa nei microprocessori più moderni (cache L2, ALU, FPU, unità SIMD, ecc.), perché se si devono eseguire le istruzioni (!), queste devono per forza di cosa essere decodificate. Per cui quest’area risulta costantemente stressata, affamata di corrente e, di conseguenza, particolarmente “calda”.
E’ facile comprendere a questo punto perché gli ARM, come tanti altri RISC, siano in netto vantaggio rispetto agli x86 dal punto di vista dei costi e, soprattutto, dei consumi: essendo del tutto trascurabile la logica di decodifica, viene a mancare un elemento che incide pesantemente nel bilancio.
Per correttezza preciso che ciò è tanto più vero quanto più piccolo è il chip, cioé rispetto al numero di transistor utilizzati per realizzarlo. Questo perché, una volta raggiunto lo “stato dell’arte” per quanto riguarda la circuiteria di decodifica, non si assiste più a un aumento lineare dei transistor utilizzati allo scopo, ma, sembra incredibile, avviene una diminuzione in percentuale.
Ciò è facilmente spiegabile dal fatto che col passare del tempo il maggior numero di transistor viene impiegato per migliorare e/o aumentare le unità di calcolo e la dimensione e/o efficienza delle cache, mentre l’area di decodifica viene leggermente aggiornata per supportare eventuali nuove istruzioni aggiunte all’ISA.
Quindi si tratta di una zona del chip che tenderà a occupare sempre meno spazio e risorse, se consideriamo che il Pentium era costituito da circa 3 milioni di transistor, e il PentiumPro da 5,5, mentre da poco abbiamo superato la soglia del miliardo di transistor che, però, sono utilizzati nella stragrande maggioranza per le cache (in particolare le abbondanti L3).
Con Atom, invece, Intel ha dovuto effettuare una sorta di marcia indietro, presentando un chip realizzato con 47 “miseri” milioni di transistor, perché l’obiettivo era quello di offrire una soluzione a basso costo e, soprattutto, con bassi consumi; condizioni entrambe necessarie per attaccare il nascente segmento dei netbook, ma anche quello degli smartphone e in generale dei dispositivi embedded e SOC.
E’ chiaro che, con questi numeri in gioco, una sezione di decodifica delle istruzioni che si porta via un po’ di milioni di transistor diventa tutt’altro che trascurabile nel bilancio economico, ma soprattutto energetico (come dicevo prima, è un’area che non si può certo “spegnere”).
Per confronto e andando a guardare in casa ARM, vediamo che il solo core dell’ARM7TDMI (quindi senza considerare cache, DSP, unità SIMD, ecc.) è accreditato per 36mila (sì, non milioni, ma migliaia) transistor, e che le tipiche implementazioni che troviamo in giro stanno sull’ordine delle centinaia di migliaia di transistor (100mila per il modello utilizzato nel Nintendo DS, e soltanto 50mila per il Cortex M0, modello economico e specificamente orientato al bassissimo consumo).
Ovviamente le soluzioni più performanti che da qualche tempo hanno cominciato a fare capolino integrano cache di dimensioni elevate, MMU, DSP e/o unità SIMD, e altro, ma non arriviamo sicuramente ai livelli dell’Atom di Intel, che si porta dietro tutti i difetti dell’ISA x86.
Insomma, quella dei consumi è certamente una battaglia persa in partenza per Intel, a parità di tecnologie costruttive e di prestazioni, con l’unico vantaggio “di spessore” rappresentato dal fatto che, nel bene e nel male, x86 rimane comunque la più diffusa e utilizzata architettura da chi sviluppa il software.
Perché, quindi, Intel ha buttato via le soluzioni ARM (StrongARM e XScale) che aveva realizzato proprio per il segmento dei dispositivi a basso consumo? Il CEO di VMWare, come già riportato, sostiene che si è trattato di errore strategico e che Atom nasce sostanzialmente per “porvi rimedio”.
Io ho un’opinione completamente diversa. Intel ha ceduto a Marvell la divisione ARM nel giugno 2006, mentre ha presentato Atom a marzo del 2008. Troppo poco il tempo per “accorgersi dell’errore” e avere quello sufficiente per “porvi rimedio”, studiando una soluzione ad hoc.
Evidentemente Atom era un progetto già in lavorazione, che presentava delle ottime prospettive sul piano dei costi e in particolare su quello dei consumi, e Intel ha pensato bene di sbarazzarsi di una divisione che sarebbe entrata in concorrenza col suo nuovo gioiello, che tra l’altro portava in dote l’architettura che le ha regalato il successo.
Non so a voi, ma a me i conti tornano. Perché non si sviluppa un’architettura come quella di Atom nel giro di pochissimi mesi, per quante similitudini possa avere col vecchio Pentium e per quanta tecnologia sia stata “prelevata” dai modelli più recenti.
Difficile però prevedere quale soluzione dominerà il segmento su cui si va a inserire Atom. Se dovessi guardare ai soli consumi, come ho già detto, Intel non avrebbe scampo: è impensabile che possa rivaleggiare con ARM.
Ma Atom ha dalla sua l’ISA x86, con tutta la montagna di software che gira già senza bisogno di andare a scomodare compilatori e, soprattutto, software house. In particolare ciò vale per colossi come Microsoft, ben poco incline a tirare fuori un’altra versione di Windows (e questo Intel l’ha già potuto sperimentare sulla sua pelle col “progetto” Yamhill).







