La scorsa settimana eravamo rimasti con l’atroce dubbio se fosse possibile o meno abbassare il valore di Vdd al punto da renderlo confrontabile con quelli di soglia dei due mos dell’inverter, senza rischiare di rallentare la propagazione dei segnali o, peggio, causare l’instabilità del sistema. Vedremo se e come sarà possibile e che tipo di impatto avrà questa eventuale diminuzione sulle prestazioni del sistema. Andiamo, però, con ordine.
Avevamo parlato della possibilità di gestire il clock di un domain o di un core tramite il cosiddetto clock gating; questa settimana vedremo come le tecniche di clock gating che, da sole, non sono sufficienti a garantire un buon risparmio energetico perchè non “spengono” l’alimentazione del circuito e perché, comunque, ne aumentano la complessità (si ricordi che ad ogni incremento della complessità circuitale, per quanto piccolo, a parità degli altri parametri aumenta in proporzione anche il consumo) sono affiancate da tecniche di power gating, ovvero tecniche che permettono di operare sulle tensioni di alimentazione dei circuiti allo stesso modo in cui il clock gating opera sulle frequenze.
Facciamo un passo indietro: la scorsa settimana avevamo parlato di clock gating, spiegando che si tratta di tecniche atte a “togliere” il clock a circuiti non coinvolti nelle operazioni in un determinato ciclo. In effetti esistono altre tecniche di controllo della frequenza che non si limitano a fare operazioni di tipo “on/off” ma che permettono di regolare dinamicamente la frequenza a seconda dei carichi di lavoro di un determinato circuito agendo sui PLL (phase locked loop circuit) e sui segnali di riferimento attraverso dei moltiplicatori di frequenza (come accade, ad esempio, nelle moderne gpu quando passano dal 2D al 3D e viceversa).
Analogamente è possibile agire sulle tensioni facendo uso di moltiplicatori di tensione. In tal modo è possibile variare in maniera dinamica frequenza e tensione di un intero chip o di parti di esso, anche in maniera differente e indipendente tra di loro, a seconda dei carichi di lavoro. Implementazioni del genere le troviamo nella tecnologia messa a punto da Transmeta e denominata LongRun, in cui la Vdd varia da 1,1 a 1,6V con intervallo suddiviso in 32 step e la frequenza varia da 200 a 700 MHz con incrementi di 33 MHz. La cpu va in stallo per un tempo inferiore ai 20 ms nella fase di PLL relock.
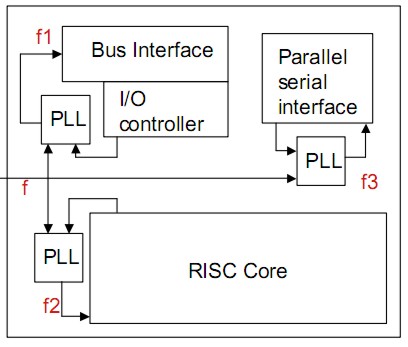
Un’altra interessante prospettiva è quella di avere più domini in frequenza con valori di PLL differenti come si vede in figura
in cui f è la frequenza del sistema e f1, f2 ed f3 sono maggiori di f e tutte differenti tra loro. Anche in questo caso è possibile operare in modo da avere variazioni dinamiche della frequenza nei vari circuiti. Un’evoluzione del precedente schema è quella denominata GALS (global asynchronous local synchronous)
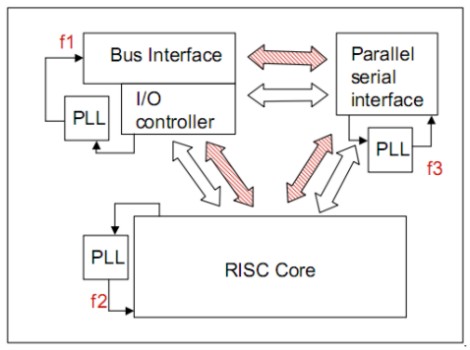
Questo tipo di architettura fa uso di generatori di clock locali e indipendenti; in tal modo si hanno circuiti locali di tipo sincrono ma comunicazioni tra i vari blocchi di tipo asincrono basate su protocolli di tipo handshake. Questo tipo di architettura è sicuramente più resistente allo skew di quella vista precedentemente, permette una riduzione delle potenze in gioco e consente di impostare il clock dei vari circuiti in maniera del tutto indipendente migliorando il bilancio energetico del chip.
Veniamo, ora, al problema connesso alla riduzione di Vdd; come detto, quando il suo valore inizia a diventare comparabile con quello delle tensioni di soglia dei transistor il circuito inizia a “girare a regimi più bassi”, come un motore al quale si toglie potenza. Un andamento qualitativo del fenomeno è riportato in figura
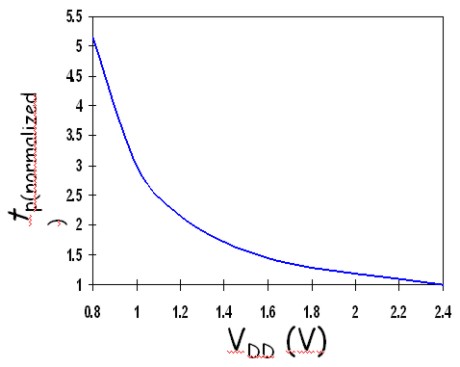
dove tp rappresenta il tempo necessario ad effettuare lo switch dei transistor (in particolare del pmos), mentre una prima grossolana analisi quantitativa si può fare tramite la seguente equazione che tiene conto solo di alcune delle variabili che influiscono sul ritardo nella commutazione al variare di Vdd
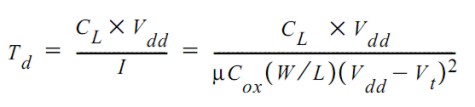
da cui si vede che al diminuire di Vdd e all’avvicinarsi del suo valore a quello della tensione di soglia dei due transistor, se da un lato cala il numeratore, dall’altro diminuisce molto più velocemente il denominatore, facendo dilatare il tempo Td di ritardo nella commutazione. Una soluzione potrebbe essere qualla di utilizzare tensioni di soglia inferiori, ma si tratta di una soluzione che presenta due inconvenienti: un aumento del rumore e, quindi, della affidabilità del circuito e, soprattutto, un aumento delle correnti di sottosoglia che provocano un aumento della dissipazione di potenza statica. Nella figura in basso, sono riportati gli andamenti di Td, al variare di Vth (tensione di soglia), per vari valori di Vdd
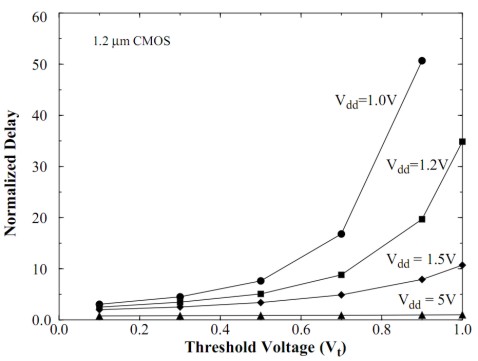
Uno degli accorgimenti usati dai progettisti è quello di riservare ai critical path (che richiedono tempi intrinsecamente superiori) valori di Vdd elevati e di utilizzare valori inferiori di Vdd sugli altri circuiti; il principio ispiratore è: evitiamo di rallentare quei circuiti che sono già più lenti degli altri e, se proprio si devono abbassare le potenze, rallentiamo i circuiti più veloci in modo da tentare di bilanciare le velocità di elaborazione dei vari stadi e minimizzare i cicli di idle di ciascuno.
Ovviamente non è questo l’unico accorgimento che viene preso ma prima di parlare di altro è opportuno parlare brevemente delle altre due componenti della potenza dissipata.
Riprendiamo, per un momento, la nostra equazione relativa al bilancio energetico di un chip
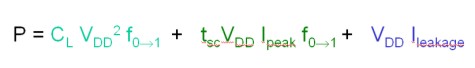
Il motivo per cui è opportuno, se non necessario, fare cenno alle due residue componenti del bilancio totale della potenza dissipata in un chip, dal momento che si stanno per introdurre alcune delle soluzioni adottate per ridurre la Vdd, è evidente da questa equazione, da cui risulta che tutte e tre le componenti della potenza sono dipendenti da Vdd.
La potenza di cortocircuito, anch’essa potenza dinamica, è, come quella di commutazione, dipendente dalla frequenza del circuito. Quando Vtn < Vin < Vdd – |Vtp|, dove Vtn e Vtp sono le tensioni di soglia dell’nmos e del pmos rispettivamente, durante il periodo in cui avviene la commutazione entrambi i transistor sono in conduzione e si forma un cortocircuito tra Vdd e ground.
Il termine tsc (tempo di cortocircuito) tiene conto proprio della durata dell’intervallo di tempo in cui si crea il cortocircuito tra tensione di alimentazione e ground. Poiché la corrente di cortocircuito raggiunge il valore massimo quando il periodo di transizione sul gate dove è presente il segnale di input è più lungo di quello in output, perché l’inverter resta in corto per un intervallo di tempo maggiore, un modo per minimizzare la potenza di cortocircuito è quello di fare in modo che le transizioni in input e in output abbiano la stessa durata. In tal caso, si può arrivare a ridurre la potenza di cortocircuito a meno del 10% del valore della potenza totale dissipata.
Un modo per eliminarla del tutto, invece, è quello di rendere Vdd < Vtn + |Vtp|. In tal modo si riesce ad evitare che entrambi i transistor siano contemporaneamente in conduzione, anche durante il transitorio.
La terza componente è quella relativa alla potenza di leakage che è una potenza di tipo “statico” ed è formata, a sua volta, da diverse componenti, tra cui: reversed biased p-n junction, sub treshold leakage, DIBL (drain induced barrier lowering) leakage, oxide leakage, hot carrier tunneling effect, ecc. In particolare faremo un breve cenno alle prime due, non dimenticando, però, che all’avvicinarsi del processo produttivo a 11 nm, anche quella dovuta ad effetto tunnel, e non solo quella, va assumendo un peso via via crescente.
Si è già accennato al fatto che al diminuire di Vth, ovvero delle tensioni di soglia dei transistor, necessarie per mantenere una elevata velocità di commutazione al diminuire della Vdd, cresce il leakage dovuto alle correnti di sottosoglia. Il primo termine, invece, dipende dal fatto che, quando uno dei due trasistor è in conduzione, nell’altro si forma una tensione inversa con il bulk, per cui si ha una densità di corrente parassita che scorre all’interno del dispositivo. Ad esempio, quando il pmos è in interdizione, tra il drain e il bulk c’è una tensione pari a -Vdd e la relativa corrente di leakage è pari a ILeakage = Ad*Js , dove Ad è l’area del drain e Js la densità di corrente di leakage. Il valore di ILeakage per un tipico cmos può variare di 1 a 5 pA/u^2 a 25°C e raddoppia ogni 9 gradi di aumento della temperatura.
La potenza di leakage rappresenta una parte sempre più importante del bilancio dell’intero chip (a 65 nm rappresenta quasi il 45%) ed è, inoltre, l’unico termine sempre presente, anche quando un circuito, sotto tensione, non commuta.
Uno dei modi visti per ridurre la potenza dissipata in un circuito è quello di evitarne la commutazione qualora non fosse necessaria; per far ciò, si ricorre al cosiddetto clock gating. Abbiamo anche fatto cenno alla possibilità di regolare frequenza e tensione in base alle esigenze del momento, all’interno di determinati range. Ora faremo un breve cenno alla possibilità di togliere del tutto tensione ad un circuito, qualora questo non fosse coinvolto in una determinata elaborazione.
Per fare questo in maniera selettiva e con una granularità più fine possibile, si suddivide il chip in aree creando quelle che, in gergo, sono definite voltage island. Queste voltage island permettono non solo di impostare differenti livelli di tensione per le singole “isole” ma anche di decidere se e a chi togliere tensione e di modificare dinamicamente la tensione all’interno di ciascuna area. Nella seguente figura è riportato un esempio di SoC (system on chip) dotato di voltage island
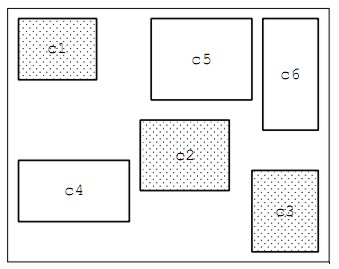
con le varie isole impostate con le seguenti tensioni

In questo modo è possibile impostare dinamicamente la tensione area per area o toglierla del tutto dove non serve, tramite power gatin su una o più aree. In tal modo è possibile ridurre sia le componenti dinamiche che quelle statiche della potenza dissipata e rientrare nel “budget di potenza” prefissato, come mostrato nella seguente figura
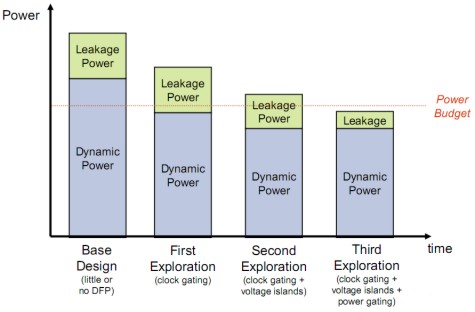
Ovviamente, anche il power gating non è la soluzione finale, in quanto, a sua volta, non è esente da problemi. Mi limito a citarne alcuni:
il tempo necessario a “riavviare un circuito e a riallinearne le frequenze di funzionamento una volta “spento”
in caso di switch off dell’intero chip, comprese le cache interne, al riavvio sono necessari una buona dose di potenza e di tempo, nonchè un enorme impegno del bus, per riempire di nuovo le cache.
Nel caso di microprocessori multicore, con cache L2 o L3 esterna, quest’ultimo inconveniente ha un impatto molto meno “oneroso”, poichè, in caso di spegnimento di uno o più core, ma non dell’intero chip, la cache condivisa resta alimentata (in quanto serve i core rimasti attivi).
Non mi addentro ulteriormente nel discorso relativo al power gating ed alle sue tecniche di implementazione per motivi di spazio e per non annoiare oltre il necessario i non addetti ai lavori (mi scuso, invece, con gli addetti ai lavori che avrebbero gradito, magari, ulteriori approfondimenti) . Faccio, invece, una breve digressione su ciò che ci riserva l’immediato futuro.
Al diminuire ulteriore delle dimensioni dei transistor, gli attuali processi non saranno più sufficienti a contenere il leakage; col decrescere della lunghezza del canale source-drain diminuisce il controllo del gate sullo stesso e si va incontro all’aggravarsi degli effetti da, cosiddetto, canale corto (SCE) che conducono ad un significativo incremento della corrente inversa di drain e alla impossibilità di effettuare ulteriori scaling a causa dell’esplodere della potenza di leakage. Il diminuire, invece, dello spessore del canale, induce un aumento del leakage da effetto tunnel, mentre l’elevato livello di drogaggio, tanto più necessariamente alto quanto più si degrada il controllo del gate sul canale stesso, fa diminuire la mobilità dei portatori e aumentare il leakage della giunzione source-drain. Questi sono solo alcuni degli effetti indotti dal diminuire delle dimensioni e il motivo per cui la potenza di leakage sta diventando uno dei termini più importanti nel bilancio della potenza complessiva di un chip e lo sarà sempre più in futuro.
Per contenere alcuni di questi effetti, al momento, oltre alle tecniche di riduzione della Vdd ove possibile (non critical path, ad esempio) e alle tecniche di power gating o variazione dinamica della tensione di alimentazione, sono stati realizzati strati isolanti con materiali high-k ed è stato fatto ricorso a tecniche atte a velocizzare il moto delle cariche in direzioni ben precise, come, ad esempio, la SSOI (ossia strained silicon on insulator),
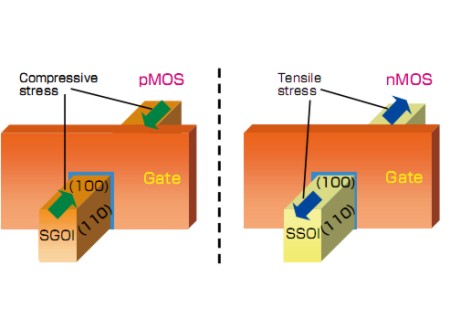
grazie alla quale si riesce ad avere una mobilità di cariche fino a due volte superiore rispetto alle tecniche tradizionali.
Col passaggio a 32 nm prima ed a 22 nm in seguito, queste tecnologie non saranno più sufficienti e si dovrà ricorrere ad altre che permettano un maggior contenimento dei fenomeni che conducono al leakage. Tra questi, vale la pena di segnalare i Multigate MOSFET che rappresentano la tecnologia più promettente sia a livello di efficacia che di facilità di implementazione. Tra questi, i double gate e i multigate FinFET
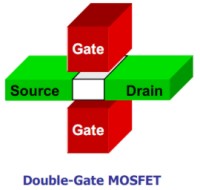
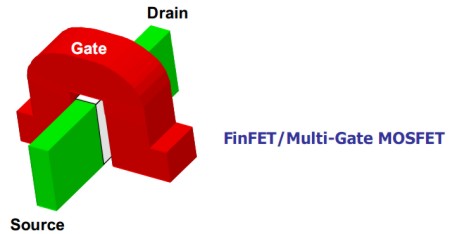
Questi transistor, detti anche transistor 3D, sfruttano la presenza di più gate per avere un elevato controllo sul canale S-D, in modo tale da permettere la riduzione del drogaggio dello stesso, aumentando la mobilità delle cariche, riducendo le capacità parassite e l’accoppiamento source-drain nella regione di sottosoglia. I FET di tipo multigate possono essere realizzati su substrato bulk o di tipo SOI e pososno essere accoppiati a tecniche di flip flop skewing per minimizzare il leakage nei circuiti sequenziali.
Questi ultimi sono dei flip flop in cui determinati transistor sono stati sostituiti con altri con canali di lunghezza maggiore, in modo da ridurre il leakage da SCE; il contro è l’introduzione di un ritardo nei tempi di risposta del circuito, ritardo che si può contenere entro valori accettabili scegliendo in maniera opportuna i transisotr da sostiuire.
Mi limito a postare alcune immagini, la prima delle quali riporta le diminuzioni del leakage e le altre due i ritardi introdotti nelle varie transizioni
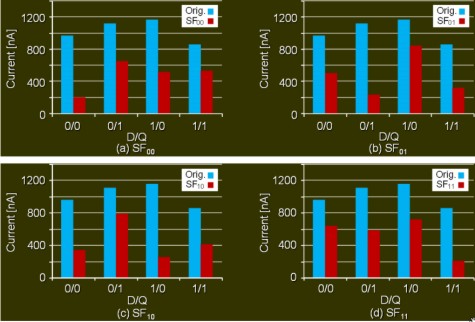
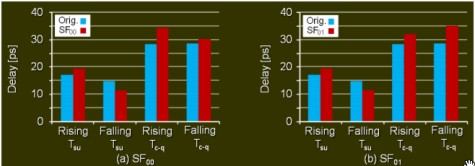
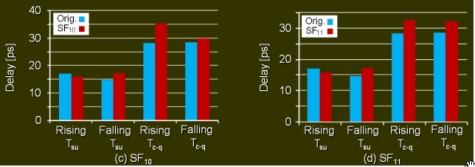
Con queste tecnologie sarà possibile, a breve, avere un buon controllo del canale anche a valori di Vth inferiori rispetto agli attuali e, di conseguenza, sarà possibile tornare a far scendere il valore di Vdd in maniera più sostanziosa di quanto (poco a dire la verità), non si riesca a fare ora, senza incorrere nel rischio di avere logica instabile o velocità di commutazione più bassa. Come si vede, a fronte di una contenuta diminuzione della velocità di commutaizone si ha un buon contenimento del leakage.
Prima di chiudere questa breve e, per forza di cose incompleta panoramica su argomenti piuttosto complessi, voglio fare un breve cenno, che servirà anche da introduzione per un prossimo articolo, anche al peso che ha la memoria interna sulla potenza complessiva dissipata da un chip. In questo articolo avevamo visto come le meorie interne hanno acquisito sempre più importanza e occupano una parte sempre maggiore nei die dei microprocessori. Se consideriamo un grossolano schema a blocchi di un processore
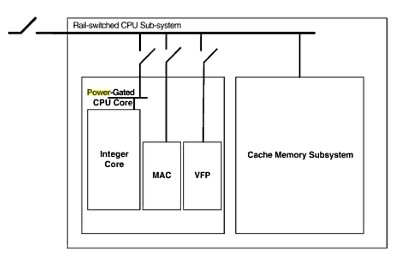
e lo stato dei suoi blocchi interni
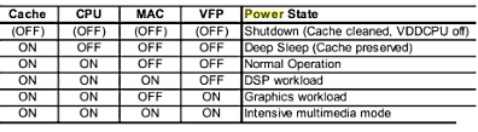
vediamo che la cache è l’unica ad essere sempre in stato di ON (tranne quando la cpu è spenta). Di conseguenza, il risparmio energetico deve passare anche attraverso una buona gestione della memoria. Sappiamo che, a partire da 45 nm, al diminuire di Vdd ed al suo avvicinarsi alla tensione di soglia, si degrada lo static noise margin (SNM) di una cella di SRAM 6T di tipo standard. Questo obbliga a cercare delle soluzioni che permettano alle memorie interne di lavorare sottosoglia senza perdere efficienza ed affidabilità. Tra le soluzioni al momento percorribili, le celle di tipoi 6T single ended, le celle 8T e varie configurazioni di celle 10T, le uniche in grado di ridurre anche il leakage.
In un prossimo articolo vedremo un po’ più in dettaglio cosa provoca il degrado del valore di SNM e come lavorano le SRAM citate, nonchè daremo anche uno sguardo a cosa si prospetta in futuro con l’adozione di T-RAM e Z-RAM.







