Prima di iniziare a parlare dell’argomento di questa settimana, vorrei spendere qualche parola su quella che è stata definita “legge bavaglio”, ovvero il decreto Alfano. Non entro nel merito della legittimità di una siffatta normativa su cui, eventualmente, avrà modo di pronunciarsi un tribunale. Certo, il fatto che la Cassazione non più tardi di quattro mesi fa abbia escluso la possibilità di omologazione di un forum o di un blog o di un social network ad un organo di stampa ufficiale, lascia perplessi circa la legittimità di un provvedimento che, di fatto, applica proprio a blog, social network e forum, leggi pensate esclusivamente per i mezzi di informazione ufficialmente riconosciuti.
E ancora più perplessi lascia il fatto che sommando la sentenza della Cassazione e il decreto Alfano, che fa riferimento ad una legge del 1948, promulgata per la carta stampata, viene fuori un quadro in base al quale i mezzi di comunicazione che fanno uso della rete hanno gli stessi obblighi ma non gli stessi diritti di altri soggetti, ivi compresi, eventuali finanziamenti pubblici (sulla illiceità dei quali mi sono più volte pronunciato). Nonostante queste premesse, non è neppure questo il succo del problema; il vero problema è l’atteggiamento che sta alla base di questa nuova/vecchia normativa.
Chi l’ha definita legge bavaglio ha ragione, indipendentemente dal fatto che questa normativa ottenga o meno il suo scopo. Ha ragione perchè nello spirito del legislatore mi sembra di cogliere un atteggiamento intimidatorio nei confronti di qualcosa che non è in grado di controllare, che mira a trasformare blogger e amministratori di forum in altrettanti cani da guardia spaventati. Questo perché se da un lato è facile lottizzare giornali e reti TV, molto più complesso, se non impossibile è cercare di controllare ciò che la gente dice in piazza e per le strade; e adesso che internet è, per molti versi, diventato una piazza virtuale, anzi, milioni di piazze virtuali, coloro che siedono nelle stanze del potere hanno finalmente capito, con notevole ritardo, che il confronto, seppure virtuale e il pluralismo, permessi dalla rete, sono i migliori antidoti alle pratiche di controllo del pensiero.
Se, quindi, da un lato ha ragione chi ritiene che la rete abbia bisogno di regole per evitare pericolose derive, dall’altro ha altrettanta ragione chi pensa che non sia questa classe politica, troppo vecchia indipendentemente dall’anagrafe, a poter dare delle regole ad un mondo di cui non arriva neppure a sfiorare le dinamiche.
E ora veniamo all’argomento del giorno
Dopo aver fatto cenno ad alcuni tra i principali limiti delle attuali tecnologie del silicio e aver introdotto i principi alla base della scelta delle architetture multicore e multithreaded, questa settimana vorrei tornare sul discorso relativo al risparmio energetico nella progettazione dei microchip. In questo articolo e nel successivo, stimolato anche dai post di qualche utente, tra cui pleg, a cui va un ringraziamento particolare, intendo fare una sorta di sintesi e di integrazione dei due articoli precedenti, con considerazioni di carattere energetico ed uno sguardo a cosa c’è in cantiere nell’immediato futuro.
Finora abbiamo commentato alcuni dei limiti della tecnologia del silicio e abbiamo posto l’accento sulle componenti principali delle potenze in gioco in un chip: leakage, cortocircuito e potenza dinamica da carica e scarica delle capacità parassite in particolare.
Una ipotetica equazione che tenga conto di queste tre componenti si potrebbe scrivere nel modo seguente
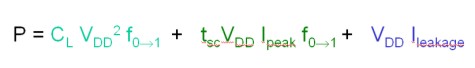
dove il primo termine rappresenta la potenza dinamica dovuta alle capacità parassite, il secondo la potenza di cortocircuito e la terza quella dovuta ai fenomeni di leakage. In un moderno circuito elettronico il primo dei tre termini è sicuramente l’elemento preponderante, seguito dal secondo e dal terzo rispettivamente ma non è facile fare stime quantitative se non si tiene conto di alcuni fattori, come ad esempio, il design del chip, il numero di transistor e le varie ottimizzazioni a livello hardware e software. Tutti e tre insieme rappresentano la totalità della potenza in gioco in un chip e , in particolare, in chip di tipo VLSI, quasi il 50% di questa potenza è dovuta a componenti di tipo parassitario; l’obiettivo è quello di tenere sotto controllo la crescita di queste ultime e, dove possibile, tentare di ridurne l’incidenza.
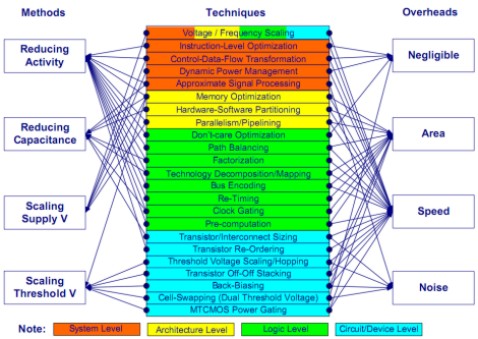
Volendo schematizzare il tutto con una tabella, si potrebbe pensare a qualcosa del genere
In questo articolo focalizzeremo l’attenzione, in particolare, sulla prima delle tre componenti di potenza dissipata elencate in precedenza e sulle misure principali atte a ridurne l’incidenza sul bilancio energetico complessivo di un chip.
La prima di queste, appunto, è la potenza dinamica derivante dagli accoppiamenti indesiderati che si vengono a formare tra transistor contigui o tra linee elettriche, con le relative conseguenze. In parte, l’argomento è stato già trattato e, per l’accoppiamento capacitivo tra linee elettriche, in particolare, rimando all’articolo, linkato in precedenza, sui limiti delle tecnologie del silicio; qui ci soffermeremo su alcuni aspetti, riguardanti il cosiddetto transistor latch-up, che in quella sede erano stati solo accennati o, addirittura, trascurati. Nella figura in basso, è riportato un caso tipico di circuito che, in determinate condizioni, è soggetto ad accoppiamento capacitivo di tipo parassitario
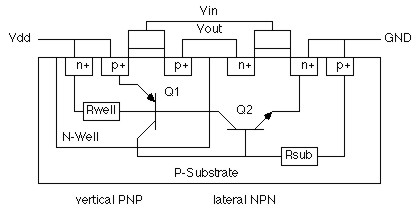
In questo schema, nel momento dello switch dell’inverter, per un breve periodo, entrambi i transistor sono in conduzione, motivo per cui si vengono a creare una sorta di transistor bipolari parassiti che danno luogo ad accopiamenti capoacitivi indesiderati che hanno, nell’esempio di figura, come armature il collettore del pnp ed l’emettitore dell’npn. Questo fenomeno, noto anche come transistor latch-up, può portare ad errori nella computazione (a causa delle correnti parassite generate) e, nella peggiore delle ipotesi, quando le potenze in gioco diventano elevate, alla rottura del dispositivo (s’immagini questo stesso meccanismo innescato su milioni di transistor nello stesso tempo). Per combattere l’insorgere di questo fenomeno, si percorrono diverse strade. La più diretta è quella che mira ad impedirne l’insorgere con delle “barriere fisiche”, delle trincee o degli anelli, come quello in figura
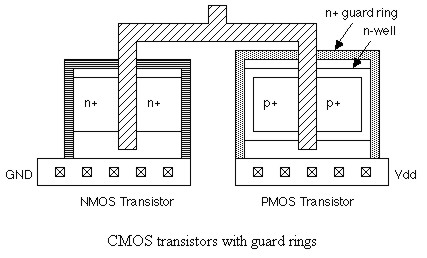
in modo da isolare fisicamente transistor contigui. Questa strada è l’unica a garantire un perfetto isolamento delle reti pmos ed nmos nella fasi di pull up e pull down ma, anch’essa, non è esente da “difetti”. Il più evidente di tutti è che queste trincee o questi anelli utilizzati, occupano spazio e riducono la densità circuitale.
Altre strade per ridurre gli accoppiamenti parassiti si basano su considerazioni di tipo probabilistico: ovvero, si fa in modo che i trasistor di un circuito non commutino tutti assieme per ridurre al minimo la possibilità di accoppiamenti parassiti e ridurne l’impatto sulle prestazioni del chip. Per far ciò, si ricorre a clock e/o data gating, sia a livello locale, ossia di banchi di flip flop, che a livello più ampio (interi domain o core, nel caso di architetture multicore). Queste tecniche inibiscono la commutazione di quei circuiti che non sono coinvolti nella computazione in quel determinato ciclo di clock; si tratta, pertanto, di tecniche che agiscono con “granularità fine”, sia temporale che spaziale, poichè è possibile togliere, ad esempio, il clock in un ciclo e riattivarlo nel successivo. Queste tecniche non prevedono lo “spegnimento” del circuito che, di conseguenza, continua a restare alimentato. Anche il clock gating non è una soluzione esente da difetti: innanzitutto introduce una complessità a livello di logica di controllo, in quanto è necessario dotare i circuiti di dispositivi di controllo della frequenza che abilitino e disabilitino il clock quando richiesto. Questo rende problematica l’adozione di tecniche di clock gating a livello di singolo trasistor ma anche poco fattibile a livello di “microcircuiti”. Il clock gating diventa, invece, applicabile a livello di “macrocircuiti”, come mostrato nella sottostante immagine, dove si vedono una serie di clock domain regolati ciscuno in modalità sincrona, comunicanti tra loro attraverso canali di tipo asincrono. Questa è una situazione piuttosto comune soprattutto in circuiti particolarmente complessi.
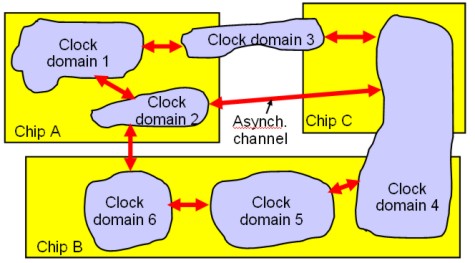
A titolo di esempio, un Pentium 4 conteneva centinaia di clock gated domain simili a quelli in figura.
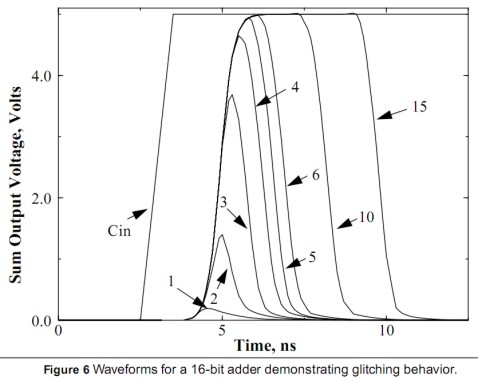
L’aumento di complessità circuitale non è l’unica controindicazione all’applicazione del clock gating a livello di microcircuito o di singolo transistor; un altro problema è che il circuito di controllo del clock introduce una serie di leggeri ritardi nelle trasmissioni; la differenza tra questi ritardi è detta skew e risulta, a sua volta, fonte di dispersione di potenza, potendo generaredelle transizioni spurie della logica dette glitch a loro volta fonte di picchi di potenza non utile al chip. Esistono sistemi per limitare il fenomeno, ricorrendo a circuiti di clock gating “glitch free” che pur permettendo il fenomeno dello skew ne limitano i danni arrecati minimizzando il glitch. Per far ciò, però, si aumenta ancora la complessità circuitale. In basso è riportato l’effetto del glitch per un adder a 16 bit
In ogni caso, il clock gating, per il fatto che non comporta lo “spegnimento” del circuito, non si presta, se utilizzato da solo, ad essere implementato in dispositivi a bassa potenza.
Un altro metodo che si basa su considerazioni di tipo statistico, tiene conto della tipologia delle interconnessioni delle porte logiche che ha una grande influenza sulla probabilità che un circuito possa commutare. Ad esempio, tra una connessione di porte AND a catena o pipeline ed una ad albero, come quelle della figura seguente
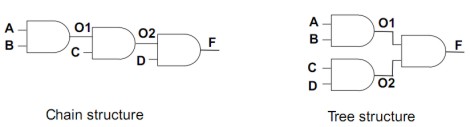
con input A, B, C, D di tipo random, la probabilità di commutazione da 0 a 1 è riportata in tabella (non vi tedio con i calcoli)
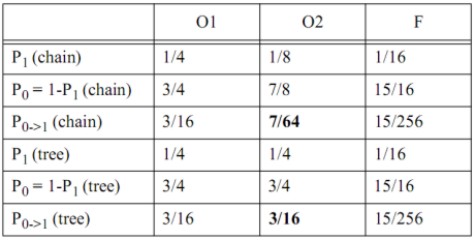
Come si può vedere, la probabilità che avvenga la commutazione O2 è più bassa per la struttura a pipeline che per quella ad albero; quindi la prima sembrerebbe migliore ai fini della riduzione della potenza dissipata a causa degli accoppiamenti capacitivi. Anche in questo caso c’è un ma….. Ovvero, la struttura a catena introduce uno skew maggiore rispetto a quella ad albero. Questo ritardo può essere originato da vari fattori all’interno di un circuito elettronico: differente lunghezza e/o diverso valore delle resistenze delle linee di trasmissione, tempo di transito attraverso le basi dei transistor dei segnali, interferenze, ecc. Ad esempio, nel circuito sottostante, clk1, clk2 e clk3 sono, con ogni probabilità, leggeremente sfasati tra di loro
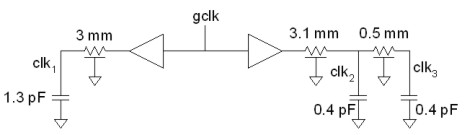
Ci sono situazioni in cui lo skew viene utilizzato per evitare che tanti transistor commutino in contemporanea o in tempi ravvicinati; in questi casi, si “spalma” volutamente il ritardo all’interno di un range (solitamente tra i 100 e i 300 ps) che permetta di rimettere in fase i segnali, quando occorre, senza particolari problemi, attraverso deskew circuit con annessi buffer; nella figura in basso è riportato un sommario schema a blocchi di uno di questi circuiti presenti nell’Itanium
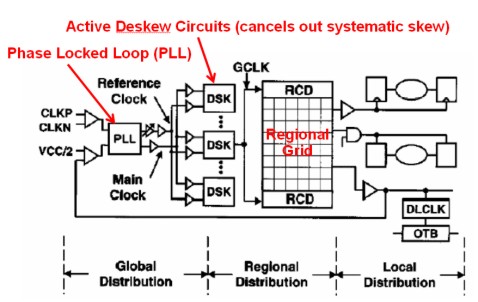
Un sistema invece per evitare l’insorgere del fenomeno dello skew è quello di dotare il chip di griglie a due o più livelli per la trasmissione del clock, anzichè di semplici linee (come la regional grid della figura qui sopra), oppure di strutture dette H-tree che hanno una forma del tipo di quella riportata in basso
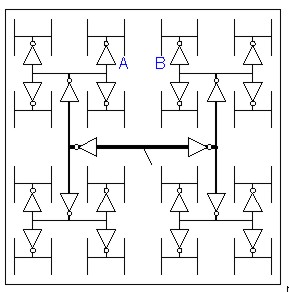
del tipo di quelle presenti su Itanium 2 che presentano anche 4 livelli di buffering per permettere un corretto riallineamento dei segnali di clock.
Alternativa a griglie e H-tree, la realizzazione di linee di trasmissione larghe, possibilmente, brevi, per ridurre i ritardi di tipo RC visti sopra (ossia imputabili a resistenze e accoppiamenti capacitivi) o di strutture ibride che facciano uso di H-tree e di griglie (una soluzione simile è adottata sulla serie IBM PowerPC 4 e 5).
Il principio di fondo è, comunque, quello di minimizzare lo skew in locale e cercare di utilizzarlo a proprio vantaggio a livello globale per evitare che tutti i gruppi o clock domain commutino nello stesso istante.
Se partiamo dalla generica equazione che fornisce la potenza per uno specifico datapath
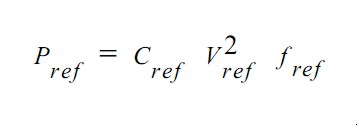
notiamo che la stessa è funzione della capacità, della frequenza e del quadrato della tensione di alimentazione del datapath preso come riferimento. Uno dei modi per ridurre la potenza in gioco è quello di sfruttare il parallelismo: a parità degli altri parametri, se utilizzo due circuiti identici a quello di riferimento, che lavorano in paralello, con frequenza dimezzata rispetto al circuito di riferimento, avrò, come risultato, un decremento della potenza richiesta (e, di contro, un aumento della superficie necessaria). Nella seguente tabella sono riportati i valori di tensione richiesti, a parità di output, per un circuito reference generico, per lo stesso circuito messo in forma di pipeline, per un parallelo di circuiti reference identici e per un mix tra parallelo e pipelined:
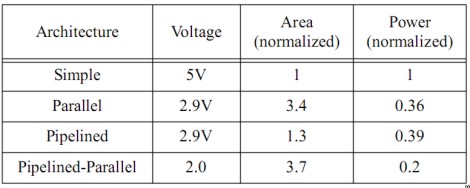
Risulta evidente che se si vuole ottenere, a parità di output, la massima riduzione possibile di Vdd, si deve adottare la soluzione che prevede più pipeline in parallelo; per avere, invece, un buon compremesso tra risparmio energetico ed area occupata, la migliore appare la soluzione di tipo pipelined.
Dalle considerazioni precedenti emerge che un’altra strada per ridurre la potenza dinamica è quella di ridurre le dimensioni dei gate sui non critical path, in modo da ridurre il carico capacitivo totale imputabile alle basi e, di conseguenza, il totale della capacità del circuito su cui si sta operando.
La riduzione di Vdd, prospettata qualche riga più in alto, non è esente da problemi: man mano che la stessa diventa comparabile con le tensioni di soglia dei transistor, si ha una crescente difficoltà a pilotare l’inverter con la conseguenza che il circuito diventa lento e poco affidabile. Quella della diminuzione della Vdd è, nonostante ciò, una necessità, in quanto non solo comporta una diminuzione della potenza di latch-up ma anche, ad esempio, della potenza di cortocircuito che si può arrivare, teoricamente, ad azzerare, qualora il valore di Vdd divenisse inferiore alla somma della tensione di soglia dell’nmos e del modulo della tensione di soglia del pmos.
Nel prossimo articolo partiremo da questo punto ed analizzeremo i modi iin cui è possibile diminuire Vdd senza rendere inaffidabile il circuito; faremo anche un cenno alle tecniche di power gating che rappresentano una novità, vedremo come alcuni progettisti abbiano implementato tecniche che prevedono variazioni dinamiche delle tensioni di alimentazione e delle frequenze, agendo su Vdd e PLL, e termineremo l’analisi delle componenti dell’equazione della potenza con i due termini restanti. Infine daremo un’occhiata ai sistemi adottati per ridurre i consumi delle cache interne e a cosa ancora si può fare in questi settori per migliorare ulteriormente il bilancio energetico dei chip e il rapporto tra potenza dissipata e prestazioni.







