Prima di iniziare a parlare dell’argomento di questa settimana, intendo ringraziare i miei colleghi che, la scorsa settimana, hanno riempito lo spazio della mia rubrica, lasciato scoperto a causa della mia indisponibilità.
Detto questo, passo subito ad introdurre lo spunto di riflessione odierno. In alcuni dei precedenti articoli, si è parlato di architetture parallele, di multithreading e dei differenti approcci di ATi e nVidia. Oggi vorrei introdurre, in via del tutto generale, l’idea che sta alla base del modo di progettare le attuali GPU. Ovvero, il motivo per cui, al di là delle differenti scelte a livello progettuale, le moderne GPU condividono alcuni elementi in comune, come, ad esempio, blocchi di tipo SIMD e una spiccata predisposizione al multithreading.
Iniziamo col dire che la particolare architettura di un chip grafico dipende da quello che è il suo compito principale (e fino a qulcha anno fa unico), ovvero elaborare immagini 3D partendo da un insieme di punti (dall’introduzione delle unità geometriche all’interno delle pipeline).
Di conseguenza, si ritrova spesso ad operare su vettori completi (soprattutto nelle operazioni geometriche) o su gruppi di pixel su cui deve eseguire le stesse operazioni. Inoltre, dovendo renderizzare un intero frame, ha bisogno di operare su un gran numero di dati, il più velocemente possibile. Infine, si trova a dover fare operazioni che possono richiedere tempi lunghi per l’accesso ai dati stessi. In conclusione, ha bisogno di tante unità che facciano, almeno a gruppi, le stesse cose e ha bisogno di mascherare le operazioni che comportano elevate latenze.
Ovviamente, le vie per ottenere questo scopo sono molteplici, ma andiamo per ordine.
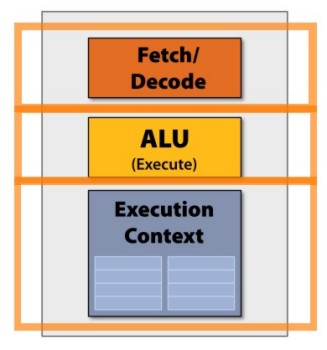
Cominciamo col ricordare, a grandi linee, lo schema a blocchi di un generico processore
In questo schema, manca, per caratterizzare il dispositivo come GPU, il blocco relativo alle TMU ma, in questa fase, la cosa non è funzionale a ciò di cui si vuole parlare.
Supponiamo di dover far girare un’istruzione di questo tipo sul chip dell’immagine precedente

L’operazione viene svolta su un singolo frammento, con precisione massima pari a fp32 . Se lo scopo è quello di renderizzare un intero frame, operazioni analoghe dovranno essere svolte su ciascun pixel del frame stesso e, in particolare, la stessa identica operazione dovrà essere fatta su tutti i pixel su cui si vuole ricreare il medesimo effetto.
Se utilizzo una sola unità del tipo visto in precedenza, l’operazione potrebbe richiedere molto tempo, anche se aumento la frequenza di funzionamento del chip. Un’alternativa è quella di mettere in parallelo più unità dello stesso tipo che fanno la stessa cosa nello stesso ciclo di clock.
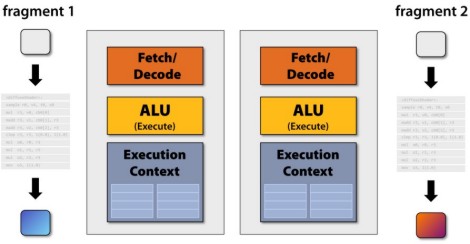
In questo modo, ho due unità identiche su cui far girare lo stesso shader nello stesso ciclo. Ma sono ancora poche per avere frame rate elevati! Quindi aumento ancora il numero di unità

In tal modo si ha l’equivalente di 16 core che operano in parallelo e si inizia ad avere una potenza di calcolo accettabile, ma si può fare ancora di più, aumentando il numero di core a 32, 64, 128, ecc.
A questo punto, ci sono alcune osservazioni da fare:
1) non tutti i core devono far girare lo stesso shader nello stesso numero di cicli
2) bisogna sincronizzare il lavoro di tutti i processori
3) dovendo organizzare il chip a blocchi di alu che eseguano la stessa istruzione nello stesso ciclo, ci sono, in questo schema, dei circuiti ridondanti
Il primo ed il terzo punto, in particolare, sono due aspetti dello stesso problema: l’elevato numero di “core” deriva dalla necessità di avere tante unità di calcolo e, in particolare, gruppi di unità che eseguano le stesse istruzioni nello stesso tempo. Quindi, un’alternativa all’architettura vista finora (MIMD) che può essere funzionale allo scopo di avere tante unità che eseguano a gruppi la stessa istruzione ma introduce delle ridondanze, è quella di avere più ALU controllate da un unico blocco di fetch/decode.
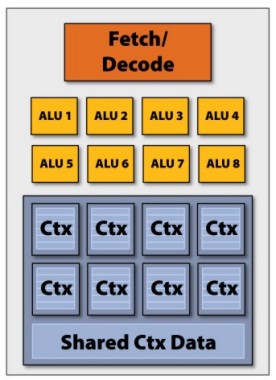
Nasce, così, l’idea di architettura SIMD o, per lo meno, parzialmente SIMD, relativamente ai blocchi di alu che devonio eseguire le stesse istruzioni nell’ambito degli stessi cicli.
In questo modo, per avere una potenza di calcolo teorica paragonabile al chip con 16 alu visto in precedenza, è sufficiente un chip con 2 core di 8 alu ciascuno. Quindi si potrebbe ipotizzare un’architettura a 2 livelli, con una gestione di tipo MIMD a livello “macroscopico”, ovvero a livello di gestione del lavoro dei vari core e di tipo SIMD a livello di gestione “microscopica” ovvero del lavoro all’interno del singolo core. In questo modo si attenua anche il problema della sincronizzazione del lavoro dellaalu all’interno del chip (resta da sincronizzare il lavoro dei core).
Uno dei principali vantaggi, oltre alla semplificazione della gestione del lavoro del chip, è quello di poter utilizzare i transistor risparmiati per inserire altre unità di calcolo, aumentando la potenza del chip. Lo svantaggio è quello che un’architettura full MIMD è sicuramente più flessibile ed efficiente.
A questo punto, si può modificare anche lo shader visto in precedenza per sfruttare, ad esempio, la capacità di operare su un vettore a 8 componenti di ogni singolo core

Con 16 core di tipo SIMD, siffatti, si ha un chip di questo tipo
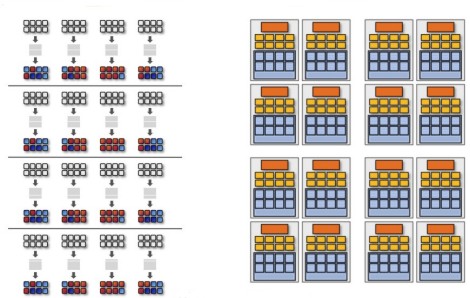
con 128 alu scalari ma solo 16 blocchi di fetch/decode.
Detta così, sembrerebbe che questa soluzione di aumentare il numero di alu per singolo “core” sia il classico uovo di Colombo; nella pratica si deve cercare il giusto compromesso tra numero di alu ed efficienza del chip. Aumentare indiscriminatamente il numero di alu, infatti, non costituisce una soluzione se non si tiene conto del fatto che non sempre, con istruzioni di tipo vettoriale o, comunuque, di tipo SIMD, non sempre si riesce ad ottenere che tutte le alu di un core siano contemporaneamente impegnate (con il chip dell’esempio, nel caso peggiore, si può avere un livello di occupazione pari ad 1/8 ed, in generale, pari a 1/n dove n è il numero di alu del singolo core).
Altro problema da risolvere, è quello delle operazioni ad elevate latenze; nello schema finora proposto sono stati omessi alcuni dei blocchi funzionali di una gpu, tra cui le TMU
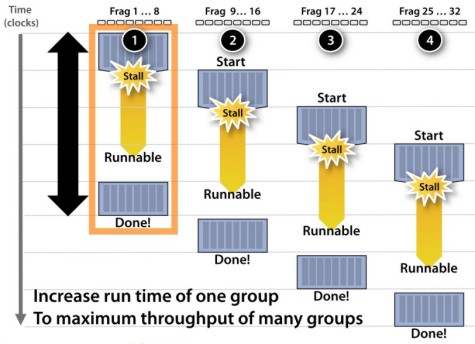
Un’operazione di texturing può richiedere centinaia di cicli di clock, per cui è necessario fare in modo di evitare che la pipeline vada in stallo, in attesa che l’operazione venga completata. Per fare ciò, si ricorre, oltre che all’utilizzo di uno o più livelli di texture cache, al multithreading. In ogni core di una GPU sono caricate diverse centinaia di thread composti, ciascuno, da una manciata di istruzioni elementari. Nel momento in cui una pipeline va in stallo, in attesa di un dato mancante, si procede a caricare il sucessivo thread, mettendo in attesa quelloin fase di elaborazione. In tal modo, si ha sempre la possibilità di tenere la pipeline impegnata nell’esecuzione di qualche istruzione.
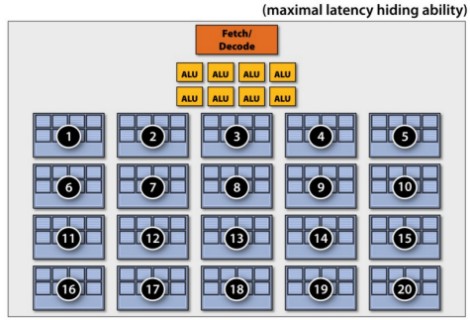
Per ottenere il massimo livello di multithreading possibile, è opportuno frammentare la memoria interna in tanti blocchi di piccole dimensioni,
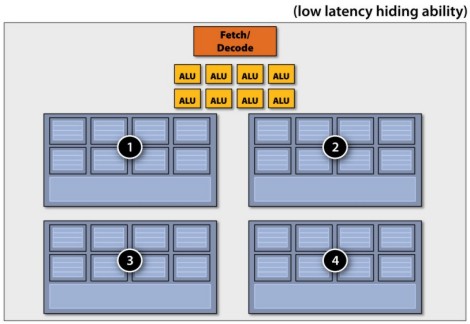
piuttosto che far ricorso a pochi blocchi di grandi dimensioni.
All’interno di una GPU trovano posto migliaia di registri costanti, temporanei, vertex register, texture register, output register, ecc. e, contrariamente a quanto accade per una cpu, relativamente pochi MB di cache.
Abbiamo visto che la scelta di implementare un’architettura di tipo, almeno parzialmente, SIMD, è dettata dall’esigenza di avere il più elevato numero possibile di unità di calcolo, tenendo anche conto del fatto che, per il particolare impiego dei chip grafici, spesso molte unità si trovano a svolgere le medesime operazioni su differenti dati. Inoltre, abbiamo visto che per risolvere il problema degli stalli si fa ricorso sia alla velocizzazione dell’esecuzione del singolo thread, come ovvio, ma anche all’utilizzo, in modo massiccio, del multithreading.
Abbiamo anche fatto cenno al fatto che un’architettura SIMD può presentare degli inconvenienti in termini di efficienza e di flessibilità, rispetto, ad esempio, ad una MIMD, limiti che diventano più evidenti in un impiego di tipo GP.
Concludiamo dicendo che le istruzioni per questo tipo di architetture possono essere di due tipi:
1) SIMD vettoriali di tipo esplicito, come quelle utilizzate per le cpu x86 o che dovrebbero essere usate per Larrabee
2) scalari, con l’hardware che si occupa di raggruppare le stesse istruzioni dello stesso tipo da inviare ad un gruppo di alu che operano in modalità SIMD (SIMD di tipo “implicito”), sul tipo di quelle utilizzate da ATi e nVidia per le loro GPU.
Chiudiamo con una considerazione che pone una serie di interrogativi.
Dall’analisi fatta, sembra risulti in parte corretta la definizione di GPU come di chip implicitamente multicore. In pratica, una GPU come GT200 o RV770 può considerarsi come dotata di più “core” fisici di tipo simmetrico (non i 240 o gli 800 sbandierati da nVidia e ATi, ovviamente). Perchè in parte e non del tutto? Quali sono i punti in comune e le differenze tra un “core” o presunto tale di una GPU ed un core, ad esempio, di una cpu multicore? E Larrabee di Intel, sarà una vera GPU multicore o, come dice Intel, “manycore” a tutti gli effetti?







