La scorsa settimana abbiamo introdotto alcuni concetti tra cui, in particolare, quello di pipeline. Si è anche visto come, nel cosro degli anni, la pipeline sia diventata elemento basilare nelle microarchitetture dei processori. Uno dei vantaggi del suo utilizzo è emerso dall’esempio in cui si è calcolato il numero di cicli necessari a portare a termine n istruzioni; si è visto come l’adozione dell’architettura di tipo pipelined introduca anche dei colli di bottiglia come, ad esempio, la necessità di sincronizzare il lavoro dei vari stadi della pipeline.
Si è visto come sia possibile aggirare il problema frammentando i singoli stadi, iniziando, in particolare, da quelli il cui data path richiede più cicli. Questa frammentazione degli stadi, ossia la sostituzione di un singolo stadio (ad esempio quello che si occupa di instruction fetch) con più stadi di dimensioni ridotte che compiano lo stesso lavoro, permette di aumentare le frequenze di funzionamento del chip e, nello stesso tempo, di aumentare il numero di thread in circolo nella pipeline. Questa operazione di frazionamento porta alle cosiddette architetture superpipelined.
Assumendo come ipotesi un funzionamento ideale in cui si hanno le seguenti condizioni:
ad ogni ciclo viene caricata una istruzione
le latenze delle operazioni semplici richiedono un solo ciclo
ILP (instructione level parallelism) richiesto epr il pieno utilizzo della macchian pari a 1
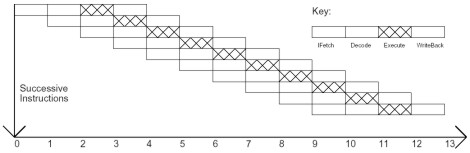
potremmo schematizzare il comportamento di un’architettura pipelined (con un solo stadio per ogni tipo di task) nel modo seguente
Come si vede, ipotizzando un comportamento ideale una ipotetica pipeline a 4 stadi (sto semplificando al massimo le cose) impiega 13 cicli per portare a compimento l’esecuzione di 10 istruzioni elementari.
Vediamo ora, cosa succede se ogni stadio viene frazionato, riducendo il critical path. Come visto la scorsa settimana, diminuisce il tempo necessario ad ogni stadio per portare a termine il suo task (di fatto, in una situazione non ideale, si riduce il numero di cicli necessario ad eseguire ogni step) . Il risultato è schematizzabile con la figura sottostante
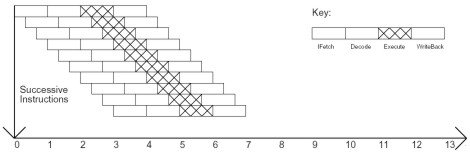
in cui si è ipotizzato che ogni stadio della pipeline sia suddiviso in 3 stadi più piccoli. Come si vede, se si mantiene sempre la stessa scala utilizzata per l’architettura pipelined, in quello che è l’equivalente di un ciclo si effettuano 3 instruction fetch e il numero di cicli “equivalenti” necessari si riduce a 7. Anche con un’architettura superpipelined, quindi, si ha un’istruzione per ciclo, ma il tempo di ogni ciclo si riduce a 1/m con m pari al numero di blocchi in cui è frammentato il singolo stadio (meglio ancora, gli stadi che introducono le latenze maggiori).
Un altro modo per ridurre il numero di cicli necesari ad esegiore un determinato numero di istruzioni è quello di mettere più pipeline in parallelo, inn modo che ciascuna sia indipendente dalle altre. Con questo modello si moltiplicano le istruzioni per ciclo, per il numero di pipeline (o per il numero di thread processor, ma questa cosa la vedremo meglio in seguito) , mentre resta invariata, rispetto al modello “base” la durata del task di ogni sigolo stadio della pipeline.
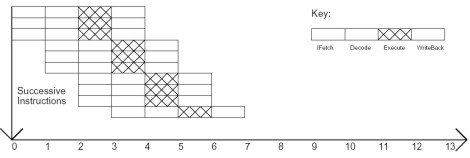
Questo tipo di architettura è nota come superscalare . Come si vede, prendendo sempre il numero 3 come moltiplicatore, l’utilizzo di 3 pipeline in parallelo, dal punto di vista del numero di cicli necessari a portare a compimento 10 istruzioni è equivalente al caso di architettura superpipelined con 3 segmenti per ogni stadio. Questo nel caso ideale.
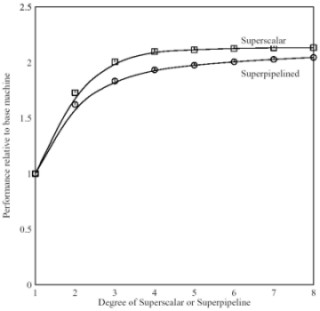
Il comportamento reale non si discosta molto da quello teorico e, all’aumentare dell numero di stadi e del numero di pipeline in parallelo (quindi di m negli esempi precedenti), le performance delle due architetture tendono ad allinearsi con un leggero vantaggio per la superscalare
La superscalare ha il vantaggio di poter avere pipeline più corte, su cui salti condizionali errati o propagazione di bolle hanno un impatto minore, mentre la superpipelined ha il vantaggio che quelle operazioni che richiedono basse latenze come le operazioni logiche o il trasferimento da un registro ad un altro di dati o istruzioni che su un’architettura superscalare prendono un intero ciclo, su una superpipelined occupano un intervallo pari a 1/n cicli con n pari al grado di frammentazione degli stadi della pipeline.
Un approccio misto, che eredita i pregi ed i difetti di entrambe le architetture è quello di tipo superscalar superpipelined, che prevede l’adozione di più pipeline in parallelo, ciascune delle quali con stadi “frammentati”. Per fare un confronto con le altre due architetture, considerando sempre il caso di m=3 (3 pipeline in parallelo e ogni stadio frammentato in 3 blocchi), sempre nel caso ideale, le situazione sarebbe quella di figura
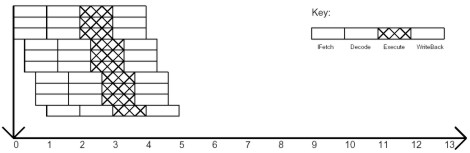
da cui si vade che le 10 iatruzioni sono portate a termine in soli 5 cicli.
Un altro approccio che permette di parallelizzare le operazioni è quello noto come vliw (very long instruction word). Secondo questo modello, un gruppo di micro istruzioni è raggruppato a formarne una complessa. La condizione è che tutte le istruzioni messe insieme appartengano allo stesso thread e non abbiano relazioni di dipendenze reciproche, in modo da poter essere elaborate tutte in parallelo. La scelta del numero massimo di istruzioni elementari che possono essere elaborate in parallelo, oltre che dalla condizione riportata sopra, dipende anche dal numero di alu che fanno parte di una unità di tipo vliw. Nel nostro esempio, prendiamo sempre 3 come numero base che, in questo caso sta a significare che ogni unità vliw è composta di 3 alu (per fare un paragone, quelle di R600 sono dotate di 5 alu di tipo vliw più una unità di branching). In questo caso, si ha la situazione illustrata nella figura sottostante
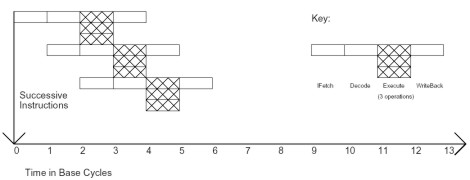
Come si può vedere, qualora sia possibile raggruppare le istruzioni a 3 a 3, un’architettura vliw impiegherebbe 7 cicli per eseguire le 10 istruzioni previste con un utilizzo poco efficiente delle alu per l’ultima istruzione che sarebbe eseguita da una sola delle 3 alu del processore, mentre alle altre 2 si darebbe in pasto una NOP (no operation).
L’utilizzo di architetture ad elevato parallelismo, oltre a permettere di raggiungere elevate potenze d’elaborazione, mette i progettisti e gli sviluppatori di fronte a diverse problematiche da risolvere, legate, per lo più, all’efficienza e all’ottimizzazione dei chip. Ad esempio, è evidente che in un’architettura di tipo vliw avere tante alu in parallelo comporta la necesità di trovare tante istruzioni elementari indipendenti facenti parte dello stesso thread da dare loro in “pasto”. Così come, l’hardware scheduler delle superscalari, se da un lato ha il vantaggio di essere trasparsnte al codice, dall’altro ha il difetto di avere dello stesso codice una visione solo “parziale”, creando problemi di data dependencies.
Lo scopo di questo articolo non è, però, quello di analizzare pregi e difetti delle varie scelte architetturali (sulla quali torneremo) ma, semplicemente, di presentare le diverse opzioni in modo tale da fornire un quadro più completo nel momento in cui si inizierà a parlare di architetture reali (con particolare riferimento alle GPU).
Con questo scopo in mente e, prendendo spunto dall’introduzione delle architetture vliw che, rispetto alle altre, presentano una forma di parallelismo apparentemente differente, vorrei soffermarmi molto brevemente sul rapporto tra dati e istruzioni. Questo tipo di considerazioni ci permette di raggruppare le architetture, seguendo la tassonomia di Flynn, in 4 grandi categorie: SISD, MISD, SIMD i MIMD.
SISD che è l’acronimo di single instruction single data, è l’architettura tipica di von Neumann, in cui viene eseguita un’istruzione per volta su un’unico dato, come indicato in figura
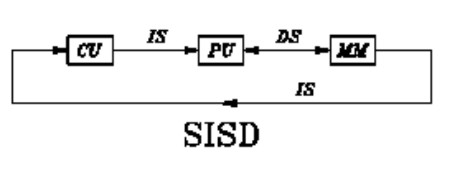
Un ‘architettura CISC di tipo tradizionale opera in modalità SISD ma il concetto si può estendere anche alle architetture a pipeline, se si considera la pipeline come il frazionamento in stadi di un’unità più complessa.
L’architettura MISD (multiple instruction single data) esiste solo a livello sperimentale, ma non è mai stata commercializzata. La sua schematizzazione è indicata nella figura seguente
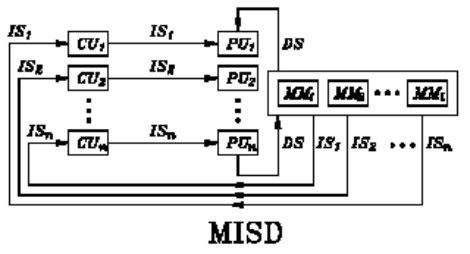
In un’architettura MISD si eseguono più istruzioni relative ad un singolo dato. Secondo alcuni, una pipeline si può ricondurre, in senso lato, ad un’architettura di tipo MISD, in quanto ogni singolo stadio esegue una istruzione semplice che fa parte di una istruzione complessa (quella iniziale) ma lavora su un singolo dato (quello relativo all’istruzione complessa). C’è, però, chi fa notare che lungo la pipeline il dato viene modificato e quindi non è più assimilabile al “single data” cui fa riferimento la tassonomia di Flynn realtivamente alle architetture MISD. Teoricamente, un’architettura di questo tipo dovrebbe servire a eseguire differenti istruzioni su un unico dato in input, per avere in uscita risultati differenti a seconda dell’istruzione eseguita, partendo dallo stesso valore in ingresso.
Più interessanti, almeno per l’universo delle GPU a cui questa rubrica è principalmente dedicata, le altre due architetture individuate da Flynn.
SIMD, acronimo di single instruction multiple data, è un’architettura in cui ad una istruzione in ingresso corrispondono più valori in uscita, ottenuti dal’esecuzione di quella singola istruzione da parte di più unità di calcolo che operano su dati differenti. Lo schema è quello sottostante
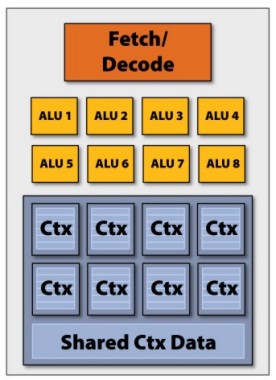
in cui si vede che c’è un unico stadio di instruction fecth e decode con un unico icache (instruction cache) che pilota un gruppo di alu dotata, ciascuna, di una sua memoria locale.
Caratteristiche principali di un’architettura SIMD sono, dsl lato hardware:
elevato numero di processori semplici
memoria distribuita
unità di controllo unica (unico flusso di controllo per tutto il gruppo di alu di tipo SIMD)
strutture di interconnessione a larga banda (mesh, ipercubo, ecc)
Mentre, per quanto riguarda il software:
facile programmabilità
ottimo sfruttamento delle potenzialità della macchina
scarsa flessibilità
Ad esempio, ognuno dei 10 cluster di 16 alu di RV770 opera in modalità SIMD ed ogni alu è composta da 4 unità fp32 ed una fp40 operanti in modalità vliw.
Ultima tra le quattro, la MIMD (multiple instruction multiple data) si può, in parte, schematizzare come più SISD in parallelo. Ogni alu esegue una differente istruzione su un diverso dato e, al contrario, ad esempio, della SIMD, non esiste vincolo di sincronismo tra le varie operazioni parallele. In realtà si hanno due sottocategorie di architetture MIMD, quella a memoria ocndivisa e quella a memoria distribuita.
La prima ha lo schema della seguente figura
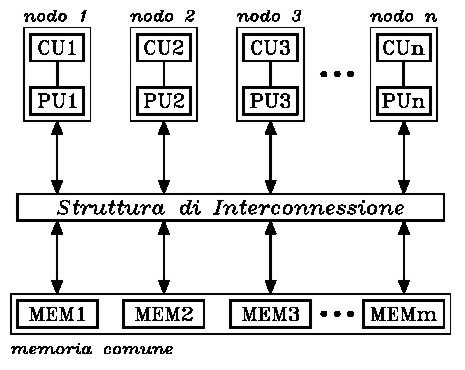
Questo tipo di architettura prevede l’utilizzo di pochi nodi molto potenti (ad esempio, anche cpu), con interconnessione a bus o di tipo point to point e con memoria condivisa. Questo modello si presenta facile a livello di programmazione e semplifica il bilanciamento automatico dei carichi di lavoro, ma presenta, come collo di bottiglia, all’aumentare dei nodi, il problema della saturazione della memoria (o, per meglio dire, della banda passante verso la memoria). Per aumentare il numero di nodi cercando di minimizzarne l’impatto sulla bandwidth si fa ricorso a cache locali.
Il primo livello dell’architettura di GT200 o di RV770 si può schematizzare con questo modello, ovvero, per entrambi i chip, 10 nodi gestiti in modalità MIMD shared da un thread dispatch processor; ogni cluster è getito in modalità SIMD per RV770 e SIMD a 3 vie per GT200, con le alu di RV770 che sono di tipo vliw.
L’altro modello, quello a memoria distribuita, si presta meglio ad esere implementato all’interno dei processori. Lo schema è quello in figura
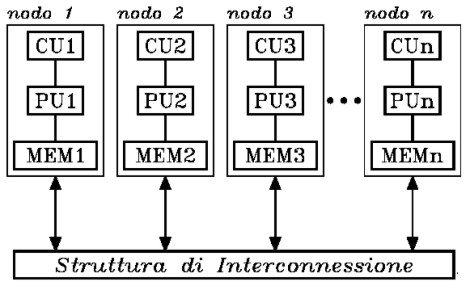
e presenta, come caratteristiche, la possibilità di implementare un gran numero di nodi, un’elevata bandwidth verso la memoria, interconnessioni tra i nodi ad elevata banda passante, notevole flessibilità ma, anche, naggior difficoltà di programmazione, allocazione non semplice dei carichi di lavoro e scarsa efficenza nelle operazioni che richiedono elevato parallelismo dei dati.
Dal punto di vista hardware, l’utilizzo di architettura di tipo MIMD, in luogo di quelle SIMD, fa aumentare la complessità dei circuiti di tipo logico e di controllo, duplicando anche una serie di elementi (unità di fetch e di decode, icache, ecc), come si vede dalla moltiplicazione dei blocchi che in figura sono indicati con CU.
Con la prossima settimana si concluderà questa sorta di introduzione che ha il solo scopo di familiarizzare con termini e concetti che torneranno utili nel momento in cui andremo ad analizzare alcuni aspetti delle architetture delle attuali GPU. Torneremo sulle architetture vliw e superscalari per parlare delle differenze a livello di gestione dell’ILP e inizieremo ad introdurre il discorso sulle differenti scelte progettuali adottate da ATi e nVidia e le diverse filosofie che le hanno ispirate.







