Potrà sembrare paradossale, ma i miglioramenti alla piattaforma a 16 bit che sono stati illustrati nel precedente articolo sono quelli che avrebbero portato più benefici alla piattaforma Amiga, in primis perché l’avrebbero resa nuovamente estremamente competitiva anche con le altre console della “generazione 16 bit”, e secondariamente (ma non meno importante) considerato che contengono già quasi tutto il necessario per farla evolvere successivamente, traendo anche vantaggio dalle maggiori frequenze operative (che comunque sono già state fatte proprie dall’ultima linea di innovazioni che sono state presentate).
E’ rimasta fuori la questione sulle dimensioni del “bus dati” (virgolettato, perché in questo contesto verrà sempre intesa come quantità di dati che si possono leggere o scrivere per ogni singolo accesso in memoria che è stato concesso dal chipset), il quale sarà oggetto di questo articolo, per l’appunto, quale cambiamento di maggiore importanza (ma ovviamente non sarà il solo a esser presentato).
1992: il tempo di Amiga 4000 e 1200
A due anni dal chipset a 16 bit / 14Mhz, la successiva piattaforma 32 bit avrebbe potuto avere:
- bus dati a 32 bit, con accesso anche in modalità fast page per leggere due dati a 32 bit (quindi 64 bit in tutto) in uno slot (come sempre, con questo termine s’intende una possibilità di accesso alla memoria);
- eliminazione del blocco dell’accesso alla memoria Chip ogni due slot per processori 68020+ (quindi possono accedere sfruttando fino al doppio degli slot rispetto al chipset a 16 bit);
- supporto a grafica packed/chunky a 15/16 bit (32 e 65 mila colori), 24 (16 milioni di colori) e 32 bit (come prima, ma con l’aggiunta del canale alpha), e tavolozza dei colori estesa a 16 milioni;
- schermi da 640×200/256 (NTSC/PAL) a 32 bit fino a 800×600 a 8 bit;
- modalità Dual Playfield coi due schermi da 320×200 a 32 bit + 16 bit, e fino a 640×400 a 8 + 8 bit;
- Blitter “agnostico” riguardo la dimensione del “bus” dati, quindi in grado di lavorare con dati di qualunque dimensione (fino a 64 bit, in questo caso. Quindi fino a quattro volte più veloce del precedente, che era già due volte più veloce di quello del chipset originale), e con pixel in formato packed/chunky a 15/16 bit, 24 e 32 bit;
- tracciamento delle linee col Blitter usando una texture in memoria Chip (una linea di byte) per i colori da usare per tutti i punti tracciati, quando si fa uso delle modalità packed/chunky;
- buffer delle istruzioni del Copper, usando il “bus” dati più grande, in modo da velocizzarne l’esecuzione;
- nuovo formato delle istruzioni
WAITeSKIPdel Copper, in modo da tener conto delle dimensioni dello schermo; - i 32 sprite (erano stati aumentati con l’ultima estensione a 16 bit/14MHz) possono arrivare adesso a 16 e 256 colori grazie al nuovo “bus” dati;
- nuovo formato dei registri degli sprite per poterli posizionare sugli schermi di dimensioni maggiori, e consentire altri cambiamenti (“flip” verticale, possibilità di scegliere qualunque tavolozza da utilizzare delle due da 256 colori a disposizione, soppressione delle word di controllo);
- i 32 canali audio (anch’essi estesi in precedenza, come per gli sprite) possono arrivare a 56kHz di frequenza e con campioni a 16 bit, sempre col nuovo “bus” dati;
- nuovo formato dei registri audio, per consentire di specificare lunghezze dei campioni superiori a 128kB, espandere il volume a 256 livelli per le uscite sinistra e destra, e dare la possibilità di definire più funzionalità;
- possibilità di campionare da sorgenti audio esterne;
- supporto ai dischetti da 2 e 4MB;
- seriale con buffer FIFO e canali DMA dedicati, in modo da ridurre al minimo le perdite di caratteri/byte e di svincolare quasi completamente la CPU;
- nuovi registri a 32 bit per poter indirizzare direttamente e a piena velocità le due tavolozze da 256 colori da 16 milioni, i 32 sprite (e anche di più, con future estensioni) e i 32 canali audio (e anche di più in futuro);
- fino a 8MB di memoria Chip indirizzabile dal chipset.
All’apparenza sembra tanta roba, ma in realtà buona parte delle innovazioni derivano direttamente dalla possibilità di accedere fino a 4 volte i dati rispetto alla precedente generazione (quella a 16 bit/14MHz; la quale aveva già raddoppiato la banda di memoria a disposizione rispetto al chipset originale. Quindi si arriva a 8 volte la banda, in totale): risoluzioni più elevate (anche in Dual Playfield, che può utilizzare anche le modalità packed/chunky), Blitter fino a 64 bit (quindi anche più veloce, come già anticipato), istruzioni più veloci del Copper, e supporto ai dischetti da 2 e 4MB ricadono tutti nel novero delle modifiche immediatamente accessibili grazie allo sfruttamento del nuovo “bus” dati e ai buffer per i componenti che lo usano pienamente.
Sprite più colorati… e altro
Una considerazione analoga può essere fatta anche per gli sprite. I quali, potendo leggere 32 o 64 bit anziché 16, possono espandere tranquillamente la loro gamma cromatica dai 4 colori che utilizzano normalmente. La logica del nuovo funzionamento in questo caso è veramente banale e pienamente naturale col funzionamento del chipset e degli stessi oggetti grafici, ma richiede una piccola spiegazione per comprenderlo.
I 4 colori derivano dal fatto che, col bus a 16 bit, vengono letti due dati a 16 bit, che rappresentano rispettivamente i dati del primo e del secondo bitplane che, messi assieme, costituiscono la riga dei 16 pixel dello sprite. Ma se si leggono 32 bit alla volta, invece, abbiamo il doppio dei dati, i quali possono essere pensati come 4 dati/bitplane a 16 bit (i primi due provenienti dal primo valore a 32 bit, e gli altri due dal secondo), e con 4 bitplane possiamo visualizzare 16 colori. Con la stessa logica, leggendo due dati a 64 bit abbiamo a disposizione 8 dati/bitplane a 16 bit e, quindi, 256 colori visualizzabili.
Si potrebbero anche usare i dati a 32 e 64 bit per allargare gli sprite, facendoli diventare di 32 e 64 pixel orizzontalmente, ma il loro utilizzo sarebbe di gran lunga più limitato (e aumenterebbe lo spreco di memoria e di banda), considerato che rimarrebbero a 4 colori.
Non mi stancherò mai di ripetere, infatti, che è preferibile, in generale, avere sprite di dimensione più piccola e molto più colorati, perché consentono sia di riutilizzare meglio la grafica (oggetti grafici più grandi si possono ottenere dalla combinazione di tanti sprite più piccoli, alcuni che possono attingere ai medesimi asset) e, soprattutto, avere più colori è decisamente più appagante visivamente rispetto alla povertà dei soli 4 colori (che in realtà sono tre, perché uno viene usato per la trasparenza).
Le altre modifiche agli sprite (flip, tavolozza dei colori, ecc.) verranno trattate nell’ultima sezione, la quale riguarda la nuova mappa di memoria, perché verrà mostrato il formato dei nuovi registri (che ovviamente includono quelli degli sprite).
L’evoluzione dell’audio…
Stesso discorso per l’audio: i maggiori benefici derivano dalla banda quadruplicata, rispetto al precedente chipset (16 bit/14Mhz), che consente sia di raddoppiare la frequenza operativa (raggiungendo i 56kHz massimi) sia di avere gli agognati campioni a 16 bit, rimettendo finalmente in carreggiata la piattaforma da questo punto di vista e, anzi, andando ben oltre quanto offerto dalla concorrenza.
Miscelare tutti questi canali a 16 bit potrebbe sembrare eccessivo in termini di risorse, ma la via tracciata col suddetto chipset, come visto nel precedente articolo, consente di gestire il tutto senza richiedere tante risorse, a parte utilizzare adesso due DAC con più elevata precisione in modo da poter ottenere una miglior qualità di riproduzione, ed estendere la precisione dei due sommatori che si occupano della miscelazione vera e propria (prima di inviare il risultato ai due DAC).
Le altre modifiche (incluso il campionamento da una sorgente esterna) dipendono principalmente dai nuovi registri, e verranno trattati nell’apposita sezione. In realtà ci sarebbe spazio anche negli attuali registri (alcune word sono inutilizzate), ma le modifiche richieste sarebbero state un’altra pezza sui vecchi registri, mentre il nuovo (nemmeno tanto: è una naturale evoluzione) formato consente di mappare tutte le modifiche in maniera più semplice, funzionale, e immediata.
… e del video
Passare da campioni audio a 8 bit a quelli a 16 bit è una rivoluzione, ma certamente non quanto il passaggio da una tavolozza di 4096 a una di 16 milioni di colori: l’impatto è drammaticamente e piacevolmente più percepibile. Nel ’92 era certamente l’ora di far fare il gran salto anche all’Amiga, grazie sia al maggior numero di transistor a disposizione per “allargare” le due tavolozze da 256 colori, sia al supporto alle modalità packed a 24 e 32 bit, a cui si aggiungono anche le modalità packed/chunky a 16 bit (da 32 e 65 mila colori) che ormai andavano rapidamente diffondendosi (come buon compromesso fra numero di colori e spazio occupato in memoria).
Il più grosso limite era prima rappresentato dalla scarsa banda a disposizione, ma l’aumento di frequenza della precedente generazione e, soprattutto, il nuovo “bus” dati consentono di utilizzare queste modalità, anche se fino a certe risoluzioni, ovviamente (non si può pretendere di averle per quelle più alte).
L’implementazione non è complicata, perché si tratta di estendere quanto già fatto per aggiungere la modalità packed/chunky a 8 bit, la quale ha introdotto l’uso di singoli byte per “indirizzare” i colori dei pixel. Le nuove modalità a 16, 24 e 32 bit sono una semplice continuazione dello stesso concetto, ma usando due, tre e quattro byte rispettivamente, con l’ulteriore nonché leggera modifica rappresentata dal fatto che il chip video non è costretto ad accedere alla tavolozza dei colori per ricavare finalmente il colore da inviare al monitor/TV, ma il colore è già direttamente disponibile (anche se per le modalità a 16 bit serve “aggiustarlo” un pochino, per generare i relativi colori ma a 24 bit).
Lo stesso, identico, discorso vale anche per il supporto a queste modalità da parte del Blitter. Coprocessore che, avendo operato sempre con word (16 bit, due byte) alla volta, non ha mai avuto problemi in questo senso, a parte sapere cosa farci con quei bit (e per questo è importante dover specificare quale tipo di formato packed/chunky devono essere usati dai canali dati su cui opera). Il discorso cambia leggermente per supportare quelle a 24 e 32 bit, ma rimane agevole grazie anche all’allargamento del “bus” dati a 32 e più bit.
Tracciare linee: l’anticamera di rotazioni, zoom, e… 3D!
Uno dei più grossi limiti della funzionalità di tracciamento delle linee in hardware del Blitter è stato quello di poterle disegnare in maniera esclusivamente duo/monocromatica: usando soltanto due colori (uno per i pixel “pieni” = con valore 1 nei bitplane, e uno per quelli “vuoti” = con valore 0), oppure uno (per i pixel “pieni”: quelli vuoti sarebbero stati “trasparenti”, lasciando intatto, quindi, lo sfondo).
I suddetti formati packed/chunky consentono, invece, di superare in maniera semplice e agevole questa limitazione, poiché è sufficiente far puntare il canale sorgente B alla zona di memoria Chip dove si trova la sequenza di byte coi colori da caricare e utilizzare mano a mano che i singoli pixel della linea vengono tracciati. Normalmente questo canale non carica nulla dalla memoria, ma il suo valore è preimpostato per specificare direttamente il pattern della grafica da utilizzare ciclicamente (si ripete ogni 16 pixel) per impostare il “colore” (in realtà si tratta di ottenere pixel “pieni” o “vuoti”/”trasparenti”, come già spiegato) di ogni pixel.
Questa banale modifica consente, dunque, di ottenere tale funzionalità che all’apparenza potrà sembrare poco importante, ma che in realtà può essere sfruttata per poter finalmente implementare una primitiva grafica molto onerosa a livello prestazionale e di cui s’è dovuto sempre far carico il processore: la rotazione. Ovviamente parliamo di rotazione di un’intera immagine. Ad esempio partendo da questa:

per ottenere quest’altra:

L’idea di base non è affatto complicata. Infatti basta partire dalla prima riga dell’immagine non ruotata che diventerà la sorgente del canale B, e tracciare una linea che parte dalle coordinate del primo punto (evidenziato in verde in entrambe le immagini) che sarà ruotato (qui serve la CPU per calcolarne la posizione, ovviamente) e per la lunghezza della riga dell’immagine. Si ripete, poi, lo stesso processo per la seconda riga, calcolando il primo punto ruotato, così via per tutte le righe, e il gioco è fatto!
Con un procedimento simile si può implementare anche lo zoom orizzontale, ma in questo caso serve un ulteriore registro dove specificare il fattore di zoom (un valore a virgola fissa 8 + 8 = 16 bit: 8 bit per la parte intera e 8 per quella decimale) da utilizzare, che equivale a sapere di quanto incrementare / far andare avanti il puntatore del canale B per caricare il prossimo colore. In questo caso si potrà riciclare il registro dei dati del canale (che con la grafica planare veniva usato per caricare il pattern con cui disegnare le linee).
Internamente il Blitter utilizzerà un registro a 8 bit, inizialmente impostato a zero, dove memorizzerà i valori frazionari, in modo da poter accumularne man mano i valori. Per essere chiari, è come se il puntatore del canale B fosse stato “allungato” con ulteriori 8 bit che conterranno la parte frazionaria della somma fra il puntatore attuale e il fattore di zoom, che viene effettuata ogni volta che bisogna passare al prossimo pixel da tracciare.
Questo meccanismo, come già detto, consente di implementare il solo zoom orizzontale per una singola riga. Basterà processare una riga alla volta dell’immagina da zoomare, per poterlo applicare a tutta l’immagine. Per zoomare anche verticalmente sarà sufficiente che il processore “piloti” il tracciamento delle linee zoomate orizzontalmente, ma usando un fattore di zoom verticale allo scopo. Infine, e applicando entrambi i concetti, ovviamente sarà possibile implementare contemporaneamente rotazione e zoom dell’immagine.
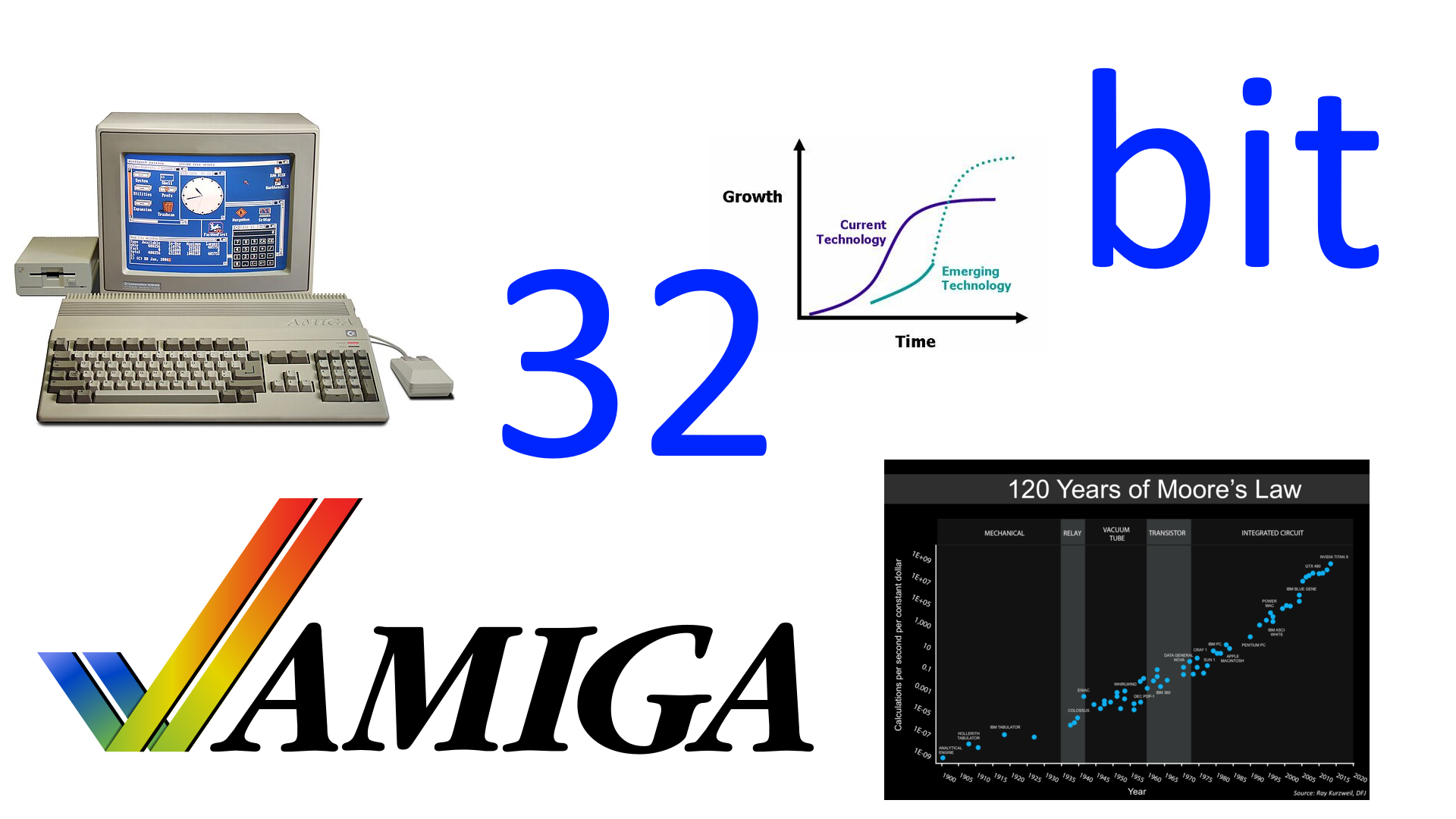
Si tratta di primitive molto importanti, usate anche in ambito ludico (ma non solo: pensate alla trasposizione di una matrice, ad esempio), di cui si sentiva la mancanza in ambito Amiga. Anche se richiedono il supporto del processore per coordinare tutte le operazioni, riga per riga, rappresentano comunque un notevole passo avanti rispetto alla completa assenza di accelerazione hardware, e che avrebbero aiutato moltissimo in giochi come questo:
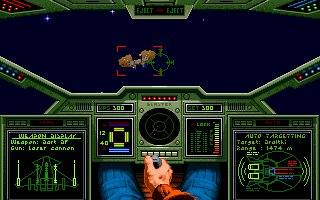
Da sottolineare anche il fatto che sarebbe possibile utilizzare lo stesso meccanismo per aiutare nell’implementazione dei primi giochi 3D, chiamati anche 2.5D perché renderizzano la scena con un 3D parziale, utilizzando alcuni trucchetti per disegnare mura e pavimenti, come ad esempio in questo caso:

Tutto avrebbe fatto brodo, insomma, per cercare di aiutare la piattaforma che generalmente era dotata di processori economici per risparmiare sui costi di produzione, e quindi non poteva contare su grandi potenze di calcolo.
Nuovo formato per le istruzioni WAIT e SKIP del Copper
Passando all’altro coprocessore, alcune modifiche abbastanza importanti sono necessarie al Copper a causa dell’aumento della risoluzione degli schermi, che vanno ben oltre quelle messe a disposizione nella metà degli anni ’80.
Riporto il formato delle sue istruzioni (che sono costituite da due word = 16 bit), visto che sono soltanto tre e richiedono poco spazio per la loro descrizione:
| Bit 0 | Always set to 0 |
| Bits 11 – 1 | Address of destination register |
| Bits 15 – 12 | Number of 16-bit registers to be set |
| Bits 15 – 0 | 16-bit of data to be transferred (moved) to the destination register |
| Bit 0 | Always set to 1 |
| Bits 7 – 1 | Horizontal beam position (divided by 2) |
| Bits 15 – 8 | Vertical beam position |
| Bit 0 | 0 = WAIT, 1 = SKIP |
| Bits 7 – 1 | Horizontal position compare enable bits |
| Bits 14 – 8 | Vertical position compare enable bits |
| Bit 15 | The blitter-finished-disable bit |
Giusto per chiarezza e correttezza, la MOVE incorpora già le modifiche suggerite nei precedenti articoli riguardo la possibilità di poter impostare più di un registro (nella versione originale per Amiga consente di farlo soltanto per un registro).
Le istruzioni WAIT e SKIP si occupano rispettivamente di aspettare una certa posizione del pennello elettronico, oppure di saltare la prossima istruzione se è già stata superata. Possono anche tenere conto dello stato del Blitter e aspettare che abbia finito il suo lavoro, oppure saltare la prossima istruzione se avesse già finito.
Ci sono da evidenziare un altro paio di cose. Innanzitutto la risoluzione orizzontale risulta dimezzata, perché manca all’appello il bit meno significativo. Secondo, ed è l’oggetto che interesserà la modifica, ci sono pochi bit a disposizione (7 per il valore orizzontale e 8 per quello verticale) per poter specificare una qualunque coordinata. Per il valore orizzontale questo non è un grosso problema (almeno coi segnali video dell’Amiga), perché in realtà si riferisce allo slot di memoria e non alla coordinata vera e propria, per cui la granularità effettiva orizzontalmente va da 4 (bassa risoluzione) a 2 (alta risoluzione) pixel.
Quello verticale, invece, coincide con la coordinata vera e propria, e con segnali video come il PAL (che ha 256 linee visibili, ma altre 56 non visibili) ciò richiede l’impiego di due istruzioni per coordinate verticali effettive che superano il valore 256. Infatti bisogna prima aggiungere un’istruzione per aspettare la fine della riga 255, e poi aggiungerne un’altra per aspettare la riga vera e propria.
E’ chiaro che con risoluzioni più grandi orizzontalmente e/o verticalmente questo schema troppo limitato diventi un problema e sarebbe meglio trovare una soluzione definitiva, oltre che semplice. L’idea è quella di riutilizzare lo spazio degli altri bit presenti nella seconda word di tali istruzioni, che col chipset originale hanno il compito di “mascherare” i bit orizzontali e verticali, facendo sì che le istruzioni possano aspettare pattern regolari nelle coordinate (ad esempio cambio di colore che si ripete ogni 16 pixel orizzontalmente, oppure ogni 32 pixel verticalmente). Funzionalità di utilizzo molto limitato, di cui a mio avviso si può tranquillamente fare a meno (al limite si emula con più istruzioni), usando questi bit per il nuovo formato di queste due istruzioni:
| Bit 0 | Always set to 1 |
| Bits 14 – 1 | Horizontal (real) beam position (divided by 2) |
| Bit 15 | 0 = WAIT, 1 = SKIP |
| Bits 14 – 0 | Vertical beam position |
| Bit 15 | The blitter-finished-disable bit |
Con 15 bit a disposizione (14 per quella orizzontale, perché ha una granularità di 2 pixel. Compromesso più che accettabile, a mio avviso, considerato che il chipset originale è messo anche peggio, come già spiegato) si possono avere coordinate fino a 32767: abbastanza per coprire senza problemi gli schermi con risoluzioni molto elevate a cui siamo abituati ormai da un po’ di anni.
Seriale con FIFO e DMA
Infine, una funzionalità completamente nuova: la seriale avanzata. Con l’arrivo dei modem a più alta velocità si è visto che con sistemi non troppo potenti venivano persi dei caratteri, in quanto il processore non arrivava in tempo a leggerli.
La soluzione che nel mondo PC è stata adottata è quella di mettere a disposizione un buffer interno (una coda FIFO), in cui memorizzare un certo numero dei caratteri che mano a mano arrivavano, o che dovevano essere inviati. In questo modo la CPU aveva abbastanza tempo per scaricare tutti quelli che erano disponibili, ed effettivamente il problema era risolto.
Con l’Amiga si sarebbe potuto fare la stessa cosa, ovviamente (e difatti era previsto per il chipset AAA, di cui abbiamo già parlato in un precedente articolo della serie), ma personalmente ritengo che sarebbe stato molto meglio dotare la seriale anche di un apposito canale DMA da utilizzare per scrivere in memoria i byte che mano mano arrivano, e un altro canale DMA per quelli da inviare (quando la seriale sarebbe stata libera), sposando la filosofia dell’Amiga e liberando il più possibile il processore da questo compito.
Nuova mappa di memoria e nuovi registri
Con l’introduzione di una piattaforma a 32 bit sarebbe stato meglio riorganizzare la mappa di memoria dei registri del chipset, pesantemente penalizzata dai soli 256 registri a 16 bit che mal si adattano a tutti i cambiamenti effettuati, specialmente per l’espansione delle tavolozze dei colori, degli sprite e dell’audio.
I registri dell’Amiga partono dal famosissimo (per gli sviluppatori) indirizzo $DFF000, arrivano a $DFF1FF, ma si possono estendere al massimo fino all’indirizzo $DFFFFF (quindi per un totale di 4kB), poiché l’indirizzo $E00000 è riservato per le schede collegate al sistema. Quindi è naturale pensare di sfruttare questi 4kB per l’implementazione a 32 bit:
| Address | Registers size | Number of registers | Area Size | Area Type |
| $DFF000 | 16-bit | 256 | 512 byte | Miscellaneus (original chipset) |
| $DFF200 | 32-bit | 128 | 512 byte | Miscellaneus (new chipset) |
| $DFF400 | 32-bit | 128 | 512 byte | Sprites |
| $DFF600 | 32-bit | 128 | 512 byte | Audio Channels |
| $DFF800 | 32-bit | 256 | 1024 byte | First 256 Colours Palette |
| $DFFC00 | 32-bit | 256 | 1024 byte | Second 256 Colours Palette |
Ovviamente si può accedere ai registri a 32 bit soltanto con operazioni di 32 bit alla volta, e a indirizzi allineati a 32 bit, altrimenti i risultati sono impredicibili. Lo stesso si può fare coi vecchi registri a 16 bit e alle stesse condizioni (in questo modo si raddoppiano le prestazioni rispetto alle implementazioni dell’Amiga), tranne per alcuni registri speciali a 16 bit che vengono “espansi” in equivalenti registri a 32 bit presenti nella seconda area.
Per spiegare quest’ultimo punto bisogna fare un esempio pratico, prendendo i registri del Blitter. Quasi tutti i suoi registri si possono scrivere a 32 bit in un colpo solo, quindi impostando i due equivalenti registri a 16 bit, ma per alcuni non è possibile farlo, perché hanno bisogno essere scritti a 16 bit in quanto la loro scrittura comporta l’esecuzione di operazioni interne. Ciò è ovvio per il registro BLTSIZE, perché fa partire immediatamente l’esecuzione del compito per questo coprocessore. Meno ovvio per i registri di modulo associati ai quattro canali dati, perché col nuovo chipset a 32 bit il loro valore a 16 bit verrebbe esteso con segno a 32 bit e memorizzato nell’equivalente registro presente nella nuova area a 32 bit. Ad esempio, scrivendo il valore -2 ($FFFE in esadecimale) in BLTCMOD, verrebbe scritto il valore $FFFFFFFE in BLTCMOD32 (che è il suo equivalente a 32 bit. Il quale potrebbe trovarsi al nuovo indirizzo $DFF240, ad esempio).
Considerazioni analoghe valgono anche per altri registri speciali, come quelli dei colori. Ad esempio scrivendo $0FA5 in COLOR00 (all’indirizzo $DFF180), che rappresenta uno dei 4096 colori dell’Amiga, verrebbe scritto il valore a 32 bit $00FFAA55 (quindi usando uno dei 16 milioni di colori) sia su T1COLOR000 (all’indirizzo $DFF800: primo dei 256 colori della prima tavolozza) sia su T2COLOR000 (a $DFFC00: primo della seconda tavolozza). La doppia scrittura è necessaria per preservare l’assoluta compatibilità col software scritto per il chipset originale, in quanto in questo caso c’era una sola tavolozza a disposizione, mentre nelle nuove versioni ce ne sono due, e la seconda è associata al secondo schermo della modalità Dual Playfield.
I nuovi registri degli sprite…
Quest’ultimo esempio fa capire anche in che modo sono stati espansi i registri degli sprite, ad esempio, che nella loro nuova area a 32 bit hanno la seguente struttura (per il primo di loro, ma è identica per tutti gli sprite che seguono, ovviamente):
| Name | Address | Description |
| SPR0PTR | $DFF400 | Sprite 0 pointer |
| SPR0START | $DFF404 | Sprite 0 start position |
| SPR0END | $DFF408 | Sprite 0 end position + control |
| SPR0ZOOM | $DFF40C | Sprite 0 zoom factor (for future implementation) |
SPR0PTR è l’equivalente dei due registri SPR0PTH e SPR0PTL (ovviamente una scrittura su questi registri comporta la contemporanea scrittura del valore a 16 bit anche nella relativa parte di SPR0PTR), mentre SPR0START rappresenta la versione espansa di SPR0POS, e ha la seguente struttura:
| Bits 14 – 0 | Horizontal position |
| Bit 15 | Flip X |
| Bits 30 – 16 | Vertical position |
| Bit 31 | Flip Y |
Come si può vedere, le coordinate orizzontali e verticali sono ben separate (ognuno nei propri 16 bit), e loro bit più significativo consente di stabilire se eseguire eventualmente l’operazione di “specchiamento” (flip/mirror).
Allo stesso modo, SPR0END rappresenta la versione espansa di SPR0CTL, ma adesso è strutturato in questo modo:
| Bit 0 | Attach control bit (odd sprites) |
| Bit 1 | Which of the two 256 colours palettes should be used. |
| Bits 7 – 2 | Palette portion to be used for 4 colours sprites |
| Bits 7 – 4 | Palette portion to be used for 16 colours sprites. Bits 3-2 should be zero. |
| Bits | Palette portion to be used for 256 colours sprites. Not used: bits 7-2 should be zero. |
| Bits 9 – 8 | Granularity for horizontal position (e.g.: sprites can be moved 1/4th of pixel in lores and 1/2nd of pixel in hires) |
| Bit 10 | Pure data: no control words are fetched for the sprites to set their start/end positions and additional data. So, only graphics data is fetched. |
| Bits 15 – 11 | RESERVED. Should be zero! |
| Bits 30 – 16 | Vertical position |
| Bit 31 | RESERVED. Should be zero! |
Il significato dei vari campi dovrebbe essere abbastanza chiaro, anche perché molti sono equivalenti alle informazioni già memorizzate nelle vecchie versioni. Il bit 10 richiede una particolare menzione, perché cambia il modo in cui i dati letti vengono interpretati. Normalmente, infatti, col primo accesso alla memoria vengono caricati i valori da impostare nei registri di posizione e controllo; soltanto a partire dal successivo accesso vengono effettivamente caricati quelli della grafica da visualizzare per lo sprite per quella particolare riga. Il bit 10 consente di sopprimere il caricamento di posizione e controllo, e quindi caricare soltanto la grafica; ma in questo modo il processore o il Copper si devono far carico di impostare correttamente lo sprite.
Per il resto, è chiaro che quando verrà effettuata una scrittura nei vecchi registri di posizione e controllo, i loro valori a 16 bit verranno presi e quei bit verranno “spacchettati” e conservati nei rispettivi campi dei nuovi registri. Questo, al solito, per mantenere piena compatibilità col vecchio software.
Infine, e visto che c’era ancora un po’ di spazio a disposizione, un nuovo registro, SPRZOOM, avrebbe consentito di impostare i fattori di scala per gli sprite, in modo da poterne effettuare lo zoom orizzontalmente e verticalmente.
| Bits 15 – 0 | Horizontal zoom, as 8 + 8 bits (integer + fractional part) |
| Bits 31 – 16 | Vertical zoom, as 8 + 8 bits (integer + fractional part) |
Da implementare compatibilmente col budget di transistor a disposizione (ma su questo ne parlo meglio nelle conclusioni).
… e quelli dell’audio
Anche i registri dei canali audio sono stati espansi con una logica simile. In particolare, la struttura del primo canale sarebbe la seguente:
| Name | Address | Description |
| AUD0LC | $DFF600 | Audio channel 0 location (pointer to the sample’s data) |
| AUD0SAMPLES | $DFF604 | Audio channel 0 number of samples to reproduce |
| AUD0PERCTL | $DFF608 | Audio channel 0 period + control |
| AUD0VOLS | $DFF60C | Audio channel 0 volumes |
Come per gli sprite, anche AUD0LC è l’equivalente di AUD0LCH e AUD0LCL, per cui valgono le stesse considerazioni già fatte.
AUD0SAMPLES, invece, non è esattamente lo stesso di AUD0LEN, ma contiene il numero di campioni da riprodurre: penserà poi l’hardware a leggere i dati dei campioni, in base alla loro dimensione e alla dimensione del “bus” dati. Per una questione di assoluta compatibilità col software già scritto, le scritture al vecchio registro AUD0LEN verranno convertite in scritture del valore a 16 bit moltiplicato per due (perché nel vecchio chipset vengono sempre letti e riprodotti due campioni a 8 bit alla volta) ed esteso con zero.
Il registro AUD0PER, invece, risulta espanso nell’equivalente AUD0PERCTL, che contiene sia il periodo (che determina la frequenza) di riproduzione dell’audio, sia alcune informazioni di controllo, come da seguente tabella:
| Bits 1 – 0 | Samples size: 0 -> 8-bit, 1 -> 16-bit, 2 & 3 -> RESERVED |
| Bit 2 | One shot: only reproduce the samples one time and then stops |
| Bit 3 | Sample from external source |
| Bits 15 – 4 | RESERVED |
| Bits 31 – 16 | Period (number of color clocks) |
Il significato dovrebbe essere eloquente e non richiede ulteriori spiegazioni, a parte il fatto che una scrittura del vecchio registro AUD0PER comporta la scrittura di un valore a 32 bit nel nuovo registro, con tutti i bit di controllo azzerati (sempre per una pura questione di completa compatibilità col software esistente).
Similmente, il registro per il volume, AUD0VOL, risulta espanso in AUD0VOLS, che ha la seguente struttura:
| Bits 7 – 0 | Volume: left (front left output for quadraphonic sound) |
| Bits 15 – 8 | Volume: right (front right output for quadraphonic sound) |
| Bits 23 – 16 | Volume: back left output for quadraphonic sound |
| Bits 31 – 24 | Volume: back right output for quadraphonic sound |
In questo caso il volume è a 8 bit (mentre nell’Amiga è a 6 bit più un bit per indicare il volume massimo: quindi 65 possibilità in totale), e le scritture a 16 bit nei vecchi registri del volume si comportano in maniera diversa, a seconda del canale coinvolto.
Innanzitutto il valore a 6 bit + 1 viene internamente convertito in un valore che va da 0 a 255. Secondariamente, se i canali coinvolti sono lo 0 e 3, il valore risultato verrà scritto nei bit del volume sinistro, mentre quelli del volume destro risulteranno azzerati. Se, invece, si tratta dei canali 1 e 2, allora succede l’esatto contrario: il valore verrà scritto nel volume destro, e il volume sinistro verrà azzerato.
Questo perché nell’Amiga i canali audio 0 e 3 sono mappati sull’uscita sinistra, mentre l’1 e 2 su quella destra. Il suddetto comportamento consente di mantenere piena compatibilità con tutto il software scritto.
Infine, il sistema è già predisposto per futuri sistemi quadrifonici, grazie alla possibilità di specificare il volume anche per l’uscita posteriore. Ovviamente le scritture nel vecchio registro AUD0VOL comportano sempre l’azzeramento dei loro valori, sempre per questioni di retrocompatibilità.

I sistemi ottafonici (7 + 1 canali, ad esempio), invece, si potrebbero realizzare suddividendo i canali in pari e dispari: quelli pari (0, 2, 4, ecc.) verrebbero convogliati nelle prime quattro uscite, mentre quelli dispari (1, 3, 5, ecc.) nelle successive quattro uscite. Il nuovo sottosistema audio, insomma, sarebbe stato pronto per tutte le sfide del futuro.

Non è ancora finita, comunque, perché servono ancora alcune cose per gestire correttamente l’audio. In particolare, i canali dell’Amiga possono essere modulati fra di loro, in periodo (frequenza) e volume, tramite l’uso del registro ADKCON. Poiché tale registro contiene soltanto 8 bit per poter abilitare entrambe le possibilità, vanno necessariamente aggiunti altri registri nell’area 32 bit per poter fare la stessa cosa con tutti e 32 i canali audio. Quindi ci sarà un registro AUDCON0 che avrà 4 x 8 = 32 bit per gestire i primi 16 canali, e AUDCON1 per i seguenti 16.
Secondo, e molto più importante, l’Amiga consente di abilitare individualmente il DMA dei singoli canali audio, tramite il registro DMACON. Chiaramente il meccanismo va espanso, tramite un nuovo registro a 32 bit, AUDDMA, che consente di specificare esattamente per quali dei 32 canali il DMA sia abilitato. Per questioni di retrocompatibilità, scrivere un valore a 16 bit in DMACON che abiliti uno o più canali audio comporterà automaticamente la scrittura di un valore 1 (o 0, se il canale sarà disattivato) nei rispettivi bit di AUDDMA. Per abilitare o disabilitare tutti gli altri canali si dovrà scrivere direttamente in AUDDMA, invece.
A questo punto rimane soltanto da determinare in che modo abilitare gli interrupt per segnalare al processore il completamento della riproduzione di un canale. Ciò avviene col registro INTENA, che funziona in maniera simile a DMACON. Per cui la soluzione sarà la stessa, ma usando un nuovo registro AUDINT.
Per poter generare interruzioni al processore, invece, viene usato il registro INTREQ, che a questo punto richiederà a sua volta un nuovo registro, AUDREQ, che consentirà di fare la stessa cosa di DMACON e INTENA, per tutti e 32 i canali audio.
1993: il tempo del CD32
L’ultima modifica per la nuova piattaforma a 32 bit sarebbe dovuta arrivare con la successiva console della casa, il CD32. Rispetto alle macchine AGA non si sarebbe potuto fare molto, a causa del poco tempo a disposizione per il lancio (poco meno di un anno dopo gli Amiga 1200 e 4000) e alla necessaria politica di riduzione dei costi della piattaforma (in primis a causa dell’integrazione del costoso lettore CD).
Sarebbe stata l’occasione, però, per consolidare le modifiche apportate precedentemente al Blitter, riguardo l’accelerazione delle operazioni di rotazione e zoom, grazie ai semplici cambiamenti effettuati al vecchio sistema di tracciamento delle linee (ma in chiave packed/chunky) e con la possibilità di caricare il valore dei colori direttamente da una texture in memoria Chip.
In questo caso si tratterebbe, in particolare, di ridurre al minimo l’utilizzo della CPU e scaricare finalmente al coprocessore tutto l’onere delle operazioni da svolgere, in modo da liberarla e sfruttare meglio la poca potenza di calcolo a disposizione (non è che un 68EC20 a 14Mhz potesse fare tanto), ma soprattutto dargli la possibilità di processare le informazioni geometriche del prossimo quadrilatero (perché di quello si tratta: niente triangoli, al momento) da renderizzare mentre il Blitter si sta occupando di quello attuale.
Sì, perché questa funzionalità serve sostanzialmente a tracciare quadrilateri (trapezi, per la precisione) dotati di texture:

così da accelerare molto di più l’elaborazione della scena di giochi 3D, che ormai stavano iniziando a prendere piede e che rappresentavano certamente il futuro in ambito videoludico:
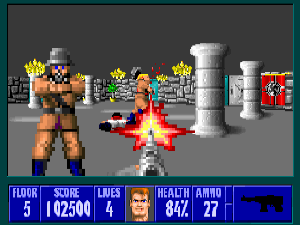
Di ciò erano pienamente consapevoli anche gli ingegneri della casa, i quali hanno candidamente affermato in un’intervista che ne erano a conoscenza già uno o due anni prima del lancio di questa console, sebbene l’unica cosa che siano stati in grado di concepire e realizzare per aiutare il sistema è stata la logica di conversione da packed/chunky a planare che è stata integrata nel famigerato chip Akiko, come abbiamo già ampiamente trattato in alcuni dei precedenti articoli.
L’idea è abbastanza banale sia a livello di funzionamento & utilizzo sia di implementazione in hardware: si aggiungono quattro registri a 32 bit nel nuovo spazio d’indirizzamento a 32 bit di cui abbiamo parlato sopra, i quali conterranno le coordinate (16 bit ciascuna, per x e y) dei quattro punti che delimitano il trapezio, e un altro registro a 32 bit che conserva la lunghezza, in byte, di una riga della texture da utilizzare (che è associata al DMA del canale B, come abbiamo visto in precedenza). E’ da notare che il primo punto è anche quello che coincide col primo valore della prima riga della texture che dovrà essere utilizzato, e così via per tutti gli altri punti e poi le altre righe.
Il Blitter si occuperà di sistemare un po’ di registri interni, partendo da queste informazioni, quando viene selezionata (al posto della modalità linea) e fatta partire quest’operazione, lasciando la CPU completamente libera di proseguire con l’esecuzione di altre istruzioni. In questo c’è la differenza più significativa rispetto a come si imposta il coprocessore quando c’è da tracciare delle linee, in quanto per tali operazioni è il processore si occupa di effettuare un po’ di calcoli preliminari e impostandone poi i registri opportunamente, cosicché il Blitter possa partire immediatamente con l’operazione.
Qui, però, l’obiettivo è esattamente l’opposto: il processore è l’elemento più debole del sistema, computazionalmente parlando, e dobbiamo cercare di fargli pesare i calcoli il meno possibile. Quindi il coprocessore, all’avvio, provvederà a effettuare questi calcoli preliminari (peraltro semplici: si tratta di impostare i valori per l’algoritmo di Bresenham per il tracciamento delle linee, ma per le tre linee più importanti che delimitano il trapezio e che servono a “dirigere” le operazioni), per poi partire col lavoro vero e proprio.
Il quale rappresenta soltanto un’automazione di quanto già visto in precedenza con rotazione e zoom. Per essere più chiari, il concetto alla base è quello di partire dal primo punto del lato più grande del trapezio (guardate la figura precedente, “Quad”, per avere un riferimento visivo), e tracciare una linea che porti da quel punto al corrispondente del lato opposto (tramite la linea adiacente che li collega, ovviamente: questa è la linea che dev’essere tracciata!), utilizzando i byte della texture per tracciare via via i vari punti. In questo è esattamente identico a quanto già presentato.
La differenza sta nel passare “automaticamente” (senza coinvolgere la CPU) al successivo punto di tale linea, e per questo si utilizzano ancora una volta i valori precalcolati (sfruttando sempre l’algoritmo di Bresenham), in modo da trovare il successivo punto iniziale del lato più grande e quello corrispondente del lato più piccolo (che potrebbe anche coincidere con quello precedente: normale che ci siano pixel sovrascritti più volte, quando si parla di grafica 3D), oltre ad aggiustare il puntatore della texture (che potrebbe passare alla riga seguente o rimanere su quella attuale). E così via per tutti punti del lato più grande, finché l’operazione non viene portata a compimento.
Soluzione elementare (qui il funzionamento è stato volutamente semplificato, mostrando un solo scenario, per una questione puramente didattica, ma gli altri scenari sono simili e ricalcano il funzionamento dell’implementazione dell’algoritmo di tracciamento delle linee che è stato implementato nel Blitter. Servono soltanto un po’ di aggiustamenti interni a seconda dei casi, insomma), di facile utilizzo, non affatto complicata da implementare, e che richiede anche poche risorse allo scopo. Ma che, soprattutto, avrebbe fatto un’enorme differenza in termini puramente prestazionali per realizzare i giochi 3D.
Conclusioni
Con ciò si conclude quest’altro lungo articolo (mi spiace, ma c’era anche qui parecchia roba di cui discutere e, in particolare, da esporre) che è focalizzato sulla descrizione del funzionamento e implementazione della nuova piattaforma a 32 bit che sarebbe potuta essere realizzata.
Potrebbe sembrare che ci sia troppa carne sul fuoco, ma in realtà buona parte è stata già dettagliata e realizzata con l’ultima versione del chipset a 16 bit (e 14MHz) presentata nel precedente articolo, di cui questa versione a 32 bit rappresenta un ideale completamento (diciamo che ha completato le basi per i futuri avanzamenti del chipset).
Inoltre e nel frattempo il processo produttivo di casa Commodore è passato dai 2 agli 1,5um, consentendo di poter impacchettare, quindi, 2 / 1,5 = 1,33 = il 33% in più di transistor a parità di area occupata dai chip, permettendo di accomodare principalmente l’espansione delle tavolozze dei colori da 16 a 32 bit. Il tutto, in ogni caso, da prendere con le pinze perché è possibile che il processo MOSFET usato da Commodore possa aver presentato problemi di scalabilità.
Alcuni si potranno chiedere perché l’intero sistema continui a lavorare a 14Mhz e non a 28Mhz, ad esempio, visto che sarebbe stato possibile alzarne anche le frequenze, dopo due anni dal precedente. La risposta è che Commodore doveva tenere conto del suo mercato di riferimento, che è quello a basso costo / mainstream, per cui non poteva strafare. Inoltre continuare ad appoggiarsi alle sue fabbriche MOS è stato un grosso problema in termini di scalabilità (anche in frequenza), che infatti l’ha costretta a rivolgersi ad HP per la realizzazione del chip più complicato dell’AGA (Lisa: il controllore video).
Il prossimo articolo porterà a termine la serie con la definizione della successiva, possibile, piattaforma a 32/64 bit, arrivando anche alle conclusioni.







