
Abbiamo visto come aumentare le frequenze avrebbe potuto consentire di migliorare notevolmente alcuni aspetti molto importanti del chipset dell’Amiga, rimediando (e pure ribaltando!) ad alcuni grossi limiti della sua architettura che, purtroppo, ne hanno ridotto fortemente le potenzialità.
Avere frequenze maggiori è una delle soluzioni banali (a primo acchito) quando si parla di migliorare dei componenti elettronici, come pure un’altra altrettanto “ovvia” e che consente di agire su un altro fronte rimane quella dell’aumento della dimensione dei dati letti da o scritti in memoria (chiaramente a parità di tempo d’accesso).
Entrambe banali perché, per l’appunto, chiunque è in grado di fare proposte di “sparando alto”: è la cosa più semplice e naturale che si possa concepire. La questione, però, rimane quella di contestualizzare (valutare in base anche ai limiti tecnologi dell’epoca) e verificarne l’effettiva efficacia nonché applicabilità alla specifica problematica che si vuole risolvere.
A parte ciò, e come emerso anche nel precedente articolo, bisogna anche vedere se aumentare qualcosa possa aprire porticine (o magari portoni) più o meno nascoste in qualche area, traendo vantaggio delle peculiarità dello specifico sistema. E questa, almeno per me, rimane la parte più interessante e “sfiziosa”.
Superare i 16 bit
L’Amiga, come sappiamo, per lungo tempo è stata considerata una piattaforma a 16 bit. Ingiustamente, poiché l’architettura è a 32 bit. Avendo, però, il bus dati a 16 bit (sia per il processore Motorola 68000 sia per il chipset), se l’è preso come marchio, e anche per questo è considerato un sistema a 16 bit (pure in ambito ludico: “generazione 16 bit”).
L’occasione per passare ai 32-bit (“pieni”) sarebbe potuta essere quella dell’Amiga 3000, che sfoggiando una CPU Motorola 68030 avrebbe consentito di fare il notevole passo avanti. Purtroppo vanificato non soltanto dal chipset (ECS) che è rimasto a 16 bit (tale è dimensione del suo bus per l’accesso alla memoria o da parte del processore), ma perfino dalla memoria Chip.
Infatti questa è l’unica a cui possono accedere i tre chip custom e la quale, pur essendo a 32-bit (solo per la CPU, per l’appunto), costringe il processore a spendere quattro cicli di clock per potervi leggere o scrivere, nonostante possa farlo anche soltanto in un paio di cicli.
Il motivo è che il chipset continua a funzionare come se dovesse servire il processore 68000 (il quale, giusto per semplificare, accede alla memoria ogni 4 cicli di clock), e quindi costringendo qualunque processore a funzionare in tal modo, di fatto dimezzando i possibili accessi e, di conseguenza, la banda totale.
Come se non bastasse, i chip custom sono rimasti sempre con un bus a 16 bit per accedere ai loro registri anche se la CPU ha un bus a 32 bit, quindi richiedendo il doppio del tempo ogni volta. Maggiori dettagli su entrambi questi aspetti si possono trovare in questo thread del più famoso portale dedicato all’Amiga.
Ancora una volta dobbiamo “ringraziare” gli ingegneri di casa Commodore per “chicche” come questa, che hanno castrato l’evoluzione della piattaforma anche quando non ce ne sarebbe proprio stato alcun bisogno.
Limite che è incredibilmente rimasto anche col successivo chipset (gente coerente, gli ingegneri), l’AGA, sebbene finalmente anche per questo il bus dati sia stato portato a 32 bit. Anzi, hanno sfruttato persino la modalità fast page della memoria per poterne leggerne due di dati a 32 bit (quindi 64 bit in totale. In questo caso i dati devono essere allineati a 64 bit, quindi stare sulla stessa “pagina” di memoria).
Di fatto la banda di memoria (quantità di dati che si possono leggere o scrivere nell’unità di tempo) è sostanzialmente quadruplicata, sebbene tale prodigio sia stato riservato esclusivamente al controllore video (per la visualizzare la grafica degli schermi) oppure agli sprite, mentre tutti gli altri dispositivi (disco, audio, Copper e Blitter) sono rimasti completamente a bocca asciutta (di fatto non hanno mai ricevuto modifiche nell’intero arco di vita della nostra amata piattaforma).
Disco a velocità doppia (e quadrupla)
Uno dei crucci dell’Amiga è stato quello che il software sia stato veicolato quasi esclusivamente sul floppy disk, ma a densità doppia (880kB sull’Amiga, nel suo formato standard. Formati personalizzati hanno consentito impacchettare più dati) e abbastanza lenti (erano necessari poco più di 35 secondi per leggere l’intero contenuto di in disco).
PC e Mac, invece, hanno velocemente adottato dischi ad alta (1,44MB) e perfino “estesa” (2,88MB) densità, che a parità di tempi di lettura e scrittura consentivano di trasferirne molti di più (di fatto dimezzando o arrivando a 1/4 del tempo per la stessa quantità di dati).
Anche su Amiga sono arrivati i dischi ad alta densità ma, a causa del numero limitato di accessi alla memoria riservati al DMA del disco, dovevano essere letti alla stessa velocità di quelli a doppia densità, richiedendo quindi il doppio del tempo (e dei drive speciali: non si potevano usare quelli dei PC; peraltro più economici).
Infatti e come abbiamo visto nei precedenti articoli, al disco erano riservati soltanto tre slot dispari per l’accesso alla memoria:
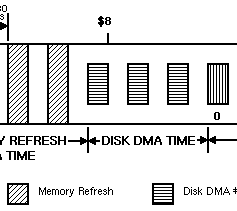
Si sarebbero potuti utilizzare gli slot pari per raddoppiarne il numero, cosa che non ho proposto negli altri articoli (seppur tecnicamente fattibile) per un paio di motivi. Il primo è che non avrebbe consentito di supportare anche i dischi a densità estesa (che avrebbero richiesto un ulteriore raddoppio di tutti gli slot).
Il secondo è che, sempre legato a quest’ultimo caso, ciò avrebbe richiesto la creazione di un ulteriore registro per specificare la lunghezza del buffer da utilizzare per leggere o scrivere i dati provenienti dal disco.
Infatti per il disco si utilizza un registro a 16 bit allo scopo, DSKLEN, che permette di specificare lunghezze di buffer fino a 16383 word (due byte), che sono sufficienti a contenere un’intera traccia di un disco a doppia densità o alta, ma non estesa.
Infine, ma è una mia personalissima opinione, sarebbe stato preferibile sfruttare gli slot per aumentare il numero di canali audio, come ho già illustrato, perché erano oggettivamente più utili a causa della scarsa polifonia della piattaforma (solo 4 canali, quando la concorrenza ne aveva già messi a disposizione molti di più).
Molto meglio, quindi, aspettare di poter avere accesso alla memoria con dati più ampi (32 e 64 bit) per poter estendere anche il funzionamento del disco e supportare i dischi a densità alta ed estesa. Prima, però, bisogna capire come funziona realmente il controllore del disco e come utilizza i tre slot a disposizione (anche perché ci sarà utile anche con le proposte per il miglioramento degli altri dispositivi).
Quando si parla dell’allocazione del DMA per accedere alla memoria da parte i vari dispositivi il concetto più importante da comprendere è che tali slot rappresentano soltanto un’opportunità per essi, che possono decidere di cogliere oppure no (quindi lasciandoli liberi di essere utilizzati da Copper, Blitter, o CPU).
Nello specifico, se il controllore del disco ha qualcosa da leggere o scrivere, allora potrò usare i suoi tre slot allo scopo, o anche soltanto alcuni di essi, a seconda di quanto sia lungo (in termini di word = due byte) il buffer che utilizzerà allo scopo (da leggere per scrivere su disco, e viceversa da scrivere per i dati che sono stati letti dal disco).
Se, ad esempio, deve scrivere dei dati sul disco, allora ne utilizzerà fino a tre per leggere i dati che sono rimasti nel buffer, conservandoli internamente per quando effettivamente i singoli bit dovranno essere trasferiti sulla testina magnetica per portare effettivamente a termine l’operazione.
Quando, invece, sta leggendo i dati dal disco, li accumulerà internamente fino a quando non avrà pronte fino a tre word da dover scrivere in memoria nel buffer che dovrà utilizzare.
E’ bene sottolineare che il controllore del disco è costretto a utilizzare un buffer interno, in quanto i dati letti dal disco o che si devono scrivere sul disco vengono letti o scritti “sempre”, man mano che la testina si trova su una particolare posizione sul disco. Ciò significa che non ha alcuna libertà di poter scegliere quando accedere alla memoria per accedere al suo buffer, per cui può e deve farlo soltanto nei tre slot a esso allocati.
Ed è proprio il concetto di buffer interno che risulta fondamentale per capire come si sarebbe potuta sfruttare al meglio la possibilità di leggere/scrivere 32 o 64 bit dati dalla/in memoria un solo colpo (come fa l’AGA), estendendola anche a tutti i dispositivi in maniera semplice e non invasiva (come vedremo più avanti).
Nel caso del disco la soluzione sarebbe stata semplice e trasparente, perché ci sono due sensori (collegati a delle linee del cavo che collega il computer al drive) che consentono di stabilire se il disco inserito sia a densità normale, alta, o estesa. Per il s.o. è sufficiente leggerne lo stato per regolare di conseguenza la dimensione del buffer da utilizzare e quante word (due byte) si dovranno leggere o scrivere, avendo anche cura di allineare il buffer a 32 o 64 bit (a seconda dei casi).
Il controllore del disco (a cui dovranno arrivare i dati dei due sensori in modo da tenerne conto anch’esso) dovrà avere, a sua volta, il buffer interno raddoppiato (per leggere e scrivere 32 bit alla volta, per i dischi ad alta densità) o quadruplicato (per leggere e scrivere 64 bit alla volta per i dischi a densità estesa).
Quindi anziché 3 word (2 x 3 = 6 byte), dovrà avere 3 longword (4 x 3 = 12 byte) o 3 quadword (8 x 3 = 24 byte) a seconda della dimensione massima del “bus” verso la memoria (l’ho messo virgolettato per indicare che non si tratta propriamente del bus, ma della capacità di accedere a dati anche più grandi del bus stesso, come appunto si fa con la summenzionata modalità fast page).
Anche il registro DSKLEN cambierà automaticamente di conseguenza: se il sensore rivela un disco ad alta densità, allora non conterrà il numero di word da leggere o scrivere, ma il numero di longword. Mentre indicherà il numero di quadword se è attivo il sensore della densità estesa.
A questo punto il gioco è fatto: pur coi soli tre slot a disposizione sarebbe stato possibile supportare dischi a densità alta ed estesa, con cambiamenti minimali e, soprattutto, a piena velocità.
Canali audio a frequenze più elevate e con campioni a 16 bit
Un ragionamento simile si sarebbe potuto fare anche coi canali audio, poiché utilizzano anch’essi dei buffer interni per memorizzare i campioni da riprodurre man mano dal buffer a loro associato.
Essendoci un solo slot per ogni singolo canale:
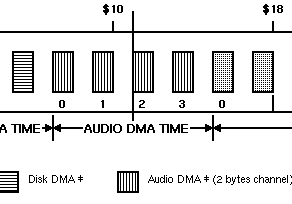
è possibile leggere una sola word dalla memoria, che contiene due campioni a 8 bit da riprodurre (l’audio dell’Amiga è a 8 bit, come sappiamo). Internamente il controllore audio si occuperà di utilizzare il primo campione, e passerà al secondo quando ce ne sarà bisogno (cioè quando sarà “scaduto” il periodo di riproduzione del primo).
Leggendo 32 o 64 bit dalla memoria si sarebbero potute supportare frequenze più elevate dei 28khz massimi normalmente consentiti dal singolo slot a 16 bit, raddoppiandone (con 32 bit) o quadruplicandone (64 bit) la dimensione del buffer interno.
In questo modo si sarebbe potuto arrivare tranquillamente a frequenze di riproduzione di 56 o 112khz, rispettivamente, rimanendo sempre con campioni a 8 bit. Col vincolo, come già esposto nel caso del disco, di avere il buffer allineato a 32 o 64 bit.
Il tutto in maniera trasparente, perché non sarebbe servita alcuna modifica ai registri interni né tanto meno al modo in cui il s.o. e gli sviluppatori programmano i canali audio, a parte la dovuta accortezza dell’allineamento del buffer alla rispettiva dimensione del “bus” dati.
Una piccolissima modifica sarebbe stata necessaria, invece, per supportare agli agognati (e sognati!) campioni a 16 bit, in quanto è necessario indicare al controllore audio la loro presenza, in modo che possa regolarsi di conseguenza sul come trattare i dati presenti nel buffer interno e, chiaramente, come inviarli al DAC (che ovviamente dovrebbe essere passato da 8 a 16 bit) per la loro conversione in segnale sonoro vero e proprio.
In questo caso il bit #7 dei registri AUDxVOL associati a ogni singolo canale audio è libero e può essere tranquillamente riservato allo scopo. Anche il bit #15 è libero, e combinato col #7 avrebbe consentito di far evolvere ulteriormente l’audio in futuro, per supportare campioni diversi (32 bit e fp32, ad esempio).
Abilitando i campioni a 16 bit scenderebbero, però, di conseguenza anche le frequenze massime supportate a 14, 28 e 56khz per dimensioni del “bus” dati rispettivamente a 16, 32 e 64 bit. Ma penso che si tratti di limiti ampiamente digeribili, pur di poter usufruire di questa nuova (nonché attesissima, negli anni ’90) funzionalità.
Va sottolineato anche qui che le modifiche richieste, oltre che minimali (fatta eccezione per il DAC a 16 bit, ovviamente), sono totalmente retrocompatibili con tutto il software già esistente per Amiga (e che abbia seguito fedelmente le linee guida della casa madre. Cosa tutt’altro che scontata, purtroppo).
Il Copper con gli steroidi mette il turbo
Tutti i dispositivi aventi slot di allocazione del DMA fissi / predeterminati sono stati coperti, ma il concetto di utilizzare buffer interni per memorizzare più dati provenienti dalla memoria con bus “ampliato” si sarebbe potuto applicare anche al Copper, che invece legge i dati delle sue istruzioni semplicemente… quando può, e le esegue appena ha a disposizione tutti i loro bit (32).
Infatti anche lui fa uso di un buffer interno, essendo costretto ad aspettare di aver letto le due word (col bus a 16 bit) della prossima istruzione, e soltanto in questo caso, finalmente, procedere alla sua esecuzione.
Estendendo il “bus” a 32 e 64 bit si potrebbe aumentare di conseguenza anche il suo buffer interno, portandolo da una word (quella letta in precedenza) a una longword (32 bit) o quadword (64 bit), a seconda della dimensione del “bus”, ma avendo l’accortezza di aggiungere un contatore interno che segnali il numero totale di word che sono ancora disponibili (dopo l’istruzione appena eseguita).
Il comportamento del Copper dovrebbe cambiare leggermente, a questo punto. Infatti quando è pronto per eseguire la prossima istruzione e ci sono almeno due word nel buffer interno allora può utilizzarle per eseguire immediatamente tale istruzione, togliendole poi dal buffer (spostando all’inizio le eventuali word rimaste, e aggiornando il contatore interno).
Un vantaggio immediato di questa semplice soluzione è che il Copper consumerà la metà (con “bus” dati a 32 bit) di banda di memoria o un quarto (con “bus” a 64 bit), lasciando quindi liberi parecchi slot che possono essere utilizzati dal Blitter o dalla CPU.
Un altro è che sarebbe almeno il doppio più veloce se le istruzioni in memoria fossero allineate almeno a 32 bit (come dovrebbe essere comunque già naturale fare), perché in questo modo quando andrà a leggere dalla memoria si troverà subito coi 32 bit che gli servono per la sua istruzione, senza dover aspettare il prossimo slot libero per caricare il secondo pezzo completando l’istruzione.
In realtà col “bus” a 64 bit potrebbe andare ancora più veloce, considerato che in un colpo solo riesce a caricare ben due istruzioni alla volta (sempre tenendo conto che il buffer dovrebbe essere allineato a 64 bit).
In questo caso potrebbe eseguire la seconda istruzione immediatamente dopo la prima, quindi nel successivo ciclo di clock di sistema. Ricordo, infatti, che uno slot di accesso in memoria equivale a due cicli di clock, per cui la seconda istruzione potrebbe anche esser fatta eseguire nel primo ciclo di clock di sistema successivo (la prima “metà” dello slot seguente). Il tutto mentre il DMA si prepara a leggere il dato in memoria seguente (altri 64 bit).
Un Copper così veloce consentirebbe di poter eseguire molti più effetti visivi: in primis il cambio della tavolozza dei colori (operazione abbastanza comune), ma anche il multiplexing degli sprite ne trarrebbe un enorme vantaggio. Se poi ci aggiungessimo anche il caricamento di più registri con una sola istruzione (modifica suggerita in un precedente articolo), si raggiungerebbe l’apoteosi…
Similmente, anche la precedente proposta di un canale DMA autonomo per caricare direttamente i registri dei tre chip (in primis per i colori; come al solito) trarrebbe un enorme vantaggio dalla possibilità di leggere 32 o 64 bit alla volta anziché i canonici 16, dimezzando o richiedendo 1/4 del tempo.
Queste meraviglie, però, non potrebbero né dovrebbero essere messe a disposizione subito, perché verrebbe meno la piena compatibilità col software già scritto, il quale si aspetta che il Copper si comporti in maniera molto precisa.
La soluzione a questo problema è la stessa che è stata presentata nell’articolo che ha proposto l’introduzione del caricamento di più registri alla volta tramite l’istruzione MOVE del Copper: si deve abilitare appositamente, utilizzando il medesimo bit. Quindi se si abilita la nuova MOVE si abiliterà al contempo l’uso del buffer esteso a 32 o 64 bit e, di conseguenza, l’esecuzione più veloce delle istruzioni.
Il Blitter spreca molta meno banda (e forse è pure molto più veloce)
Anche il Blitter avrebbe potuto beneficiare di alcuni miglioramenti derivanti dalla possibilità di accedere a dati più grandi in memoria nello stesso tempo, sebbene forse (è solo un’ipotesi) non potendo trarne gli stessi vantaggi in termini puramente prestazionali (come analizzeremo più avanti).
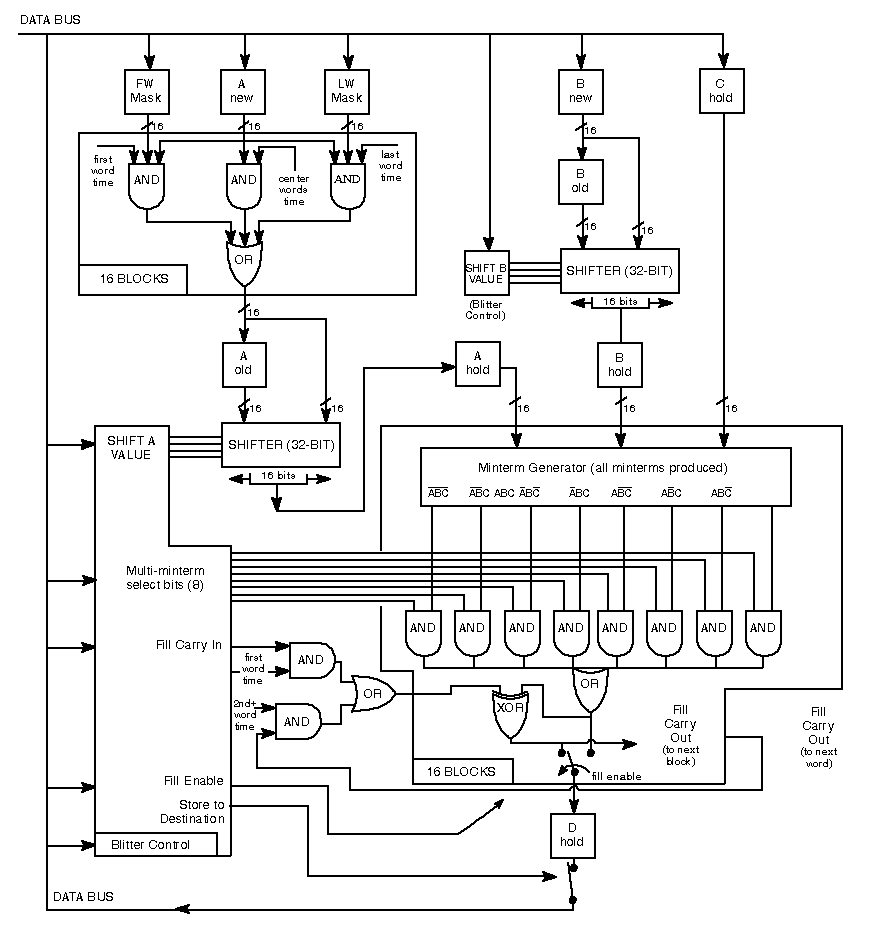
Infatti pure lui fa uso di alcuni buffer interni in cui memorizza, per poi utilizzare quando gli servono, i dati letti dalla memoria dai tre canali DMA che ha a disposizione (chiamati A, B e C), e infine scrivere il risultato della loro elaborazione in memoria usando un ulteriore canale (D):
I buffer esistenti (per i canali A e B. Per il C se ne potrà aggiungere uno) possono, quindi, essere estesi in maniera similare a quanto visto per il Copper, in modo da memorizzare le word (due byte) lette dalla memoria e la loro quantità. Infatti, anche se è possibile leggere dati a 32 (2 word) o 64 bit (4 word), non si potranno utilizzare tutte le word, perché i canali e il Blitter lavorano sempre su singole word alla volta, e alcune di quelle lette potrebbero essere inutili per le operazioni che questo coprocessore deve svolgere.
Ad esempio, se il canale A punta alla locazione di memoria $01DED2 e il bus legge 64 bit in quella zona di memoria, lo farà usando $01DED0 come indirizzo (perché i dati a 64 bit devono sempre essere allineati a indirizzi multipli di 8, quindi vengono scartati i primi 3 bit dell’indirizzo, e si usa $01DED0).
Poiché i dati che servono al canale A partono da $01DED2, vuol dire che delle 4 word lette la prima verrà scartata (perché si trova a $01DED0), mentre saranno conservate internamente le seguenti tre perché sono o potrebbero essere utili successivamente.
Dunque, e pur potendo leggere sempre 64 bit, non sarà sempre possibile sfruttare tutte e quattro le word lette. Il potenziale c’è, ma per essere sfruttato al massimo serve che i dati siano sempre allineati alla dimensione del “bus” dati. Cosa non sempre possibile, ma molto spesso se ne potrebbe trarre vantaggio (è il caso medio che in questo caso è importante, e non quello peggiore).
Il vantaggio risiederebbe nel fatto che se, ad esempio, un canale dovesse lavorare con tre word che si trovassero una di seguito all’altra in memoria, e sfruttando il “bus” a 64 bit quelle tre word sarebbero state lette tutte in un colpo solo, allora il Blitter non avrebbe bisogno di eseguire tre distinti accessi per recuperarle, ma soltanto uno.
Quindi con un notevole risparmio di banda di memoria e con la possibilità di lasciare gli altri due slot liberi alla CPU, ad esempio, che in questo modo potrebbe avere molte più possibilità di lavorare in parallelo col Blitter, spartendosi il lavoro in alcuni casi.
In teoria questo non dovrebbe trattarsi dell’unico guadagno derivante dall’utilizzo di buffer interni più ampi per accomodare i dati che serviranno in futuro al Blitter, in quanto avendoli già a disposizione potrebbe continuare nell’elaborazione “immediatamente” senza dover aspettare di leggerli.
Per chiarirlo bisogna comprendere come lavora il Blitter. Ad esempio, quando deve utilizzare tutti e tre i canali per un’operazione complessa (e molto comune nei giochi o nel disegno della grafica dell’interfaccia utente), deve prima leggere dalla memoria i dati di tutti e tre, e soltanto dopo potrà usarli per l’elaborazione, producendo il dato che dovrà essere scritto (sempre in memoria).
Per cui la sua velocità di esecuzione sarebbe sostanzialmente limitata dall’attesa dei dati che gli servono. Ma se i dati fossero già a disposizione perché contenuti nei buffer interni grazie al “bus” più ampio dei canonici 16 bit, allora in teoria potrebbe iniziare subito a processare la successiva operazione e spedirla in memoria.
Il condizionale è d’obbligo, perché tutto dipende da come sia implementato internamente questo coprocessore, che risulta dotato di una pipeline per suddivide in maniera efficiente tutte le operazioni interne che deve compiere per raggiungere il risultato finale:

Se non ci sono dipendenze fra i vari stadi della pipeline (ad esempio operazioni che sono state appositamente pianificate per essere eseguite a un certo stadio, tenendo conto degli accessi alla memoria che sono sempre necessari), allora si potrebbe applicare quello che tecnicamente viene chiamato “bypass” e, quindi, “saltare” lo stadio di lettura del dato per quel canale (o anche per tutti, se i loro dati sono già presenti nel buffer interno) e passare direttamente al prossimo stadio interessato (la lettura del dato del canale che non ha dati e deve attingerli dalla memoria, oppure quello del calcolo vero e proprio).
In questo modo le prestazioni del Blitter potrebbero arrivare a più che raddoppiare, se consideriamo che con un “bus” a 64 bit e nelle migliori condizioni (tutti i canali sono allineati a 64 bit) verrebbero lette 4 word per ogni canale, quindi richiedendo 3 slot (equivalenti a 6 cicli di clock), per poi richiedere 4 slot (8 cicli di clock) per scrivere le 4 word del risultato in memoria.
Totale: 14 cicli di clock (e 3 + 4 = 7 slot per l’accesso alla memoria consumati), quando per fare lo stesso col bus dati a 16 bit sarebbero stati richiesti (rozzamente) 4 x 8 = 32 cicli di clock (e 8 slot consumati).
A livello di slot si potrebbe ancora ottimizzare qualcosa usando un buffer interno anche per le word dei risultati, arrivando a scriverne 4 in memoria (con “bus” a 64 bit) in un colpo solo nelle migliori condizioni (col canale D allineato a 64 bit).
Non cambierebbe nulla a livello prestazionale (perché il Blitter lavora sempre internamente una word alla volta, producendo una word come risultato per ogni slot), ma verrebbero risparmiati tre preziosi slot che la CPU potrebbe sfruttare a suo vantaggio.
Il tutto, lo ribadisco, nell’ipotesi che si possano effettuare bypass degli stadi della pipeline di questo coprocessore quando i dati necessari risultino già nei buffer interni. Altrimenti le prestazioni sarebbero sempre le stesse, e l’unico risparmio possibile sarebbe quello degli slot in memoria (che sarebbe comunque ottimo per foraggiare per bene anche il processore, il quale a questo punto sarebbe in grado di smazzarsi un bel po’ di calcoli in maniera indipendente, contribuendo in maniera sostanziale alle prestazioni complessive del sistema).
Sfruttiamo gli slot liberi con… un secondo Blitter!
Un modo per sfruttare gli slot lasciati liberi dal Blitter senza che finiscano alla CPU (che, tra l’altro, potrebbe anche non sfruttarli se è occupata con calcoli interni, per cui andrebbero sprecati) ci sarebbe: basterebbe aggiungerne una copia.
Quindi un secondo Blitter, con un proprio banco di registri oppure condividendo gli stessi in maniera trasparente. Quale che sia la soluzione, non mi voglio dilungare nella spiegazione, perché aggiunge complicazioni che devono gestire i programmatori (in che modo sfruttarli al meglio / tenerli occupati, e soprattutto senza che si “pestino i piedi” andando a lavorare sulle stesse aree di memoria).
Sia chiaro che sarebbe stato sicuramente fattibile e avrebbe consumato tranquillamente tutti gli slot lasciati liberi dal primo Blitter (oltre a rendere complessivamente il sistema circa quattro volte più veloce rispetto all’originale), ma avrebbe richiesto un bel po’ transistor e, quindi, una complessità che va oltre lo scopo delle modifiche minimali al chipset che si sono prefissati questi articoli (almeno finora).
Sfruttare dati più grandi
Infatti sfruttare al meglio la maggior ampiezza del “bus” in memoria si potrebbe certamente fare, senza ricorrere a questi espedienti: “basterebbe” (!) estendere il funzionamento del Blitter dalle singole word (16 bit) alle longword (bus a 32 bit) oppure alle quadword (“bus” a 64 bit), ed eventualmente anche di più, a seconda dell’interfaccia disponibile verso la memoria.
In tal modo questo coprocessore continuerebbe a richiedere sempre 4 slot (pari a 8 cicli di clock) per portare a termine una singola operazione interna (tre per leggere i dati dei canali A, B e C. Uno per scrivere il risultato tramite il canale D. Questo nello scenario più complesso), ma a 32 o 64 bit (o più) anziché a 16 bit, massimizzando lo sfruttamento dell’accesso alla memoria (e, di riflesso, le prestazioni: fino a quattro volte… o più).
A parole sembra facile, perché nella comunità Amiga si è sempre parlato molto di un fantomatico Blitter a 32 bit per poterne migliorare (raddoppiare) le prestazioni, ma un siffatto oggetto non è mai apparso né stato rivelato (se non nella documentazione di alcuni chipset in lavorazione, come l’AA+ e l’AAA).
Alcuni tentativi sembra siano stati fatti con progetti come il Natami (di cui abbiamo parlato anche in queste pagine), ma a memoria ricordo che in qualche thread del loro forum si fosse parlato del fatto che i progettisti non fossero soddisfatti delle prestazioni ottenute.
Comunque la questione più importante, a mio avviso, è che tutti questi tentativi di espandere questo coprocessore a 32 bit non sarebbero state delle soluzioni valide e scalabili per il futuro. Basti pensare, infatti, alla possibilità di leggere e scrivere 64 bit alla volta: sarebbe stato necessario un nuovo Blitter a 64 bit? E quando sarebbero arrivati i 128 bit, di nuovo un altro? E così via.
E’ evidente che questa mentalità alquanto ristretta (e ben poco creativa!) di riprogettare ogni volta un componente, soltanto perché è possibile accedere a più dati, non funzioni: rappresenta la classica pezza da mettere velocemente per risolvere il problema contingente, senza una visione per il futuro. Oltretutto scaricandone interamente l’onere sui programmatori (che dovranno adattare il loro codice al nuovo componente. Ogni volta!).
Il Blitter “agnostico” (non legato al “bus”)
Ciò che serve è, invece, un componente che funzioni ed offra un’interfaccia coerente e scalabile automaticamente per il futuro, senza ulteriori modifiche, a parte quelle esclusivamente interne per adattarsi alle nuove memorie.
Potrà sembrare assurdo, ma il Blitter non ha bisogno di alcuna modifica a nessun suo registro, in quanto la sua interfaccia per i programmatori offre già tutta l’astrazione necessaria per gestire qualunque richiesta nella maniera migliore possibile, a prescindere dalla dimensione del “bus” dati a cui è collegato.
L’unica modifica necessaria (e questo vale anche per l’allargamento dei buffer interni di cui si è parlato nella precedente sezione) è un solo bit in uno dei suoi registri di controllo, che possa abilitare appositamente il nuovo comportamento, in modo da preservare la compatibilità col software già scritto e che si aspetta un funzionamento rigorosamente diverso (come mostrato nel diagramma della sua pipeline mostrato sopra).
Tutto il resto è e dev’essere gestito internamente, con questo coprocessore che dovrà adattarsi alla richiesta che ha ricevuto, tenendo conto della dimensione massima del “bus” a cui è collegato e, quindi, di quanto grandi siano i dati che può (e deve) manipolare.
Cosa tutt’altro che chiara, mi rendo conto, perché finora è estremamente difficile capire come un dispositivo nato e che funzioni sulla rigorosa base di manipolare word (16 bit) possa lavorare tranquillamente su dati di dimensione ben più grande e gestire (molto meglio) le stesse, identiche, richieste che gli arrivano (ripeto: non va modificata una virgola di come si programma, a parte il suddetto bit da abilitare).
Poiché le questioni sono strettamente tecniche e l’articolo è già arrivato a una considerevole lunghezza, mi limiterò a illustrare l’idea di base senza appesantirne troppo la trattazione, concentrandomi su alcuni concetti di fondamentale importanza.
Il primo è che, pur essendo vero che il Blitter lavori con singole word alla volta, lo fa comunque su un’area rettangolare che deve processare. Per far questo divide il suo lavoro in righe (tutte di uguale dimensione = numero di word), e questo è il primo concetto sul quale soffermarci.
Infatti le word vengo lette mano a mano, ma ciò soltanto perché si deve processare l’intera riga che si trova al momento (quando è stato dato il via all’attività) in lavorazione (possiamo ignorare per il momento il fatto che l’area di lavoro sia rettangolare, perché alla fine si tratta di applicare sempre le stesse operazioni per ogni riga).
Questo perché le word lette vengono, molto spesso, concatenate. I canali A e B di questo coprocessore sono in grado di eseguire lo scorrimento (a destra o sinistra, a seconda di come sia stato impostato, da 0 a 15 bit/pixel) dei bit di tali word, in modo da allineare la grafica alla posizione desiderata (in pixel).
Lo si può vedere nel diagramma interno: A e B sono gli unici che hanno questa possibilità, e lavorano 32 bit alla volta (facendo uso di due word consecutive lette). Mentre i canali C e D non necessitano di alcuno scorrimento: la loro grafica è già pronta per essere utilizzata o inviata in memoria, rispettivamente.
Per cercare di semplificare, i canali A e B sono usati per grafica che si può trovare “disallineata” rispetto alla posizione orizzontale (in pixel) dello schermo sulla quale vogliamo che la loro grafica sia visualizzata. Per questo motivo è data la possibilità di scorrere i loro dati: per posizionarli esattamente dove vogliamo.
Mentre il canale C non ne ha bisogno, perché (generalmente) punta proprio alla grafica dello schermo che verrà aggiornata (in questo caso viene caricata la sua grafica attuale, prima della modifica). Per lo stesso motivo, il canale D non prevede alcuno scorrimento, dato che alla fine conterrà la grafica aggiornata (alla fine di tutte le elaborazioni coi canali A, B e C).
Poiché questo coprocessore lavora sempre e comunque con word (16 bit), ciò significa che deve prendere la grafica da A e B, posizionarle opportunamente orizzontalmente, estrarne/usarne soltanto 16 bit (dei 32 bit letti), combinarli con quelli di C (16 bit), e infine conservare il risultato (16 bit) usando D. L’idea, quindi, è di poter ottenere 16 bit da questi “aggiustamenti”, in modo da poterli scrivere in memoria (che può essere letta o scritta soltanto in word).
Con un “bus” a 64 bit il concetto è esattamente lo stesso, solo che in questo caso avremmo bisogno di specificare scorrimenti da 0 a 63 per i dati provenienti canali A e B. Inoltre la loro grafica dovrebbe essere sempre allineata a 64 bit.
Solo che non c’è spazio nei registri del Blitter per aggiungere i bit necessari allo scopo, ma in ogni caso questa soluzione andrebbe contro il ragionamento esposto in precedenza, dove si vorrebbe che i suoi registri rimanessero esattamente gli stessi a prescindere dalla dimensione del “bus” (d’altra parte coi 128 bit si dovrebbero aggiungere ancora altri bit allo scopo, e così via con “bus” più grandi).
Inoltre a questo coprocessore viene sempre indicato il numero di word su cui lavorare per ogni riga, per cui a ogni variazione della dimensione del bus servirebbe aggiungere altri bit anche qui. E’ chiaro che non potrà mai funzionare nulla del genere, perché non sarebbe assolutamente scalabile.
La soluzione al problema: sfruttiamo quello che abbiamo già!
La soluzione che ho trovato è quella di continuare a utilizzare le word come unità base per le operazioni del Blitter, ma sfruttando le informazioni presenti nei puntatori (locazioni di memoria) ai dati di tutti e quattro i canali di questo dispositivo, in modo da regolare automaticamente e internamente tutte le operazioni di scorrimento e mascheramento.
Faccio un esempio col canale A (che è il più complesso, considerato che a esso sono associati anche due registri appositi per mascherare la prima e l’ultima word che vengono lette per ogni riga che dev’essere elaborata), ma il concetto è esattamente lo stesso anche per il canale B (senza le due maschere) e per i canali C e D (senza alcuno scorrimento al singolo pixel; ma vanno leggermente cambiati anche loro).
Supponiamo che il canale A punti alla locazione $01DED4 per i suoi dati, che sia stato chiesto al Blitter di elaborare una zona rettangolare con righe di 3 word, che il “bus” sia a 64 bit (quindi si possono leggere o scrivere ben 4 word alla volta), e che i dati di A debbano subire uno scorrimento di 5 bit/pixel a destra.
Normalmente, col bus a 16 bit, il canale A avrebbe bisogno di leggere due word prima di poter utilizzare questi dati, a causa dello scorrimento di 5 bit che è stato richiesto. Infatti se si leggesse soltanto la prima word e si scorressero i suoi 16 bit a destra di 5 posti, non potrebbe continuare a lavorare perché gli mancherebbero altri 5 bit, per l’appunto.
Deve, quindi, leggere due word, combinarle (metterle una di seguito all’altra), e a questo punto ha (almeno) 16 bit (ne ha 27, per la precisione) da poter combinare coi 16 bit provenienti dai canali B e C, e ricavare i 16 bit da mandare a D.
Lo stesso concetto va applicato anche adesso che il bus è a 64 bit. Però la suddetta locazione di memoria non è allineata a 64 bit. Infatti avrebbe dovuto essere $01DED0 oppure $01DED8. Ma il programmatore non è a conoscenza della dimensione del “bus”, per cui ha fatto la sua legittima richiesta senza tenerne conto, e il Blitter dovrà comunque portare a termine l’operazione.
In questo caso egli leggerà tutte e quattro le word al primo indirizzo, ma dovrà scartare le prime due (perché si trovano agli indirizzi $01DED0 e $01DED2, mentre il canale A parte da $01DED4), conservando però la quarta word (che si trova all’indirizzo $01DED6) perché fa parte delle tre word (per riga) che gli è stato chiesto di processare.
Quindi ha letto 2 word = 32 bit, che però non sono sufficienti, in quanto a ogni passo dell’elaborazione il Blitter ha bisogno di ricevere 64 bit da tutti e 3 i canali, prima di poter generare i 64 bit da inviare in memoria tramite il canale D. Inoltre delle tre word su cui lavorare manca ancora l’ultima (soltanto le prime due sono state già lette).
Per cui, ed esattamente come col bus a 16 bit, sarà costretto a leggere altri 64 bit, cioè le 4 word che si trovano successivamente (a partire dall’indirizzo $01DED8). Solo che di queste prenderà soltanto la prima, perché le altre tre non gli servono (gli è stato richiesto di lavorare solo su tre word per riga, che adesso sono tutte disponibili).
A questo punto può combinare i 32 bit che aveva letto prima coi 16 bit che ha letto adesso, per formare un valore a 48. Non ancora sufficiente per arrivare ai 64 bit necessari, ma non è importante perché in memoria possono finire soltanto 3 word (48 bit), ragion per cui l’ultima word dell’elaborazione verrà comunque scartata (il canale D scriverà in memoria soltanto le prime 3 word di ciò che riceverà: o con un singolo accesso se stanno tutte all’interno di 64 bit allineati, oppure con due accessi diversamente).
Il significato di scartare le prime due word del canale si traduce tecnicamente nello scorrere di 2 * 16 = 32 bit a destra la grafica del canale A, in modo da posizionare correttamente le uniche due word a cui siamo interessati. Avendo impostato lo scorrimento a 5 nell’esempio, vuol dire che la grafica dovrà scorrere a destra di 2 * 16 + 5 = 37 posizioni. Adesso ci siamo!
Questo semplice meccanismo vale anche per tutti gli altri canali, come già detto, per cui va replicato esattamente allo stesso modo. Il canale A, però, ha anche due “maschere” che vengono utilizzate per la prima e l’ultima word che vengono lette. Le maschere sono a 16 bit, ma i dati letti sono a 64 bit, quindi serve effettuare una modifica anche qui, estendendo opportunamente le maschere a 64 bit (ma soltanto internamente).
Abbiamo visto che la prima word si trova all’indirizzo $01DED4. Il Blitter sfrutterà questa informazione per costruire la maschera a 64 bit, in questo modo:
- siccome le prime due word (
$01DED0e$01DED2) vanno scartate e non c’interessa il loro valore, quindi i primi 32 bit (quelli più alti, visto che Amiga è una piattaforma big endian) della maschera saranno a zero; - i successivi 16 bit li prenderà dal registro della prima maschera (BLTAFWM);
- infine gli ultimi 16 bit li imposterà tutti a 1 (valore
$FFFFin esadecimale) perché siamo interessati a usare anche l’ultima word ($01DED6).
Per la maschera relativa all’ultima word si fa la stessa cosa, ma in maniera inversa:
- si mettono a 1 (sempre
$FFFF) tutte le word del canale A che eventualmente precedono l’ultima word, perché li dobbiamo usare. - si copiano i 16 bit dal registro dell’ultima maschera (BLTALWM);
- si mettono a zero eventuali altre word che seguono (perché non c’interessano).
A questo punto, e con questa logica implementata, il Blitter è pronto per poter operare con “bus” dati di qualunque dimensione, senza che venga toccato di una virgola il modo in cui programma, a parte impostare un bit in uno dei suoi registri di controllo per abilitare il nuovo comportamento (sempre per questioni di retrocompatibilità).
Il vantaggio è che in 4 slot (8 cicli di clock) è in grado di elaborare 32 bit alla volta con bus di 32 bit, 64 bit alla volta con bus di 64, e così via per future dimensioni più elevate, sfruttando sempre tutti gli accessi alla memoria possibili esattamente come fa il Blitter a 16 bit (quindi senza la necessità di un secondo Blitter per sfruttare gli slot inutilizzati).
Ovviamente le prestazioni dipenderanno sempre dall’allineamento in memoria dei dati dei vari canali. Nel caso migliore e con bus a 64 bit, ad esempio, sarà veloce quattro volte rispetto all’originale. Nel caso peggiore andrà esattamente allo stesso modo.
Quindi sarà cura del s.o. e/o dei programmatori sfruttare la maggior dimensione del bus in modo da massimizzarne le prestazioni, ma semplicemente avendo cura di allineare opportunamente le zone di memoria per i quattro canali.
Conclusioni
Direi che di carne al fuoco ne sia stata messa abbastanza, e mi scuso per la lunghezza dell’articolo, ma c’era parecchio di cui parlare questa volta, con altre modifiche molto significative che avrebbero certamente lasciato il segno (specialmente per quanto riguarda i videogiochi).
Purtroppo mi rendo conto che l’ultima parte sia particolarmente complessa da digerire, soprattutto per chi non è a conoscenza di come funzioni il Blitter e magari non abbia avuto modo di programmarlo (in ambito ludico, in particolare).
Ho cercato di semplificare il più possibile il discorso, facendo anche alcuni esempi, ma l’argomento è squisitamente tecnico, per cui lascia pochi spazi per una trattazione che sia abbordabile ai più (sarebbe stato necessario un tutorial, in modo da illustrare il tutto con esempi reali, che però andrebbe ben oltre gli scopi).
Mi auguro che per lo meno i concetti chiave siano stati assimilati e che ci si sia fatta un’idea delle potenzialità e delle ricadute che i vari aggiornamenti proposti avrebbero portato, la maggior parte dei quali peraltro abbastanza semplici da essere implementati.
Il prossimo articolo avrà un taglio completamente diverso, perché offrirà una breve panoramica dei chipset che si sono succeduti al primo (OCS) introdotto col glorioso Amiga 1000, nonché dei vari “lavori in corso” (sia alcuni esperimenti sia i chipset in corso d’opera e mai nati), e del perché non hanno avuto o non avrebbero avuto un impatto significativo per rendere competitivo il nostro adorato computer.
Ciò in preparazione della parte finale della serie che, avendo già affrontato tutte le questioni più importanti e annesse proposte di miglioramenti, volge ormai al termine.







