
Il precedente articolo ha completato la panoramica di NEx64T, per cui è adesso possibile disporre di parecchie informazioni (incluse alcune statistiche, riportate in altri articoli della serie) che forniscono già un’idea abbastanza chiara sulle caratteristiche nonché potenzialità di questa nuova architettura.
Ci si potrebbe chiedere adesso perché spendere così tanto tempo e risorse su un progetto come questo, al di là del puro piacere che possa avere un appassionato di architetture degli elaboratori nel progettarne una (cosa non rara, in quest’ambito).
Penso sia naturale fantasticare sul giocattolino che si è costruito con le proprie mani, ma la storia e la realtà servono a riportarci coi piedi per terra. La storia c’insegna che sono state realizzate parecchie nuove architetture, ma la realtà ci mostra come sia veramente difficile poter entrare in un campo / mercato come questo, considerato che ben poche siano quelle sopravvissute.
Per quanto “dirompente” possa sembrare un’architettura, le sue caratteristiche di targa non sono l’unico fattore che conta e che sono in grado di smuovere le acque, aprendo una breccia in una realtà abbastanza consolidata nonché polarizzata (considerati i pochi rappresentanti che attualmente si spartiscono quasi tutta la fetta, lasciando le briciole ad alcune di nicchie).
Quindi è fondamentale capire in primis se passare dal gioco a qualcosa di più serio sia corroborato da elementi più solidi dei sogni, e nello specifico raccogliere informazioni su quali siano i punti che ne rappresentino il valore aggiunto, utilizzando le architetture standard di fatto quali benchmark con cui confrontarsi.
Confronto con x86 e x64
In questo caso NEx64T non parte in salita in quanto, proponendosene come riscrittura & evoluzione, trova in x86 e x64 le principali architetture di riferimento, e con le quali diversi confronti su aspetti nonché metriche molto importanti sono già stati effettuati e illustrati nei precedenti articoli della serie, che riporto brevemente per grandi linee:
- estrema semplicità di decodifica delle istruzioni –> frontend (decodificatori) molto più piccolo e semplice –> molti meno transistor necessari –> minori consumi;
- le pipeline possono essere più corte, con benefici simili ai precedenti, a cui si aggiungono quelli prestazionali (minor penalizzazione nel caso di salti non predetti correttamente);
- assenza di parecchie istruzioni legacy e riorganizzazione delle istruzioni –> backend (unità di esecuzione) più semplici –> molti meno transistor necessari –> minori consumi;
- migliore densità di codice –> minor accesso a tutta la gerarchia di memoria –> migliori prestazioni & minori consumi. E’ anche possibile utilizzare meno cache L1 per il codice, a parità di prestazioni –> meno transistor –> minori consumi;
- minor numero di istruzioni eseguite –> migliori prestazioni & minori consumi;
- utilizzo di valori immediati al posto di referenziare la memoria –> istruzioni più corte & migliori prestazioni & minori consumi.
In sintesi: servono molti meno transistor per implementare un processore con ISA NEx64T, con conseguenti risparmi su diversi aspetti (inclusa una maggior facilità di progettazione & test / debug), inclusi consumi e migliori prestazioni, che rendono questa nuova architettura molto più competitiva di x86 e x64 nei vari mercati, potendo anche attaccarne altri (embedded, server a basso consumo, real-time, mobile, IoT) sui quali queste ultime hanno avuto poco impatto finora.
Per contro x86 e x64 possono contare su una vastissima libreria software oltre che a un enorme supporto, i quali al momento non hanno uguali. NEx64T non è compatibile a livello binario con queste due architetture, per cui è ovviamente penalizzata da questo punto di vista.
Inoltre non ha supporto alcuno al momento, per cui tutti gli strumenti (assemblatori, linker, compilatori, debugger) devono essere realizzati. Essendo, però, totalmente compatibile a livello di codice assembly, portarli da x86 / x64 non richiede un grande sforzo da parte di esperti che lavorano con questi strumenti e architetture.
C’è, poi, da dire che la compatibilità binaria con x86 / x64 è divenuta sempre meno importante negli ultimi anni, grazie a strumenti e applicazioni che sono stati realizzati o portati per ISA diverse da queste, per cui quelle due vecchie architetture stanno progressivamente perdendo questo “valore aggiunto” che ha “tenuto a bada” la concorrenza per tantissimo tempo.
Confronto con ARM
Una di queste è un’altra famosa architettura, ARM, che in realtà raggruppa un certo numero di ISA fra loro anche abbastanza diverse, ma accomunate dall’aver avuto un’origine comune nella prima architettura di questa famiglia, il cui “ceppo” viene ormai comunemente chiamato anche ARM32.
ARM ha fatto la sua fortuna nei mercati embedded e, specialmente, mobile, mietendo successi su successi e arrivando a monopolizzare quest’ultimo, dove rappresenta l’unica soluzione adottata da qualunque dispositivo.
I punti di forza grazie ai quali si è fortificata sono stati rappresentati dall’esiguo numero di transistor impiegati per l’implementazione dei core ARM32, a cui hanno fatto seguito l’introduzione dell’estensione Thumb prima (con la quale ha praticamente dominato nell’ambito della densità di codice) e di Thumb-2 poi (che, oltre a migliore leggermente la densità di codice, ha contribuito a incrementare le prestazioni).
In particolare Thumb-2 è divenuta un’architettura a sé stante, essendo completamente indipendente da ARM32 (al contrario di Thumb, che è soltanto un’estensione di ARM32 e non è in grado di rimpiazzarla completamente), tanto che esistono anche dei microcontrollori che implementano soltanto quest’ISA.
Sulla scorta dell’enorme consenso nonché diffusione ARM ha, con calma, lavorato all’evoluzione a 64 bit delle sue famiglie, presentando AArch64, la quale rappresenta anche un taglio con ARM32, in quanto l’ISA è stata completamente ripensata eliminando un bel po’ di legacy che s’era accumulato nel tempo, semplificando l’architettura, che risulta adesso votata alle prestazioni (la densità di codice non è buona, anche se si difende abbastanza bene considerato che ha soltanto istruzioni a lunghezza fissa).
ARM possiede, quindi, un portfolio variegato che le consente di coprire diverse fasce di mercato, ma lo fa portandosi dietro e offrendo quattro architetture diverse (quindi con binari incompatibili fra di loro), sebbene negli ultimi anni il suo unico focus sia rappresentato da AArch64, lasciando a Thumb-2 il mercato embedded & 32-bit.
Il problema di AArch64 è, però, che non offre una buona densità di codice, come già detto, perché quest’architettura è sostanzialmente votata alle pure prestazioni. Inoltre non esiste nessuna versione a 64 bit di Thumb-2 che potrebbe risolvere questo problema e che comunque non sarebbe possibile realizzare, non avendo la tabella degli opcode abbastanza spazio per inserire tutte le istruzioni “compatte” (a 16 bit) necessarie.
L’unica possibile soluzione, semmai ARM dovesse decidersi a muoversi in questa direzione, sarebbe ripetere esattamente quanto realizzato con Thumb e, quindi, introdurre una nuova ISA e una nuova modalità di esecuzione a cui passare introducendo delle speciali istruzioni di salto in AArch64.
Verrebbe, però, fuori la stessa cosa che con ARM32: un accrocco che limiterebbe le prestazioni (considerati i salti alla / dalla nuova modalità ogni volta che risultasse necessario) e non potrebbe in ogni caso ottenere densità di codice comparabile nemmeno a quella di Thumb, in quanto AArch64 ha ben 32 registri a disposizione anziché i 16 di ARM32, per cui non ci sarebbe abbastanza spazio negli opcode per effettuare le stesse, identiche, operazioni, limitando di conseguenza il numero di istruzioni implementabili.
Da questo punto di vista NEx64T è messa molto meglio, poiché ha una sola ISA (qualunque sia la sua “declinazione”: modalità di esecuzione e/o varianti), coi risultati preliminari che mostrano già adesso un’ottima densità di codice nei confronti di x86 ed eccellente rispetto a x64, pur eseguendo meno istruzioni. Per cui certamente aspira a fare meglio di ARM, una volta che compilatori, librerie, e strumenti vari la supporteranno.
Confronto con RISC-V
Anche RISC-V (una delle ultime / più nuove architetture) ha una sola ISA (ci sono poche differenze nelle istruzioni a seconda della “modalità” d’esecuzione), la quale è stata appositamente progettata, fin dall’inizio, tenendo conto della densità di codice e riservando ben il 75% dell’intero spazio degli opcode soltanto per le istruzioni “compatte” (a 16 bit).
La cosa potrà sembrare esilarante, ma questo è anche il suo più grosso difetto. La sua densità di codice, infatti, è buona, ma non la migliore in giro e nemmeno si avvicina al meglio in circolazione, come viene mestamente evidenziato nella seguente presentazione tenutasi alla conferenza RISC-V del 2021:
di cui riporto la parte rilevante:
When trying to compare the normal RISC-V code size density and code size performance against other commercial ISAs, we found that it’s considerably worse like 20-25% even with a compressed extension that it provides which is for the 16 bit, which is, so there is a compressed extension that provides a set of 16 bit instructions that should help with the code size but even with that the application code size are often much larger than ARM like that than alternative commercial processors like ARM.
Senza andare troppo nei dettagli, sono stati fatti degli errori (direi madornali) nella selezione delle istruzioni che fanno parte dell’estensione C (per gli opcode “compressi”, a 16 bit), le cui specifiche sono state di conseguenza “congelate” una volta che questa è stata ratificata e non passibili di ulteriori modifiche.
Questo, unito al fatto che le scelte “filosofiche” (come, ad esempio, l’imposizione di massimo due registri da leggere per istruzione. La quale ha castrato pesantemente quelle di load/store) che sono state fatte per quest’architettura riguardo gli opcode normali (quelli fissi, a 32 bit) e “di base” la rendono troppo semplice (circa 40 istruzioni per il “core” dell’ISA), hanno decretato la situazione in cui versa (non soltanto per la densità di codice, ma anche per le prestazioni: sono necessarie più istruzioni da eseguire per determinati compiti).
Per risolvere parzialmente il problema sono state presentate (e già ratificate) delle nuove estensioni, chiamate Zc (e a seguire un’altra lettera, che identifica il preciso sottoinsieme), le quali sono oggetto della presentazione di cui è stato condiviso il video qui sopra.
I risultati sembrano molto promettenti, sebbene il livello di complessità di alcune estensioni / istruzioni introdotte faccia letteralmente impallidire i più complicati processori CISC, come si può vedere, ad esempio, in questa parte del video:
Difatti, e come si legge chiaramente dal documento delle specifiche di Zce, tali estensioni sono state introdotte specificamente per il mercato embedded (che al momento rappresenta il principale riferimento per RISC-V, la quale risultava parecchio penalizzata rispetto all’aggueritissima concorrenza):
The Zce extension is intended to be used for microcontrollers, and includes all relevant Zc
extensions.
E non poteva essere altrimenti: alcune di quelle istruzioni sono così complicate da essere totalmente incompatibili con la summenzionata filosofia del progetto. Dunque è molto difficile che possano essere utilizzate in ambiti diversi da quello embedded, lasciando il resto dell’architettura nello stesso stato che è stato stigmatizzato all’inizio della presentazione.
D’altra parte c’era l’assoluta nonché urgente necessità di mettere una pezza alla situazione attuale (cosa che è stato fatto con Zce per il mercato embedded, per l’appunto), com’è anche chiaramente rimarcato in un documento di uno dei principali architetti (Krste Asanovic) di questa nuova architettura (qui il PDF con le slide), da cui estrapolo alcune parti rilevanti:
- Contemporary instruction sets overflow 32 bits, and fixed 64b instructions
make code-size uncompetitive
- Add complex 32b instructions to mitigate 30-40% code size increase
- encoding new instructions that need substantially greater than 30-32b to encode (e.g., 32b immediates, longer calls, more source/destination register specifiers)
C.MOPSwhich reduce code size cost of new security features (checks add code at exit/entry to every function+ indirect branch targets)- 48b instructions that substantially improve code size (e.g., Just replacing 64b AUIPC-based sequences in Linux kernel with 48b instructions would save 3.6% code size over and above linker relaxation)
- Without new complex instructions, code-size penalty will hurt RISC-V adoption
Penso che la situazione sia piuttosto chiara, com’è rimarcato dall’ultima frase che dimostra inequivocabilmente come migliorare la densità di codice sia uno dei principali fattori per un’architettura che voglia essere competitiva e che, in particolare, tutto ciò passi necessariamente dall’adozione di istruzioni complesse.
Roba da far ribaltare nella tomba John Cocke, insomma, ma tant’è: c’è gente che è tuttora convinta che esistano ancora i processori RISC, quando delle fondamenta su cui erano basati non è rimasto altro che il vincolo delle sole istruzioni load/store per accedere alla memoria (quindi sono architetture L/S e non RISC!).
Rispetto a quanto già detto per ARM, possiamo dire che NEx64T riesce a risolvere già adesso tutte le problematiche che hanno afflitto o affliggono RISC-V: istruzioni più complesse, più efficienti dal punto di vista della densità di codice, valori immediati (fino a 64 bit!), chiamate “lunghe” a sottoprogrammi, più registri selezionabili (in particolare le maschere per i vettori), e molto altro ancora sono già a disposizioni e utilizzabili senza doversi sbattere la testa a pensare quali nuove estensioni introdurre per mitigare o risolvere le rogne che attanagliano quest’ultima. Il tutto impacchettato in una struttura degli opcode e delle istruzioni coerente e ben definita, che non necessita di aggiungere opcode a caso per soddisfare le suddette esigenze.
Confronto con MIPS, PowerPC/POWER, SPARC
Esistono anche altre architetture abbastanza famose che negli ultimi anni si sono riproposte per cercare di competere con x86/x64, ARM, e specialmente RISC-V (perché rischiano di essere fatte fuori dalla nuova arrivata): MIPS, PowerPC / POWER e SPARC non hanno certo bisogno di presentazioni, avendo contribuito anche loro alla storia dell’informatica degli ultimi decenni.
La principale carta che hanno usato per rilanciarsi consiste nell’apertura delle loro tecnologie, intendendo con ciò l’eliminazione degli oboli (licenze d’uso) da pagare ai detentori delle loro proprietà intellettuali, il quale non casualmente rappresenta il maggior vantaggio di RISC-V che ha contribuito alla sua recente diffusione.
Il problema, però, è che le aziende a cui fanno capo si sono mosse molto tardi (anche per questo sono state fagocitate da Intel e AMD prima, e successivamente anche da ARM) per rendere appetibili le loro architetture e far loro guadagnare quote di mercato.
Ma un altro grosso problema che le affliggono è che non propongono un ecosistema omogeneo in in grado di soddisfare le esigenze di qualunque settore in cui competere (dall’embedded all’HPC): rimangono basate sostanzialmente sulle loro vecchissime ISA, a cui sono stata aggiunte diverse istruzioni nel corso degli anni, ovviamente, incluse estensioni per cercare di mitigare i grossi problemi di scarsa densità di codice che le hanno caratterizzate fin dalla loro introduzione.
Rappresentano, insomma, una collezione di pezzi eterogenei da mettere assieme alla bisogna, a seconda di quello che serva. RISC-V nasce già in partenza con una sola ISA (più le innumerevoli estensioni, ma la struttura base è e rimane sempre al stessa: al più si aggiungono nuove istruzioni), e lo stesso fa NEx64T. Dunque sfugge quale potrebbe essere il valore aggiunto di queste vecchie architetture, a parte il supporto e la libreria di software già esistente, visto che non eccellono né nella densità di codice né nelle prestazioni.
I vantaggi dell’essere un “Super CISC”!
Passando a parlare adesso dei vantaggi intrinseci di NEx64T, al giorno d’oggi potrà sembrare anacronistico se non un’autentica bestemmia (a causa della martellante propaganda che ha polarizzato il consenso generale sui presunti RISC, che in realtà sono ISA L/S, come già ampiamente spiegato in una recente serie di articoli), ma c’è da dire che rispetto alla concorrenza ha il vantaggio di essere… un CISC! Anzi, un “Super CISC”, considerato che anche x86 e x64 sono CISC, ma questa nuova architettura va ben oltre.
Infatti quest’ISA consente di referenziare non uno, ma fino a due operandi in memoria con tutte le istruzioni “normali” (non quelle “compatte”, per essere chiari), oltre a fornire appositamente una versione compatta dell’istruzione MOV che adesso è in grado di copiare un dato direttamente da una locazione di memoria a un’altra (anche x86 e x64 sono in grado di farlo con l’istruzione MOVS, che però è molto più limitata).
Questa scelta ha portato notevoli benefici (come già illustrato con dovizia di particolari in un precedente articolo), che si sintetizzano nei seguenti punti principali:
- minor utilizzo di registri per memorizzare dati che servono soltanto una volta (temporaneamente);
- eliminazione delle dipendenze & penalizzazioni dovute al load-to-use nella pipeline (quando bisogna aspettare che un dato sia disponibile per poterlo finalmente utilizzare);
- minor numero di istruzioni eseguite (e, in genere, miglior densità di codice grazie a questo).
Il primo punto può sembrare banale e non così importante, ma ha un peso non indifferente in ambiti in cui ci siano pochi registri a disposizione, perché si vuole ridurre l’area (silicio) / transistor utilizzati e, di conseguenza, riducendo anche i consumi.
Ma tale scelta ha positive ricadute in qualunque ambito (quindi non soltanto quello embedded), perché sporcare più registri spesso significa anche doverne conservare il contenuto originale all’inizio dei sottoprogrammi che li usano, per poi ripristinarlo alla fine (prima di restituire il controllo al chiamante). Dunque, e senza andare troppo nel dettaglio parlando di specifiche architetture, serve eseguire più istruzioni, impattando (negativamente) sulle prestazioni e sulla densità di codice.
Per il secondo punto può essere più difficile valutarne l’impatto, perché sembra più che altro una questione squisitamente tecnica (lo è, in effetti). In realtà si tratta di casi molto comuni, perché capita spessissimo che serva leggere un dato dalla memoria, per poi elaborarlo.
Il problema è che utilizzare un’istruzione soltanto per leggerlo, e successivamente un’altra per processarlo, causa una dipendenza nella pipeline (e, di conseguenza, una penalizzazione di un certo numero di cicli di clock): il processore è costretto ad aspettare che il dato sia stato letto e finalmente disponibile nel registro, per poterlo utilizzare e, quindi, finalizzarne l’operazione.
Questa penalizzazione non esiste in un processore CISC che consenta di referenziare direttamente un dato in memoria senza, quindi, passare per un registro, perché non appena il dato risulta disponibile (quindi appena l’unità AGU ha finito il suo lavoro), l’unità d’esecuzione può processarlo immediatamente.
Anche i processori L/S possono sfruttare degli stratagemmi che portano a risultati simili. Ad esempio il processore U74-MC di SiFive è basato sull’architettura RISC-V e consente di eliminare la penalizzazione del load-to-use nella maggior parte dei casi, come si può vedere dal seguente diagramma tratto dal suo manuale:
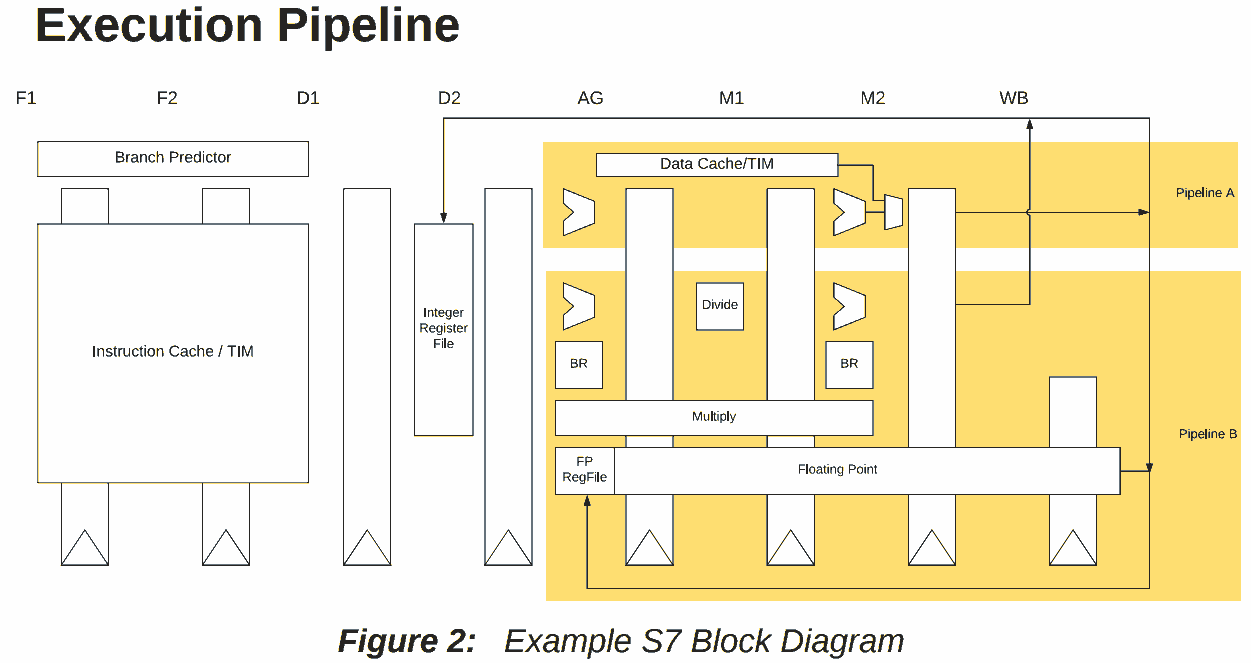
e dalla seguente descrizione:
The S7 execution unit is a dual-issue, in-order pipeline. The pipeline comprises eight stages:
two stages of instruction fetch (F1 and F2), two stages of instruction decode (D1 and D2),
address generation (AG), two stages of data memory access (M1 and M2), and register writeback (WB). The pipeline has a peak execution rate of two instructions per clock cycle, and is
fully bypassed so that most instructions have a one-cycle result latency:
- Loads produce their result in the M2 stage. There is no load-use delay for most integer
instructions. However, effective addresses for memory accesses are always computed in the AG stage. Hence, loads, stores, and indirect jumps require their address operands to be
ready when the instruction enters AG. If an address-generation operation depends upon a
load from memory, then the load-use delay is two cycles.
Questo non avviene però, senza costi. Infatti la microarchitettura ha bisogno di apposita logica che effettui dei controlli sulle due istruzioni eseguite, per vedere se uno o entrambi gli operandi della seconda istruzione utilizzino il registro che è interessato dalla prima istruzione (che alla fine conterrà il valore letto dalla memoria).
Tutto ciò non è necessario in un processore CISC, perché il dato letto viene immediatamente utilizzato, come già spiegato: non serve nessuna logica addizionale, in quanto risulta “già implementato” (è intrinseco nel funzionamento del processore). Quindi “a costo zero”.
Infine, per il terzo punto, ci sono anche casi in cui il numero di registri a disposizione non sia sufficiente per l’implementazione di un particolare algoritmo, per cui il processore sarà costretto a utilizzare lo stack, ad esempio, come “area temporanea” in cui conservare i dati di alcuni registri, per poi ripristinarli a lavoro finito, passandosi il tempo a fare avanti e indietro coi dati su e dallo stack.
Poter referenziare ben due operandi in memoria aiuta molto in questi casi, eliminando parecchie istruzioni da eseguire. Ma ciò non succede, comunque, soltanto in questi scenari, poiché si può verificare anche quando ci sono abbastanza registri a disposizione, ma si possono comunque referenziare direttamente operandi in memoria, risparmiando istruzioni da eseguire.
Il che significa che processori CISC come e, specialmente, NEx64T possono richiedere pipeline meno “larghe” (con meno istruzioni decodificate ed eseguite per ciclo di clock) rispetto ad altri (in particolare quelli L/S), come dimostra anche uno studio che è stato pubblicato un po’ di anni fa, il quale ha messo a confronto diverse architetture e microarchitetture dell’epoca:

Come si può vedere, un vecchio Atom (x86/x64) che ha una pipeline in-order a due vie oblitera l’A8 (ARM, sempre in-order a due vie), disintegra anche l’A9 (ARM, out-of-order a due vie) e riesce a essere competitivo persino con l’A15 (ARM, out-of-order a tre vie)!
Le ragioni sono riportate nelle conclusioni del pezzo, da cui estrapolo la parte rilevante (relativamente a un benchmark che è stato investigato. Ma situazioni simili sono comuni con le ISA L/S):
The Cortex processors execute dramatically more instructions for the same results.
Il che non lascia sorpresi. Anzi, è pure abbastanza ovvio, una volta considerato che per incrementare una locazione di memoria, ad esempio, un’architettura L/S deve eseguire ben tre istruzioni (caricare il valore in un registro, incrementare il registro, e infine scriverne il contenuto), mentre un CISC come l’Atom riesce fare lo stesso con una sola istruzione…
Avere la possibilità di poter eseguire meno istruzioni rispetto ad altre architetture è un fattore molto importante che non andrebbe sottovalutato, poiché comporta cambiamenti significativi a livello microarchitettura: un conto è decodificare ed eseguire 2 istruzioni per cicli di clock in una pipeline in-order, e tutt’altra cosa è farlo con una out-or-order (e peggio ancora aumentando il numero di istruzioni per ciclo di clock).
Ne si può prendere atto leggendo il suddetto documento dell’architetto di RISC-V, che riporta delle informazioni a riguardo (anche se a volte non immediatamente visibili):
- Control-flow changes on integer workloads already at point where wider front end will have to predict multiple PCs to be effective.
- move to larger BTB structures that are decoupled from instruction fetch (and hence encoding) makes finding instruction start boundaries less critical.
- Cracking high-frequency instructions in a superscalar requires complex decode->dispatch buffer management and increases per-instruction tracking costs.
- Variable amount of cracking in highly superscalar decode adds mux complexity in downstream uop queue datapath that can add to branch resolution latency.
Per semplificare, più istruzioni si devono decodificare ed eseguire in una pipeline superscalare, e ovviamente più risorse sono necessarie per un processore (più decoder nel frontend, e più informazioni per tenere traccia dell’esecuzione delle istruzioni nel backend).
Risulta evidente, da quanto finora esposto, come NEx64T si ponga in una situazione privilegiata rispetto a qualunque altra architettura finora analizzata, in quanto riesce a eseguire molto più “lavoro utile” con le sue istruzioni, riducendo significativamente il numero di quelle che devono essere eseguite per portare a determinate un determinato compito.
Il che significa che può ottenere prestazioni superiori o comparabili rispetto a microarchitetture che implementano altre ISA, ma avendo bisogno di meno risorse complessivamente. Meno istruzioni da decodificare ed eseguire per ciclo di clock, ad esempio. Oppure meno cache L1 per il codice, grazie all’ottima densità di codice. Tanto per fare alcuni esempi concreti.
Dall’HPC all’embedded “low-cost”
Similmente ad ARM e RISC-V, la flessibilità di questa nuova architettura le consente di poter essere impiegata nei settori più disparati, spaziando dalle prestazioni elevate & massicce (HPC) grazie alla nuova unità SIMD/Vettoriale (di cui abbiamo parlato ampiamente nel precedente articolo), fino all’embedded.
Da quest’ultimo punto di vista NEX64T riesce a spingersi anche oltre quanto offerto da ARM e RISC-V (che sono i punti di riferimento in questo mercato) potendo contare anche su una modalità d’esecuzione a 16 bit (assente nelle altre due) che, come suggerisce, utilizza registri (general-purpose) di questa dimensione, risparmiando quindi sui costi d’implementazione quando 16-bit sono sufficienti per manipolare i dati come pure i 64kB massimo di memoria indirizzabile, mettendosi quindi in concorrenza con altre architetture “very low-cost” che operano in questi segmenti.
Ciò che rende più interessante NEx64T rispetto ad altre ISA a 16-bit è che permette, eventualmente, di accedere a locazioni di memoria che si trovano oltre i 64kB normalmente indirizzabili (fino ad alcuni MB), grazie ad alcune particolari modalità di indirizzamento molto compatte che non richiedono offset o puntatori più lunghi dei 16-bit che sono normalmente utilizzabili.
Questa funzionalità (se abilitata) consente di spostare un po’ di dati (ma non tutti: è soltanto possibile leggere o scrivere direttamente in queste locazioni di memoria “alta”, ma non referenziarle tramite puntatori) fuori dai 64kB “standard”, in modo da risparmiare questa preziosa memoria per codice, stack e altri dati (che non possono stare in altri posti).
Un’altra opzione offerta, forse anche più interessante della precedente, è quella di poter eseguire codice oltre i 64kB (fino ad alcuni MB), essendo il solo PC (Program Counter) disponibile a 32 bit (tutti gli altri registri rimangono a 16 bit). Questo perché molto spesso si ha a che fare con molto più codice anziché dati, per cui questa soluzione calza a pennello.
Ovviamente soltanto le istruzioni di salto a sottoprogramma sono interessate da questo cambiamento, perché devono memorizzare o utilizzare l’indirizzo di ritorno usando 32 bit anziché 16. Quindi non è possibile calcolare indirizzi a cui saltare (tramite registri), ma la precedente funzionalità si presta, invece, molto bene a implementare VMT o, in generale, tabelle di puntatori a funzione quando si usa anche quest’opzione.
La differenza, rispetto a tante altre architetture a 16 bit, è che la gestione rimane semplice e “omogenea”, non richiedendo l’introduzione di registri di bank oppure segmenti: l’architettura rimane perfettamente coerente, come pure tutti gli offset e valori immediati rimangono sempre a 16 bit (massimo).
Sempre per cercare di ridurre al minimo i costi implementativi, in ambito embedded si possono usare meno registri. 32 registri general-purpose sono ottimi per i settori desktop / server / HPC, ma 16 vanno benissimo quando si parla di embedded. In settori in cui i vincoli fossero ancora più stretti si potrebbe pensare di utilizzare soltanto 8 registri (come x86, in sostanza), potendo in ogni caso contare sulla possibilità di poter indirizzare ben due locazioni di memoria nelle istruzioni, che consente di mitigarne notevolmente la penuria.
Infine, ed era già stato accennato nell’articolo sulle modalità d’indirizzamento, proprio per l’ambito embedded (oltre che di sistema) è possibile impiegare una speciale modalità che risulta particolarmente utile quando si lavora in questo campo (come pure in situazioni particolari), che potrebbe fare la differenza. Di questo, però, continuo a evitare di riportare ulteriori informazioni per ragioni che sono intuibili.
Conclusioni
Non è stato possibile entrare molto nei dettagli perché l’articolo è già abbastanza lungo di suo, ma penso sia abbastanza chiaro in che modo NEx64T si ponga nei confronti della concorrenza e perché, pur essendo una “nuova arrivata”, avrebbe parecchio da dire nonché offrire.
Introdurre una nuova architettura non è affatto facile e richiede costi non indifferenti, ma se esistono vantaggi tali da giustificare i sacrifici potrebbe essere una strada che valga la pena percorrere.
Il prossimo articolo chiuderà la serie facendo il punto della situazione e mettendo sul piatto alcune considerazioni finali sulle quali riflettere.







