
Tolta di mezzo la patata bollente dell’eredità di x86/x64, passiamo adesso a esaminare la nuova unità SIMD/vettoriale integrata in NEx64T, che ovviamente è basata su quelle sviluppate per tali architetture (sempre a causa del vincolo della totale compatibilità a livello di sorgente assembly), ma con una completa rivisitazione / riprogettazione e diversi miglioramenti / estensioni.
Potrà sembrare una cosa da poco, ma penso che il principale beneficio sia stato quello di aver raggruppato le centinaia e centinaia di istruzioni in poche e semplici strutture / formati di opcode che in x86/x64 risultano, invece, disperse in qualche migliaio di opcode in maniera pseudo-casuale.
Il vantaggio è quello di consentire una decodifica a dir poco banale, pesando pochissimo sia sul frontend sia sul backend dei core. Tralasciando per il momento le istruzioni memory-to-memory, basti pensare che sono sufficienti appena i primi due bit di un’istruzione per identificare la quasi totalità di quelle SIMD/vettoriali binarie (due argomenti sorgente), unarie (un argomento sorgente) e nullarie (nessun argomento sorgente), mentre con sei bit si coprono quelle ternarie (tre argomenti sorgente), e con cinque le versioni binarie “compatte” (per i casi più comuni).
Un’ISA ortogonale
Ciò ha permesso di ottenere un insieme di istruzioni quasi completamente ortogonali, essendo in grado di operare indifferentemente con:
- MMX (registri dell’FPU), SSE, AVX, AVX-512/1024 per quanto riguarda registri di dimensione fissa;
- vettori e aree di memoria (“blocchi”) con numero di elementi non nota a priori;
- dati scalari (non per MMX) o “packed“;
- tipi di dato interi da 8/16/32/64 bit o in virgola mobile da 16/32/64/128 bit (quest’ultimo non per MMX);
- maschere per selezionare le linee di dati su cui lavorare (non servono per i “blocchi di memoria”. Più dettagli avanti);
- possibilità di azzerare i dati delle “linee” che non vengono interessate dall’operazione oppure copiarli dalla sorgente;
- copia (“broadcast” / “splat“, in gergo) dei dati letti in memoria su tutti gli elementi;
- controllo dell’arrotondamento se si opera soltanto con dei registri (e non con operandi in memoria). Non per MMX ed SSE;
- controllo delle eccezioni sempre se si opera soltanto coi registri. Non per MMX ed SSE;
- la seconda sorgente (che in genere referenzia la memoria) che può avere una dimensione diversa dalle altri sorgenti e dalla destinazione. In questo caso i dati letti vengono convertiti / estesi al dimensione della destinazione (es: vengono letti 8 dati FP16 dalla seconda sorgente, che vengono convertiti a FP64 per poi essere sommati con l’altra sorgente che è a FP64);
- la possibilità di utilizzare direttamente valori immediati di diversa dimensione anziché referenziare una locazione di memoria, risparmiando gli accessi a quest’ultima ed eventualmente ottenendo istruzioni più corte. Il dato viene automaticamente replicato in tutte le “linee” per le istruzioni (packed o vettoriali) che operano su più elementi.
In soldoni e a parte alcune eccezioni che riguardano soltanto le vecchie estensioni SIMD MMX e/o SSE, questo significa che ogni istruzione funziona in uno qualunque dei suddetti contesti / modalità (anche combinati). Prendiamo, ad esempio:
MMADD231.H V1{K1}{Z}, V0, [RSI + RAX + 0X12345678]{1to*}
La prima lettera, M, specifica che deve operare sui registri MMX (a 64 bit. Sono mappati su quelli dell’FPU x87). MADD231 è l’istruzione vera e propria, la quale moltiplica i dati del secondo e terzo operando (quindi V0 e [RSI + RAX + 0X12345678]), sommando poi i risultati a quelli di V1, ma soggetti alla maschera K1.
Questo significa che verranno conservati i dati delle sole linee abilitate (bit impostati a 1 in K1), mentre gli altri (bit a 0 in K1) saranno azzerati ({Z}). Poiché i registri MMX sono a 64 bit e il tipo di dato (.H) è FP16 (virgola mobile a 16 bit), ciò significa che ci saranno 4 dati da elaborare alla volta e, quindi, 4 linee.
E’ interessante notare che non vengono letti quattro dati dal terzo operando (quello in memoria), ma soltanto uno. Infatti l’unico dato FP16 prelevato da [RSI + RAX + 0X12345678] verrà copiato quattro volte ({1to*}) per formare il blocco “packed” da 64 bit. Questa funzionalità di broadcasting/splat è stata mutuata da AVX-512, ma adesso è disponibile per tutte le istruzioni.
Si tratta di un’istruzione che, come si può vedere, compie parecchio “lavoro utile”, ma soprattutto fa uso dei registri della decrepita unità FPU x87 che sono sfruttati, in questo caso, per elaborazione contemporanea di 4 dati FP16: cosa impossibile per la vecchia unità MMX, ma naturale per quella NEx64T, grazie alla quasi completa ortogonalità che la caratterizza. Da notare che l’istruzione fa uso anche di un registro maschera (K1), il quale su x86/x64 è stato introdotto e funziona solamente con le AVX-512.
Per completezza riporto l’elenco e il significato della prima lettera di tutte le istruzioni SIMD/vettoriali:
- M -> MMX, packed. Registri a 64 bit dell’FPU;
- P -> SSE, packed. Registri a 128 bit dell’unità SIMD;
- R -> SSE, scalar. Registri dell’unità SIMD;
- S -> AVX/AVX512-1024/Vector, scalar. Registri dell’unità SIMD;
- X -> AVX/AVX512-1024, packed. Registri a 128 bit dell’unità SIMD;
- Y -> AVX/AVX512-1024, packed. Registri a 256 bit dell’unità SIMD;
- Z -> AVX/AVX512-1024, packed. Registri a 512 bit dell’unità SIMD;
- W -> AVX/AVX512-1024, packed. Registri a 1024 bit dell’unità SIMD;
- V -> Vector/Block. Registri dell’unità SIMD (di dimensione dipendente dall’implementazione) oppure area/blocco di memoria (non usa registri, ma direttamente la memoria. Un esempio più avanti).
Quindi, e per fare un altro esempio, questa:
VMADD231.H V1{K1}{Z}, V0, [RSI + RAX + 0X12345678]{1to*}
sarà la versione vettoriale della precedente istruzione. L’istruzione è esattamente la stessa, con la medesima codifica, eccezion fatta per un campo che specifica quale delle modalità elencate debba essere utilizzata.
Arriva il nuovo: i vettori!
Proprio la versione vettoriale rappresenta la più grossa novità rispetto a x86/x64, che rimangono legate al classico paradigma SIMD e, quindi, possono gestire le operazioni su dati la cui dimensione è fissa / predeterminata (con un massimo rappresentato dalla dimensione dei registri SIMD).
Ciò significa che il numero di elementi processabili contemporaneamente è dettato in primis da quante unità di calcolo possono lavorare sui dati disponibili nei registri coinvolti nell’operazione, e secondariamente da quante di queste istruzioni possono essere eseguite allo stesso tempo nella pipeline del processore.
Massimizzare le prestazioni in un’architettura SIMD richiede, pertanto, la scrittura di sottoprogrammi ad hoc per la specifica microarchitettura. Quindi potenzialmente saranno necessarie tante versioni dello stesso sottoprogramma quanti sono le (molto) diverse microarchitetture.
Viceversa, in un’architettura vettoriale non si sa a priori su quanti elementi è possibile lavorare contemporaneamente in un registro vettoriale, ma quest’informazione è disponibile durante l’esecuzione, ed è sufficiente una sola copia del sottoprogramma (lasciatemi semplificare il discorso per non appesantirlo troppo) per eseguire il determinato compito.
Un esempio: daxpy – AVX-512
Un esempio sarà utile per comprendere meglio le differenze fra i due paradigmi, facendo ricorso alla famosa routine daxpy presente nella libreria BLAS (lo standard di fatto per alcuni tipi di calcoli algebrici, che spaziano dai vettori alle matrici. Usatissimi in parecchi ambiti, specialmente scientifico e calcoli massicci), cominciando con l’implementazione per AVX-512:

Il “cuore” (loop) del codice assembly è abbastanza semplice e riflette, a sua volta, la semplicità della funzione di cui è stata riportata una versione in C: appena 6 istruzioni sono sufficienti per macinare 8 iterazioni del ciclo for alla volta (AVX-512 ha registri SIMD da 512 bit che, quindi, possono contenere 8 valori in virgola mobile a doppia precisione AKA FP64).
La complicazione si trova altrove, cioè nel codice che si occupa di inizializzare un po’ di roba e fare alcuni controlli prima di entrare nel ciclo principale (marcato dall’etichetta .loop). Per semplificare, il concetto è che AVX-512 viene fatto lavorare a pieno regime, processando 8 dati FP64 alla volta, finché è possibile.
Soltanto alla fine, quando i vettori possono contenere meno di 8 elementi (o nessuno), bisogna effettuare dei controlli ed eseguire, eventualmente, di nuovo il ciclo per un’ultima volta, ma selezionando soltanto gli elementi rimasti (impostando opportunamente la maschera K1, i cui bit a 1 indicano quali di essi sono coinvolti nell’elaborazione).
Difatti è il codice di inizializzazione e quello di “chiusura” (per la “coda” AKA tail dei vettori) che richiede il maggior numero di istruzioni allo scopo (ben 14 solo per questo!): di gran lunga superiore a quello del ciclo principale (soltanto 6, come già detto).
Alla fine non è nemmeno tanto male, perché la parte più importante è rappresentata dal ciclo principale, per l’appunto, che si occupa di macinare tanti numeri, e oggettivamente farlo in soltanto sei istruzioni è un risultato di tutto rispetto.
Il problema è che quest’implementazione va bene e sfrutta al meglio (fatta eccezione per la “coda”, per l’appunto) le risorse a disposizione dell’unità SIMD nel solo caso in cui la specifica architettura è in grado di elaborare al massimo 8 dati FP64 alla volta durante l’esecuzione dell’intero ciclo principale (assumendo, a livello puramente ipotetico, che tutte le istruzioni del ciclo possano essere eseguite “allo stesso tempo”, in un solo ciclo di clock).
Ovviamente la realtà è ben diversa, e riuscire a poter processare 8 dati per ciclo di clock richiede codice molto più complesso di quello precedente, facendo anche uso di più registri in cui (pre)caricare più dati, e intervallando opportunatamente le istruzioni in modo da eliminare o ridurre al minimo le dipendenze.
Un lavoro non di poco conto, che però e molto probabilmente va ripetuto a seconda della specifica microarchitettura, considerato che ognuna può avere requisiti / vincoli diversi da un’altra, pur potendo processare in linea teorica sempre 8 dati per ciclo di clock.
Adesso immaginate di avere a che fare con microarchitetture che consentono di calcolare non 8, ma 16 (quindi due istruzioni) dati alla volta per ciclo di clock, e potete cominciare a pensare quali contorsionismi siano necessari per cercare di sfruttare al meglio questa notevole capacità di calcolo.
Pensate, infine, ad architetture che possano eseguire anche tre o addirittura quattro di quelle istruzioni, e avete già chiaramente in testa come questo procedimento non sia assolutamente scalabile: non funzionava già così bene con una sola istruzione, ma peggiora enormemente con unità SIMD più potenti!
Ecco perché negli ultimi anni si sono (ri)affacciate prepotentemente delle architetture che propongono, invece, un ritorno al passato, ossia le unità vettoriali che erano già state introdotte dal geniale ing. Seymour Cray coi suoi famosissimi super computer.
daxpy – RISC-V
Una di queste, che sta largamente prendendo piede, è RISC-V, un’architettura L/S (Load/Store: ex-RISC) il cui principale vantaggio è quello di essere completamente libera da licenze varie (a parte il marchio, che è stato registrato).
daxpy viene implementata in questo modo (sfruttando l’estensione vettoriale che è stata recentemente ratificata, dopo parecchi anni di attesa):

La semplicità di un’architettura vettoriale salta subito all’occhio, poiché non è presente alcun codice di inizializzazione ma, soprattutto, non c’è da gestire appositamente la “coda” dei vettori (gli ultimi elementi da processare).
Il ciclo principale, però, è composto da ben 10 istruzioni (praticamente sono tutte le istruzioni della funzione, a eccezione di quella di ritorno), mentre abbiamo visto che sono soltanto 6 nel caso della versione AVX-512 (ignorando al momento quelle di inizializzazione e della gestione della “coda”).
Questo significa che AVX-512 potrebbe far meglio nell’ipotesi di avere a che fare con microarchitetture “comparabili” in grado di processare fino a 8 dati FP64 per singola istruzione (il massimo gestibile da un’istruzione di quest’ISA).
Il problema, però, è che il codice dev’essere cambiato anche in maniera sostanziale nel caso la microarchitettura abbia differenze sensibili, com’è già stato illustrato in precedenza, mentre il codice della versione RISC-V non necessita di alcuna modifica a prescindere da come sarà realizzata la particolare microarchitettura sulla quale gira (ad esempio: 16 elementi elaborabili per singola istruzione).
daxpy – ARM/SVE
Considerazioni analoghe valgono per l’unità vettoriale che ARM ha introdotto con la sua architettura a 64 bit (AArch64) tramite l’estensione SVE:

In questo caso vengono utilizzate meno istruzioni per il ciclo principale (7, contro le 10 di RISC-V), grazie al fatto che quest’architettura mette a disposizione delle modalità d’indirizzamento più complesse (che tengono conto della dimensione dei dati a cui accedere).
E’, però, presente una parte di inizializzazione che precede il ciclo, la quale serve a impostare opportunamente una maschera (p0) per gestire correttamente anche il caso della “coda” dei vettori.
Concettualmente, quindi, ARM/SVE è una sorta di “ibrido”, perché funziona come AVX-512 in quanto utilizza delle maschere per filtrare opportunamente gli elementi sui quali lavorare, ma come RISC-V non è nota a priori (a tempo di compilazione) la dimensione dei registri vettoriali.
In ogni caso l’obiettivo è raggiunto: il processore è in grado di operare con un numero arbitrario di elementi (il quale dipende dalla specifica implementazione), ma senza alcuna modifica al codice (che rimane lo stesso, per qualunque microarchitettura).
daxpy – NExT64: implementazione base
Veniamo finalmente alla versione per NEx64T, esponendo soltanto una prima versione basilare, molto simile a quelle finora presentate, in modo da introdurre gradualmente le sue innovazioni e mostrare in che modo sia possibile, via via, fare di meglio:

L’estensione vettoriale di questa nuova architettura è, a sua volta, una specie di ibrido fra ARM/SVE (e AVX-512) e RISC-V. Utilizza, infatti, le maschere per selezionare su quali dati operare, ma tali maschere sono impostate con una sola istruzione che fa riferimento al solo numero totale di elementi presenti nei vettori (in questo caso è simile a RISC-V. ARM/SVE, invece, sfrutta delle specifiche istruzioni per impostare in maniera opportuna la maschera da utilizzare, a seconda di particolari condizioni da soddisfare).
La sintassi utilizzata è simile a quella Intel, in modo da renderla più comprensibile a chi sia avvezzo alla lettura del codice x86/x64 (e AVX-512, in particolare), ma i commenti consentono di rendere ancora più chiaro in che modo lavorino le istruzioni.
Intanto balza subito all’occhio il fatto che il ciclo principale sia costituito da sole 5 istruzioni (contro le 7 si ARM/SVE e le 6 di AVX-512), grazie all’impiego di una sola istruzione (ksetlendjnz) che consente di impostare la nuova maschera da utilizzare in base agli elementi rimanenti da elaborare, aggiornare quanti ne rimarranno (se dovesse esserci ancora un’elaborazione), e infine di saltare all’inizio del ciclo se effettivamente ce ne siano ancora.
Per il resto il codice è molto simile a quello di AVX-512, in quanto il focus è rappresentato dalle tre istruzioni che caricano i dati e li elaborano. Segno, questo, di come la base di partenza fosse già molto buona (le istruzioni fanno molto “lavoro utile”. Come da tradizione CISC!).
Freddi numeri alla mano, si può vedere come NEx64T, seppur in versione “base”, riesca a far meglio di ogni altra versione, qualunque sia la metrica di riferimento: dal numero di istruzioni del ciclo principale (la più importante, in questi casi!) a quello totale, dallo spazio occupato dal ciclo principale a quello totale.
daxpy – NExT64: con postincremento
L’utilizzo di una nuova funzionalità, cioè della modalità con post-incremento per l’indirizzamento della memoria, consente di abbassare ulteriormente questi numeri, portando a soltanto 4 istruzioni quelle del ciclo principale (ma ne beneficia, in ogni caso, l’intera funzione con una generale riduzione del loro numero):

La possibilità di poter far avanzare automaticamente il puntatore dei dati dei vettori agli elementi del successivo gruppo di dati da elaborare consente di ridurre all’osso il ciclo principale, che adesso risulta costituito dalle sole istruzioni di caricamento e processamento di dati, con l’unica istruzione (setlenjnz) che rimane per il controllo & passaggio al successivo blocco da elaborare.
Anche il codice di inizializzazione risulta leggermente snellito, poiché non si fa più uso dell’indice che referenzia il primo elemento da cui partire con l’elaborazione dei dati dei vettori e, quindi, della relativa istruzione (che lo imposta a zero, alla partenza).
Quest’esempio è molto importante perché mostra uno scenario abbastanza realistico nonché comune riguardo l’elaborazione di dati vettoriali, in quanto a farla da padrone sono le istruzioni che si occupano dei calcoli effettivi, con quelle di “controllo” a svolgere un ruolo minimale (lo stretto indispensabile).
daxpy – NExT64: versione “memory-to-memory“
La routine daxpy permette di mostrare come sia possibile sfruttare un’ulteriore funzionalità di NEx64T che consente di ridurre ai minimi termini il ciclo principale (che consta di due sole istruzioni adesso!):

In questo caso, infatti, è presente una sola istruzione che “macina” tutti i dati, prendendosi carico di:
- loro lettura dalla memoria;
- elaborazione;
- scrittura del risultato in memoria.
Ciò è stato possibile poiché uno dei dati (il coefficiente di moltiplicazione) risulta già disponibile in un registro (v0) e, quindi, non serve caricarlo dalla memoria, riducendo a soli due gli argomenti che referenzino direttamente la memoria (il massimo possibile per questa nuova architettura).
In scenari più comuni sarà necessario aggiungere un’altra istruzione per leggere (oppure scrivere) i dati dalla memoria, ma in ogni caso sarà abbastanza facile nonché comune poter sfruttare la possibilità di poter referenziare direttamente la memoria per almeno due degli argomenti delle istruzioni (non soltanto vettoriali: è possibile farlo anche con quelle general-purpose, come già illustrato nei precedenti articoli).
daxpy – NExT64: versione “blocco di memoria”
Sempre daxpy offre la possibilità di introdurre un’altra caratteristica innovativa di NEx64T, che può essere decisamente utile in scenari molto semplici come questo:

Non si tratta di uno scherzo: il codice che esegue tutti i calcoli si è ridotto a un’unica istruzione, con quella successiva che serve soltanto per uscire dalla funzione!
Ciò è stato possibile grazie alla capacità di NEx64T di impiegare qualunque istruzione general-purpose o vettoriale per la cosiddetta modalità “a blocco”, che estende il concetto introdotto da x86/x64 col prefisso REP (il quale, però, poteva esser usato soltanto su poche, molto limitate, istruzioni).
L’idea è quella di generalizzare il concetto di input e output dell’istruzione “da ripetere”, facendo sì che vengano prelevati i dati da una qualunque sorgente (in memoria, facendo ricorso ad alcune modalità d’indirizzamento. Oppure da un registro) per gli operandi in ingresso, a qualunque destinazione (con le stesse modalità).
In questo caso è sufficiente memorizzare i puntatori alle aree di memoria da leggere o scrivere in precisi registri (r6 per la seconda sorgente. r7 per la destinazione) oppure specificare il registro in cui sono conservati i dati “scalari” (v0, in questo caso).
Il processore si farà poi carico di:
- leggere via via tutti i dati;
- passarli all’istruzione “da ripetere”;
- prelevarne il risultato;
- memorizzarlo nella destinazione;
- aggiornare automaticamente tutti i puntatori per passare ai dati (e destinazione) successivi;
- aggiornare il contatore degli elementi finché ne siano rimasti ancora da elaborare.
Dunque NEx64T rilancia e dona nuova linfa a un concetto considerato obsoleto nonché foriero di critiche, ma che consente di implementare in maniera estremamente efficiente scenari, sì, semplici, ma anche abbastanza comuni.
Lo fa, poi, estendendone le capacità, grazie alla possibilità di specificare modalità d’indirizzamento diverse da quelle di x86/x64 (limitate ai soli post-incremento e post-decremento), incluse data-stride e gather/scatter, oltre che l’impiego di registri (come visto in quest’esempio).
Infine e per chiudere su quest’argomento, questa nuova architettura rivitalizza anche un’altra funzionalità introdotta per la prima volta da Intel più di venti anni fa, permettendo di sfruttare il concetto di ripetizione (e non soltanto questo!) in maniera più “originale e creativa”. Di questo, al momento, preferisco non parlare per non scoprire troppe carte.
Operazioni di “riduzione”
Un altro scenario abbastanza comune nell’ambito del calcolo vettoriale è quello cosiddetto della “riduzione” dei dati (in gergo). Si tratta, in parole povere, di applicare un’operazione prendendo tutti gli elementi di un vettore, partendo dai primi due di essi, e riutilizzando il risultato via via con gli elementi successivi (uno alla volta).
L’esempio classico è quello della somma di tutti gli elementi di un vettore (preso dal link fornito qui sopra, ma corretto: il codice presente nella pagina è, infatti, sbagliato!):

L’esempio è, per così dire, fortemente ispirato a quanto offerto dall’architettura RISC-V, ma va benissimo per esporre il concetto in maniera semplice, senza addentrarci in dettagli che allungherebbero ulteriormente il già lungo articolo.
L’idea è quella di introdurre delle specifiche istruzioni per questi casi (vredadd32, nell’esempio), le quali si occupano di processare in parallelo e il più possibile i dati, prelevandoli dalla memoria in base alla capacità / dimensione del registro vettoriale, e ripetendo poi il blocco di operazioni finché non sono stati processati tutti gli elementi.
Uno scenario molto simile a quello già presentato con daxpy, insomma.
Riduzione con NEx64T
Inutile dire che NEx64T permetta di fare di gran lunga meglio:
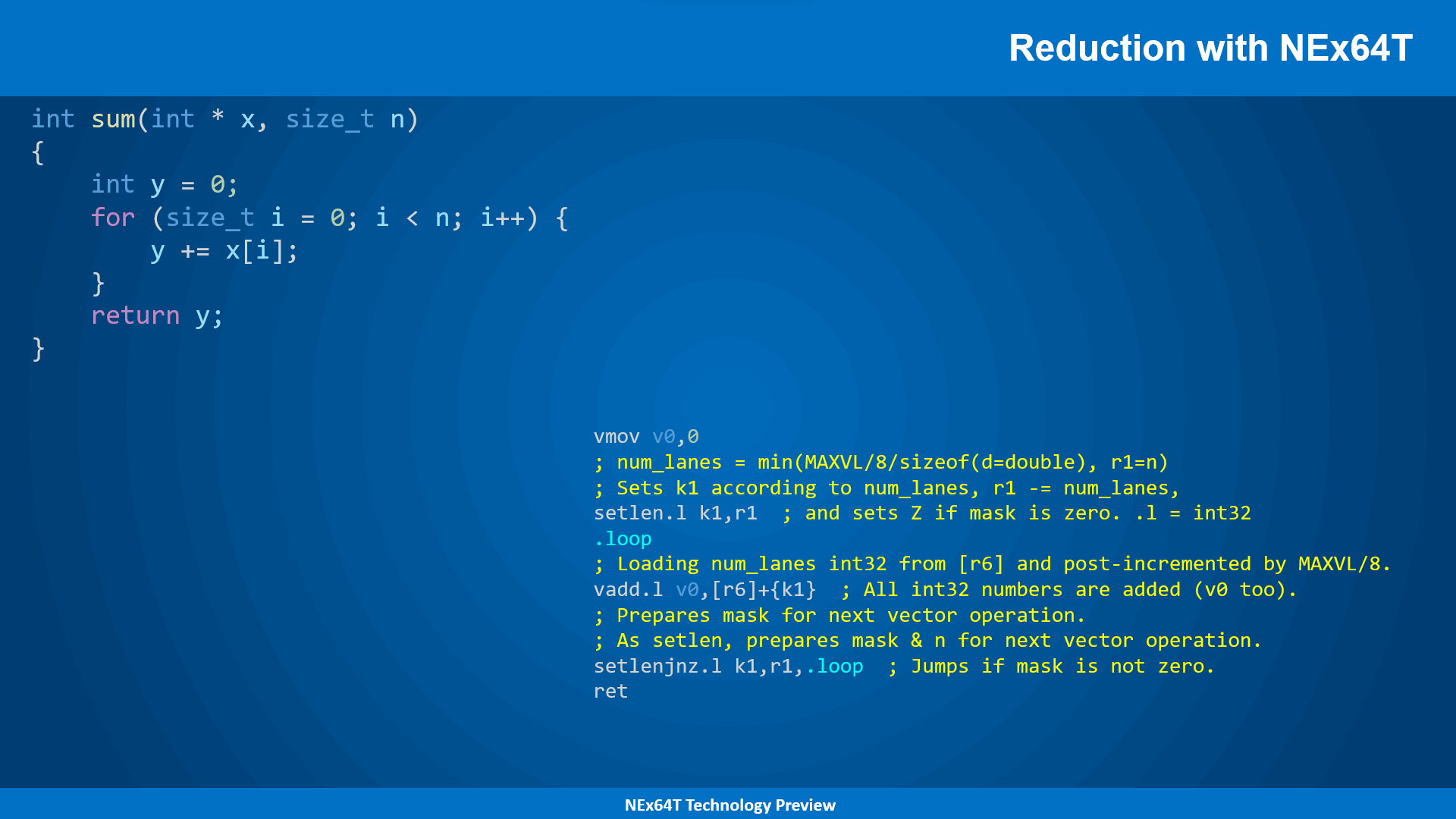
Sfruttando la tradizione CISC di poter referenziare direttamente i dati in memoria, l’operazione di riduzione di una porzione del vettore si traduce in… una sola istruzione! Non serve aggiungere altro, in quanto la semplicità del codice è, già di per sé, più che sufficiente a dimostrare l’enorme flessibilità e capacità di questa nuova architettura.
Va, però, sottolineato un particolare aspetto di NEx64T, che la differenzia dalle architetture anche più note nonché blasonate: non servono nuove, apposite, istruzioni di riduzione da aggiungere all’ISA. Infatti qualunque istruzione vettoriale è (ri)utilizzabile in “modalità riduzione”: si farà carico il backend del processore di processarle in maniera corretta per portare a termine l’operazione, in maniera del tutto trasparente.
Un’altra peculiarità di queste istruzioni è che possono essere “interrompibili”, a seconda della particolare implementazione adottata. Se, infatti, il processore riceve un segnale di interruzione a priorità molto elevata (ad esempio in un sistema real-time) e il backend non è in grado di completare velocemente l’operazione, allora l’esecuzione dell’istruzione verrà sospesa, per poi essere riesumata una volta terminata l’interruzione.
Il vantaggio, rispetto ad altre architetture, è che questo meccanismo non richiede l’aggiunta di alcunché per memorizzare lo stato corrente dell’istruzione, in quanto questa conserva già tutto l’occorrente (nel registro k1, nell’esempio specifico) per poter essere ripristinata e continuare poi l’elaborazione.
Riduzione in versione “blocco di memoria”
Era a dir poco scontato, infine, che tali operazioni di riduzione fossero implementabili sfruttando la modalità “a blocco” già presentata, la quale calza in maniera assolutamente perfetta per scenari come questi:

Anche qui non serve aggiungere altro, perché il codice si commenta da sé!
Conclusioni
E’ arrivato il momento di chiudere l’articolo, che si è dilungato molto perché c’era parecchio da dire sulle unità SIMD/vettoriali, le quali rappresentano uno degli elementi più importanti nei processori moderni (basti vedere quanto spazio occupano in termini non soltanto di numero di istruzioni, ma anche del silicio & transistor impiegati per la loro implementazione).
D’altra parte queste unità nascono per portare il concetto di processamento di dati ad altri livelli ed è il motivo per cui, da una ventina d’anni a questa parte, rivestono un ruolo centrale, di primo piano, all’interno dei core dei processori, e sui quali si investe ormai molto più rispetto alle unità “general-purpose“.
NEx64T, come abbiamo visto, mette tantissima carne sul fuoco, con un’estensione non soltanto al passo coi tempi, ma fornendo anche delle innovazioni non di poco conto che la rendono molto più flessibile nonché performante rispetto alla concorrenza.
Oltre a quanto già detto aggiungo al volo alcune caratteristiche che è importante riportare per completezza:
- sono disponibili fino a 32 registri SIMD/vettoriali, a prescindere dalla modalità di esecuzione (32 o 64 bit). x86 (32-bit) è, invece, limitato a soli 8 registri (ed esclusivamente SSE o AVX: non è possibile usare AVX-512), mentre x64 è limitata a 16 registri con SSE e AVX, e richiede AVX-512 per accedere a tutti i 32 registri;
- rispetto ad AVX-512 è possibile avere fino a 16 registri per le maschere (8 in più rispetto ad AVX-512), che possono far comodo anche nel caso si debbano eseguire dei calcoli su di esse;
- non esiste una miriade di istruzioni di conversione di tipo, ma soltanto alcune che sono in grado di convertire da un qualunque tipo ad un altro;
- ogni istruzione SIMD/vettoriale può essere eseguita condizionatamente (in base ai flag di x86/x64).
Un aspetto innovativo che merita di essere elencato a parte è quello che tale unità sia “ibrida”. Consente, cioè, di miscelare durante l’esecuzione sia istruzioni SIMD (quindi utilizzando registri a lunghezza fissa, come le MMX/SSE/AVX/AVX-512) sia istruzioni vettoriali (con registri a lunghezza variabile).
Il grosso limite delle architetture concorrenti è, infatti, che generalmente consentono di utilizzare soltanto l’una o l’altra, ma non entrambe allo stesso momento.
Come abbiamo visto, le istruzioni vettoriali sono comode perché consentono di generalizzare l’accesso e l’elaborazione dei vettori, senza dover conoscere a priori quanti elementi l’unità vettoriale sia in grado di contenere (e, quindi, di elaborare) nei relativi registri. Ma ha bisogno di una parte di inizializzazione e finalizzazione che consenta di “aggiustare il tiro” a seconda di quanti elementi si debbano elaborare e quanti ne siano rimasti.
Per contro, con le tradizionali unità SIMD si sa già quanti elementi possano contenere e processare, per cui possono “partire immediatamente” con l’elaborazione. Ma non sono in grado di gestire vettori di dimensione arbitraria, richiedendo apposite sezioni di inizializzazione e gestione degli elementi “in coda”.
Ci sono scenari per cui è ottimale un modello anziché l’altro, e viceversa, ed è questo il motivo per cui NEx64T consente di poter eseguire indifferentemente e allo stesso tempo istruzioni di entrambe le tipologie, garantendo la massima flessibilità possibile.
Con questo si chiude la trattazione di questa parte della nuova architettura. Il prossimo articolo effettuerà un confronto di massima con la concorrenza, esponendo le motivazioni per cui abbia senso prendere in considerazione l’opportunità di utilizzare questa nuova architettura e, quindi, perché valga la pena investirci.







