
Dopo l’introduzione di NEx64T, avvenuta nel precedente articolo, è arrivato il momento di iniziare a portare dei fatti a sostegno delle affermazioni ivi presentate.
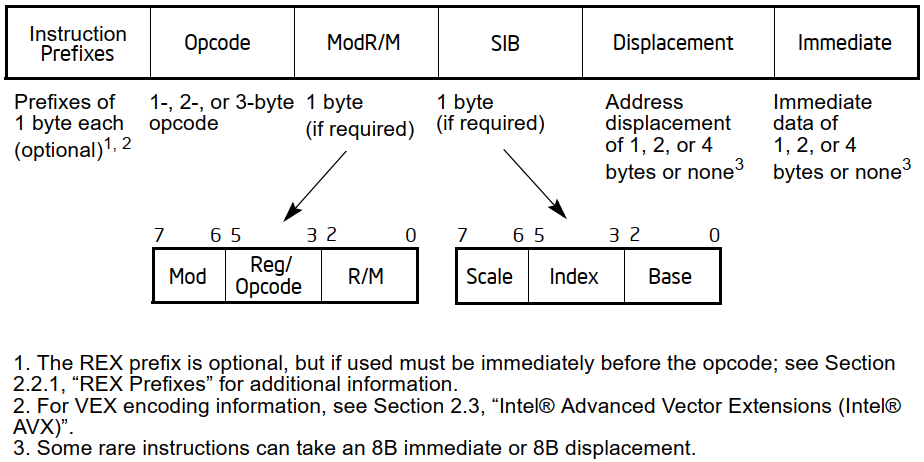
x86 e x64 sono ben note per essere particolarmente problematiche per quanto riguarda la decodifica delle loro istruzioni, a causa delle scelte progettuali che sono state fatte nel corso di tutti gli anni, come abbiamo già visto nello schema riportato in precedenza, che ripropongo per comodità:
Per contro, NEx64T è stata presentata come molto più semplice in quanto non fa uso di alcun prefisso e ha una struttura degli opcode più ordinata e molto più facile da decodificare, frutto di scelte progettuali completamente diverse (d’altra parte e come già anticipato nell’altro articolo, col senno di poi è facile, anche se non affatto scontato, fare di meglio).
Formato delle istruzioni
Per facilitare lo scopo ho preferito inserire alcune slide che permettono chiarire meglio il formato degli opcode, il perché di alcune scelte, e alcune statistiche (che sono utili anche a capire il motivo per cui la decodifica risulti di gran lunga più facile rispetto a x86/x64):

All’apparenza potrebbe sembrare più complicato rispetto a x86/x64, perché abbiamo ben cinque formati per gli opcode più una loro versione estesa (usando un opcode più grande), mentre il diagramma di Intel in apparenza mostrerebbe un solo formato.
In realtà il diagramma di Intel semplifica una situazione che è ben diversa, poiché racchiude anche i primi quattro formati di NEx64T, come pure l’estensione degli opcode (che equivale all’uso dei prefissi in x86/x64). L’unico nuovo formato è il quinto, perché consente di specificare due operandi in memoria, che rappresentano una novità.
Le informazioni a destra della slide non sono direttamente collegate ai formati delle istruzioni, ma sono puramente statistiche e forniscono dati sul come siano distribuiti tali formati all’interno dello spazio degli opcode. Sono, quindi, utili soltanto per comprendere in che modo sia stato utilizzato tale spazio; materiale per smanettoni, insomma.
I problemi della decodifica
In ogni caso e tornando ai due diagrammi astratti (quello di Intel e quello qui sopra di NEx64T), questi non forniscono alcuna concreta idea sulla complessità della decodifica delle istruzioni, in quanto mancano i dettagli concreti o, in generale, informazioni utili allo scopo.
In particolare, serve capire come ottenere:
- la lunghezza dell’istruzione;
- la lunghezza dell’opcode di base (al netto, cioè, di eventuali valori immediati e/o operandi in memoria);
- se l’istruzione ha una valore immediato oppure no, ed eventualmente quanto è grande;
- se l’istruzione ha un operando (o anche due, per NEx64T) in memoria oppure no;
- se l’eventuale (o eventuali) operando in memoria ha un offset, ed eventualmente quanto è grande (o sono grandi);
- la posizione (all’interno dei byte dell’istruzione) di tutti i summenzionati elementi (opcode di base, valore immediato e offset).
Questo è il minimo indispensabile che serve al decoder delle istruzioni per capire per lo meno con cosa sta avendo a che fare e quali informazioni dovrà estrarre (dove e quanto prelevare, in particolare) per poter poi proseguire col rimanente lavoro.
Al momento non è nemmeno importante conoscere di quale tipologia di istruzione si tratti (intera / scalare, FPU, SIMD, …) o della specifica istruzione, perché ciò servirà soltanto nei passaggi successi (gli stadi seguenti della pipeline).
La decodifica per x86/x64: i prefissi!
Come potete immaginare, ricavare quanto riportato qui sopra per x86/x64 risulta parecchio problematico, a causa della struttura dei suoi opcode, tutt’altro che banale (basti rivedere il diagramma riportato all’inizio).
La prima cosa che il decoder deve fare è andare a caccia dei prefissi. Le istruzioni possono essere lunghe al massimo 15 byte, ma possono anche contenere un numero imprecisato di prefissi (ovviamente deve poi esserci l’opcode e gli eventuali suoi argomenti).
Ciò richiede la scansione dei primi byte marcando se un byte risulti essere un prefisso oppure no. A questo punto rintracciare l’opcode diventa più facile: basta trovare il primo byte che non sia stato riconosciuto come prefisso.
Bisogna, però, fare attenzione ad alcuni casi speciali:
- il prefisso
0Fintroduce una nuova mappa di opcode (fino a 256 nuove istruzioni). Quindi il decoder dovrà prendere il byte successivo, ma magari aggiungerci qualcosa (ad esempio… 256. Che in esadecimale valeox100) per ottenere il valore effettivo da utilizzare per poter distinguere queste nuove istruzioni da quelle normali / base dell’ISA. In buona sostanza, i normali opcode andranno da 0 a 255, mentre i nuovi introdotti da0Fandranno da 256 a 511; - due opcode all’interno di
0F,0F 38e0F 3A,espandono ulteriormente gli opcode con due mappe di 256 istruzioni ciascuna. Per cui se il decoder ha trovato il prefisso0F(come da precedente punto) deve comunque fare un controllo aggiuntivo dopo aver prelevato il byte successivo, vedere se questo sia38oppure3A, e in questo caso andare a prelevare il byte seguente che sarà il vero e proprio opcode. Anche in questo caso si occuperà di sommarci un apposito valore (ad esempio 512 =0x200e 768 =0x300) in modo da non confondere questi nuovi opcode con quelli precedenti. Alla fine, con questi due meccanismi, si possono avere fino a 1024 istruzioni in totale; - similmente a
0F, Intel ha introdotto ulteriori prefissi di 2 o 3 byte con l’estensione AVX, che aggiunge un meccanismo più semplice, versatile e più compatto per le istruzioni SIMD (SSE), come pure per alcune nuove istruzioni intere / scalari. Anche in questo caso il decoder dovrà prima verificare che si trovi davanti al prefisso di due byte (C5) oppure tre byte (C4), e provvedere a estrarre il byte o i due byte successivi e a conservarne da qualche parte (internamente) i valori, che può utilizzare per espandere la mappa degli opcode, ma in generale per introdurre nuovi registri e nuove funzionalità (registri SIMD di dimensione doppia rispetto a SSE, ad esempio); - poiché aveva bisogno di estendere ulteriormente l’unità SIMD, Intel ha poi aggiunto un ulteriore prefisso (
62), questa volta di ben 4 byte, con l’estensione AVX-512 in modo da poter specificare ulteriori nuovi registri e parecchie altre funzionalità. Anche qui, come per AVX, il decoder dovrà provvedere a estrarre tutte le informazioni dai tre byte successivi a tale prefisso, e conservarle internamente; - anche AMD nel frattempo s’era data da fare e aveva introdotto un nuovo prefisso (chiamato REX) che fa uso di 16 opcode contigui (da
40a4F) nella nuova modalità a 64 bit (x64. Chiamata inizialmentex86-64e successivamente ancheAMD64oEM64ToIntel 64). In questo caso il decoder, dopo aver verificato che si tratti di uno di questi 16 prefissi, si occupa di estrarre i 4 bit che si portano dietro e li conserva internamente per selezionare i nuovi registri o forzare la dimensione dei dati da manipolare per l’istruzione (ad esempio usare 64 bit anziché 32); - infine Intel ha ulteriormente complicato le cose con la nuovissima estensione APX (di cui abbiamo parlato in una recente serie di articoli), la quale ha introdotto un ulteriore prefisso di due byte (
D5) chiamato REX2 e che, come suggerisce il nome, funziona in maniera simile a REX, ma portandosi dietro molte più informazioni (8 bit anziché 4). Quindi anche qui il decoder dovrà provvedere a estrarre le informazioni del byte successivo e conservarle internamente.
Questi prefissi sono i più complicati da gestire, mentre tutti gli altri sono più semplici perché si occupano di cambiare il comportamento dell’istruzione relativamente a una sola caratteristica:
F0, chiamato ancheLOCK, indica che il processore dovrà effettuare un’operazione atomica di lettura-modifica-scrittura. Il problema, qui, è che l’uso di questo prefisso è consentito esclusivamente con poche istruzioni, per cui il decoder dovrà verificare che l’istruzione che sta decodificando sia una di quelle e, diversamente, sollevare un’eccezione (di istruzione illegale);F2eF3vengono utilizzati per la ripetizione di operazioni cosiddette di stringa (si tratta di poche istruzioni:LODS,STOS,MOVS,INS,OUTS,CMPSeSCAS). In questo caso il decoder dovrà controllare il tipo di istruzione, il prefisso utilizzato (che ha un significato diverso per alcune di queste istruzioni di stringa), e segnalare il tutto al backend (che si occupa dell’esecuzione effettiva dell’istruzione), in modo che sappia come gestirle. Come se non bastasse, questi due prefissi sono stati utilizzati dall’estensione SSE per introdurre nuove istruzioni SIMD; quindi il decoder dovrà tenerne conto, anche nel caso di istruzioni facenti uso dei prefissi0F,0F 38e0F 3A;26,2E,36,3E,64,65sono usati per forzare il segmento/selettore da utilizzare per l’operando sorgente in memoria, invece di quello di default.3Ee2Esono anche usati nelle istruzioni di salto per segnalare, rispettivamente, che il salto potrebbe esser preso oppure no;66cambia la dimensione dei dati da manipolare. Quindi indica di utilizzare 32 bit anziché 64 bit, ad esempio, oppure 16 bit anziché 32;67cambia la dimensione degli indirizzi. Quindi troncherà gli indirizzi a 64 bit facendoli diventare di 32 bit, oppure quelli di 32 bit facendoli diventare di 16.
Penso sia evidente di quanto lavoro sia necessario e quante complicazioni si presentino al decoder per poter estrarre le informazioni che qualifichino la particolare istruzione e, infine, ottenere quale effettivamente sia l’operazione da seguire (quello che ho chiamato opcode di base, in precedenza).
Anche se devo aggiungere che ci sono diversi altri casi speciali che fanno uso di prefissi per implementare ulteriori estensioni (MPX, SGX, TSX, …), e di cui ho preferito non parlare per non appesantire ancora di più l’articolo. Quindi sappiate che la situazione reale è ancora più complessa!
La decodifica per x86/x64: operando in memoria e valore immediato
Ma non è certo finita qui. Infatti quanto finora descritto si occupa esclusivamente della prima parte di un’istruzione, che coinvolge “soltanto” i prefissi e l’opcode, per l’appunto: all’appello mancano ancora i campi ModR/M, SIB, Displacement e Immediate (come da precedente diagramma), che sono facoltativi.
Per capire se siano presenti o meno è necessario prima ottenere l’opcode di base e, quindi, sbrogliare la precedente matassa. E’, infatti, soltanto adesso che il decoder è in grado di capire se un’istruzione ha un operando in memoria e/o un valore immediato.
In realtà la cosa non è così semplice perché, come già anticipato nel precedente articolo, le istruzioni di x86/x64 non sono raggruppate regolarmente, ma soltanto alcune lo sono, mentre altre sono sparse in maniera del tutto arbitraria nelle quattro mappe degli opcode che abbiamo già visto.
Probabilmente e per semplicità implementativa, il decoder avrà una mappa interna di 1024 bit (un bit per ogni istruzione) che consulterà per capire se quella particolare istruzione referenzi o meno un operando in memoria e, quindi, che eventualmente subito dopo l’opcode sarà presente il byte col campo ModR/M.
Se si rientra in questo caso, dovrà poi esaminare questo campo perché ci sono alcuni precisi valori che indicano la presenza o meno di SIB, il quale, se presente, dovrà essere estratto dal byte successivo. Quindi la verifica della presenza di questo campo è subordinata al controllo del precedente ModR/M.
Allo stesso modo, esaminando alcuni bit di ModR/M è possibile sapere se subito dopo di esso, oppure dopo SIB, sarà presente l’offset (Displacement) da utilizzare per referenziare la locazione di memoria, e in tal caso anche la sua dimensione (uno o due byte per le vetuste modalità di esecuzione a 16 bit. Uno o quattro byte per quelle nuove a 32 o 64 bit).
In questo caso il controllo di Displacement è subordinato a quello di SIB, poiché, pur essendo soltanto ModR/M a determinare se sia presente o meno , non è possibile sapere prima dove andare a prelevare i byte costituenti il valore dell’offset.
Per chiudere la questione che riguarda l’operando in memoria bisogna aggiungere che la decodifica di ModR/M e SIB è un po’ più complicata, in quanto ci sono dei casi speciali da considerare. Infatti alcune volte non è possibile utilizzare un particolare registro in qualche modalità d’indirizzamento, perché ciò serve per indicare la presenza del byte SIB, per l’appunto, oppure indica la soppressione del registro base nella modalità d’indirizzamento con indice scalato (quindi ci sarebbe soltanto l’indice scalato e l’eventuale offset).
Inoltre in modalità a 64 bit scompare l’indirizzamento assoluto in memoria (che è relegato soltanto a un paio di specifiche istruzioni MOV) per far posto alla nuova modalità relativa al registro RIP (la quale, quindi, permette di scrivere codice completamente rilocabile).
Infine e per similitudine, probabilmente il decoder utilizzerà un’ulteriore mappa di 1024 bit per stabilire se quella particolare istruzione sia dotata di valore immediato oppure no. Sarebbe possibile effettuare questo controllo in parallelo con quello della presenza di ModR/M, ma bisognerebbe in ogni caso aspettare che la decodifica di quest’ultimo sia completata (visto che non è così semplice).
Infatti un valore immediato, se presente, si trova sempre alla fine dell’istruzione, per cui sapere a partire da quale byte poterlo leggere è in ogni caso subordinato al completamento dei calcoli relativi all’eventuale operando in memoria.
Ma a complicare il tutto c’è da dire che i valori immediati presentano diversi casi, a seconda della particolare istruzione. Infatti, un valore immediato può essere:
- della stessa dimensione dei dati manipolati dall’istruzione (8, 16, 32 bit);
- a 32 bit per le istruzioni che manipolano 64 bit (perché non è possibile avere valori immediati a 64 bit). In questo caso il valore a 32 bit sarà esteso a 64 bit;
- a 64 bit, ma soltanto con l’unica istruzione che consente di caricare un valore nell’accumulatore (il registro
RAX); - a 8 bit, ma esteso alla dimensione dei dati manipolati dall’istruzione.
Ovviamente il decoder dovrà sapere in quale di questi casi si trovi. A parte il terzo, che è molto semplice (c’è una sola istruzione da controllare), e il secondo (basta forzare la lettura di 32 bit quando la dimensione dei dati è a 64 bit), per distinguere fra il primo e il quarto potrebbe utilizzare un’altra mappa di bit per capire in quale dei due si trovi.
A questo punto il decoder ha, finalmente, tutti gli elementi e le informazioni relative all’istruzione, che può impacchettare in maniera più semplice e spedire al backend per l’effettiva esecuzione.
In particolare, adesso è perfettamente in grado di stabilire la lunghezza dell’istruzione. Mi preme particolarmente di sottolineare questo punto, poiché è assolutamente fondamentale per praticamente tutti i processori moderni, i quali sono in grado di eseguire più istruzioni per ciclo di clock.
Ma poter eseguire più istruzioni significa che il decoder deve conoscere la lunghezza della prima istruzione prima di poter finalmente passare a fare i calcoli per determinare quella della seconda, e così via per la terza, la quarta, ecc..
Poiché, e come abbiamo visto, già una singola istruzione di x86/x64 richiede una miriade di calcoli e considerazioni da fare anche soltanto per determinarne la lunghezza, si può immaginare quanto difficile e quante risorse siano necessarie nel caso in cui si abbia a che fare con più istruzioni da decodificare ed eseguire per ogni ciclo di clock.
La decodifica per NEx64T
Inutile dire che con NEx64T la situazione sia non soltanto migliore, ma diametralmente opposta rispetto alle altre due architetture. Infatti e pur avendo anch’essa istruzioni lunghe (potenzialmente anche molto più lunghe), non è affatto necessario scorrere i byte per andare a caccia di tutte le informazioni che ci servono: è sufficiente esaminare soltanto i primi bit per poter estrarre quasi tutto ciò che serve.
Più precisamente, l’analisi del primo byte (quindi dei primi 8 bit) è già sufficiente a poter decodificare tutti i campi (a accezione dell’opcode base. Ma ne parlo meglio dopo) di circa l’89% dello spazio degli opcode (da non confondere col numero di istruzioni).
Mentre la lettura del byte successivo, e specificamente dei suoi sei bit meno significativi (l’architettura è little-endian e la struttura degli opcode si sviluppa a partire dai bit meno significativi), consente di completare il tutto, coprendo l’intero spazio degli opcode.
La successiva slide riporta in maniera precisa (a parte l’approssimazione delle percentuali) la situazione:

Questa tabella riepilogativa va letta in un certo modo, per cui merita una spiegazione più approfondita.
Prendendo il primo caso, ad esempio, vuol dire che sono sufficienti i primi quattro bit (quelli meno significativi, come già detto) dell’opcode per determinare:
- la lunghezza dell’istruzione;
- la dimensione dell’opcode base (che, in generale, occupa da 2 a 8 byte);
- se referenzia o meno un operando in memoria;
- se ha un operando in memoria, dove si trova il campo
Mem/Reg(l’equivalente diModR/MeSIB, messi assieme. Occupa due byte / 16 bit); - se ha un operando in memoria, indica se è presente un offset;
- se ha un offset, dove si trova;
- se ha un offset, quanto è lungo;
- se ha un valore immediato, dove si trova;
- se ha un valore immediato, quanto è lungo.
In buona sostanza, esaminando i primi quattro bit è già possibile conoscere immediatamente tutte queste informazioni, senza alcun calcolo aggiuntivo, per il 37,5% degli opcode. In alcuni casi (pochi. D’altra parte sono soltanto quattro bit!) è possibile sapere anche l’opcode dell’istruzione (ad esempio se si tratti di un salto condizionato).
La scritta a seguire cerca di fornire alcune informazioni addizionali su quali opcode / istruzioni siano coperte da questo caso, specificando che si tratta di opcode a 16 bit, quasi interamente dedicati a quelle che in gergo vengono chiamate istruzioni “compatte” (cioè esatti equivalenti di altre istruzioni, ma che occupano meno spazio).
Passando al secondo caso, ossia potendo prelevare i primi cinque bit, sarà possibile ottenere tutte le informazioni di cui sopra anche (perché ovviamente si aggiungono anche le istruzioni del primo caso) della stragrande maggioranza delle istruzioni SIMD, ma questa volta arrivando a coprire quasi il 72% di tutti gli opcode!
Adesso la novità è rappresentata anche dal fatto che la maggior parte delle istruzioni SIMD referenzia una locazione di memoria, per cui sarà presente il campo Mem/Reg e, quindi, l’eventuale offset. Ma cinque bit sono sufficienti a ottenere tutte queste informazioni (a parte l”opcode base delle istruzioni SIMD).
E così via: aumentando il numero di bit a disposizione è possibile decodificare sempre più opcode / istruzioni e prelevarne tutte le informazioni (a volte includendo anche l’opcode base). Il tutto fino a un massimo di 14 bit, ovviamente (si raggiunge il 100% di copertura).
Parlando anche del succitato Mem/Reg, bisogna aggiungere che il formato di questo campo risulta abbastanza semplice: le modalità d’indirizzamento messe a disposizione sono elencate linearmente, coi loro sotto-campi nel caso in cui siano presenti più elementi che concorrono alla definizione della specifica modalità (ad esempio i registri base e indice per la modalità indicizzata e scalata), e non sussistono eccezioni (come succede, invece, a ModR/M e SIB).
Penso che, a questo punto, il confronto con x86/x64 sia a dir poco impietoso…
Il formato delle istruzioni NEx64T
Non è, però, tutto oro ciò che luccica. Infatti, e come già riportato diverse volte, spesso manca l’opcode base (di cui si conosce soltanto la dimensione, come riportato sopra), che serve a qualificare in maniera precisa l’istruzione da eseguire, con eventuali registri da utilizzare, la dimensione dei dati da manipolare, particolari comportamenti delle istruzioni, eventuali valori immediati incorporati, ecc..
Per far questo è necessario analizzare l’opcode base per estrarre queste informazioni che mancano, ma l’impresa non è ardua come per x86/x64, in quanto le istruzioni non sono state sparse in maniera pseudo-casuale nello spazio degli opcode, ma risultano raggruppate in particolari strutture (chiamate formati delle istruzioni, in gergo).
Ecco alcuni esempi:

Nello specifico il campo Opcode contiene il codice numerico associato a una particolare istruzione. Ad esempio 01000100 (in binario) identifica l’istruzione SHLD Mem,Reg nel gruppo delle istruzioni binarie (quelle che hanno bisogno di due argomenti sorgenti per effettuare i calcoli), mentre a 01001001 corrisponde JMP Mem delle istruzioni unarie (con un solo argomento necessario), a 11110101 corrisponde FISUBR Mem nelle istruzioni unarie dell’FPU il cui unico argomento (in memoria o in un altro registro) è un valore intero, e infine 010000 è il codice dell’istruzione SIMD/vettoriale BLEND V1,V2,V3/Mem,Imm8 (la quale richiede tre argomenti sorgente).
E’ interessante evidenziare come Opcode specifichi esclusivamente l’istruzione base, mentre la dimensione dei dati si trovi in un campo a parte (Size, che è l’unico presente nelle istruzioni general-purpose. A cui si aggiunge I/F in quelle dell’FPU o dell’unità SIMD/vettoriale, che serve a specificare se si tratti di un valore intero o in virgola mobile).
In questo modo non esistono tanti formati per le istruzioni, perché queste ultime sono strutturate in maniera semplice e, soprattutto, ortogonale. Ciò ha consentito anche di ridurne considerevolmente il numero.
Ad esempio, l’istruzione BLEND riportata qui sopra mappa tutte le seguenti istruzioni x86/x64: VBLENDPD, VBLENDPS, VPBLENDW, VPBLENDD, BLENDPD, BLENDPS, PBLENDW. Questo perché la dimensione dei dati, il tipo di dati (intero o in virgola mobile), il fatto che siano dati scalari o “packed” (con più valori), la dimensione dei registri vettoriali, e infine anche il tipo di estensione SIMD o vettoriale da usare (da MMX fino ad AVX-1024, oppure AVX-Vec che è la nuova estensione completamente vettoriale) sono tutti parametri dell’istruzione base (di una qualunque istruzione base, per la precisione, grazie alla loro ortogonalità).
C’è da dire che rispetto a tante architetture Load/Store (L/S: gli ex-RISC) ho utilizzato più formati per le istruzioni, che hanno consentito di sfruttare meglio lo spazio a disposizione per gli opcode (che è sempre limitato, anche per un’architettura a lunghezza variabile), ma non in maniera esagerata e, quindi, perfettamente gestibile.
In particolare buona parte dei formati sono relativi alle istruzioni cosiddette “compresse”, che sono duplicati di normali istruzioni, ma che occupano meno spazio. Ovviamente lo scopo è di guadagnare molto per la densità di codice.
Per le normali istruzioni, invece, sono pochi i formati utilizzati. Ad esempio, basti pensare che le istruzioni più complesse, cioè quelle che consentono di specificare un argomento in memoria e un valore immediato, fanno uso di un solo formato (e non sono presenti i quattro casi di x86/x64 che sono stati prima elencati per i valori immediati). Quelle binarie e unarie usano anch’esse un solo formato a testa (estremamente simile).
Le rimanenti istruzioni che usano immediati (quindi senza un argomento in memoria) usano pochi formati che consentono di specificarne il valore in base alla dimensione dei dati (quindi fino a 64 bit) oppure hanno un formato fisso (soltanto 16 bit. Soltanto 32 bit. Soltanto 64 bit). Comunque niente casi speciali: tutto è già perfettamente definito grazie ai pochi bit iniziali delle istruzioni (come già spiegato sopra).
Ci si potrebbe aspettare che quelle SIMD/vettoriali richiedano molti formati. In realtà ne esiste soltanto uno per tipologia di istruzioni: ternarie, ternarie specializzate, ternarie con immediato, ternarie specializzate con immediato, binarie, binarie specializzate, unarie, unarie specializzate, nullarie. A cui si aggiungono alcune versioni compatte o altre che operano soltanto coi registri e consentono di specificare direttamente l’arrotondamento o gestire la soppressione delle eccezioni (esattamente come fa AVX-512).
Tornando al confronto con x86/x64 e per chiudere, certamente il fatto che esistano diversi formati delle istruzioni complica la loro decodifica (perché per ogni formato serve andare a recuperare le informazioni necessarie), ma loro organizzazione semplice e regolare facilita moltissimo il compito, similmente a tante architetture L/S moderne (che, comunque, utilizzano ormai diversi formati per gli stessi motivi: sfruttare meglio il poco spazio a disposizione negli opcode).
Conclusioni
E’ stata messa parecchia carne al fuoco, ma considerato che la facilità di decodifica è uno dei punti forti di NEx64T, ciò ha comportato un’analisi un po’ più approfondita (sebbene abbia preferito, anche per questioni mie personali, di non pubblicare la struttura completa di tutti gli opcode).
Penso sia abbastanza evidente che, da questo punto di vista, la nuova architettura rappresenti un enorme passo in avanti rispetto a x86/x64 (non esistono i prefissi!), consentendo di implementare in maniera di gran lunga più efficiente e ridotta il frontend del processore, a tutto vantaggio dei costi implementativi e dei consumi.
L’enorme semplicità potrebbe consentire di utilizzare anche soluzioni molto diverse rispetto a quelle attuali, dove nella cache istruzioni vengono aggiunte appositamente delle informazioni ad hoc (chiamate tag bit) per evitare o cercare di velocizzare i calcoli relativi alla lunghezza delle istruzioni, con un notevole dispendio in termini di transistor utilizzati e un aumento dei consumi.
Infatti con architetture in-order o out-of-order con poche istruzioni (due o anche tre) eseguibili per ciclo di clock, si potrebbe pensare di evitare del tutto l’uso dei tag bit e affidarsi unicamente ad un’apposita circuiteria per il calcolo della lunghezza di ogni istruzione.
Si aprono, insomma, nuove opportunità anche in mercati embedded low-end, dove i core dei processori sono piccoli e richiedono pochi transistor per la loro implementazione.
Il prossimo articolo riporterà alcune statistiche relative alla densità di codice e al numero di istruzioni eseguite, per fornire un’idea (sono ancora dati preliminari) dei vantaggi concreti di NEx64T (rispetto non soltanto a x86/x64, ma anche a tante altre architetture).







