Questi anni di rapide e dirompenti innovazioni tecnologiche stanno regalando grandi emozioni a tutti noi appassionati di computer. Una rapida sequenza di cambiamenti nelle tecnologie di base sta scuotendo vecchie realtà e rimescolando i mercati: l’ascesa di Apple e Google a spese di Microsoft, di ARM a spese di Intel, l’ingresso di NVidia (e ora anche Intel) nel cortile di casa di Qualcomm.
Quattro i motivi tecnologici principali dietro questo rimescolamento:
- la fine della corsa alla frequenza dei processori al’inizio degli anni 2000 e l’ascesa delle architetture parallele ed eterogenee, tra cui le GPU e le APU
- l’inizio dell’era in cui il consumo di energia diventa il fattore limitante per la maggior parte dei chip, il che significa che le prestazioni per Watt diventano il più importante parametro di progettazione
- l’esplosione del mercato mobile, con nuovi dispositivi di massa e una curva di crescita esponenziale delle loro prestazioni, grazie al fatto che la densità di transistor per unità di area e potenza ha raggiunto la “soglia critica” per cui è possibile avere prestazioni quasi da computer in un dispositivo mobile
- l’impatto architetturale del costo sempre più proibitivo e la disponibilità sempre più scarsa dei nuovi nodi litografici, man mano che ci avviciamo ai limiti fisici del silicio
Questi rapidi e radicali cambiamenti tecnologici hanno dettato le linee guida nella progettazione delle nuove architetture di AMD e NVidia. AMD ha abbandonato l’efficientissima (nei giochi) architettura VLIW in favore di Graphics Core Next, architettura decisamente orientata al compute. NVidia invece si vanta, per la prima volta, di avere la most efficient GPU ever e non solo la più potente.
Per capire se le due case hanno raggiunto i rispettivi obiettivi e quanto le nuove architetture sono diverse dalle precedenti bisogna, come sempre, partire dai dati grezzi ed analizzarli in dettaglio. Considererò le attuali ammiraglie gtx680 e 7970 e le schede di fascia alta (a chip singolo) della precedente generazione, gtx580 e 6970. Per NVidia, ho aggiunto anche gtx560 al mix perchè gtx680 è una via di mezzo tra gtx580 e gtx560 (fascia alta per i giochi ma fascia media per il GPGPU).
Tutti i dati sono stati raccolti dalle review di Anandtech (che ritengo un riferimento mondiale per qualità, completezza e competenza), qui e qui, complementati da wikipedia qui, qui, qui, qui, qui e qui.
I dati di base
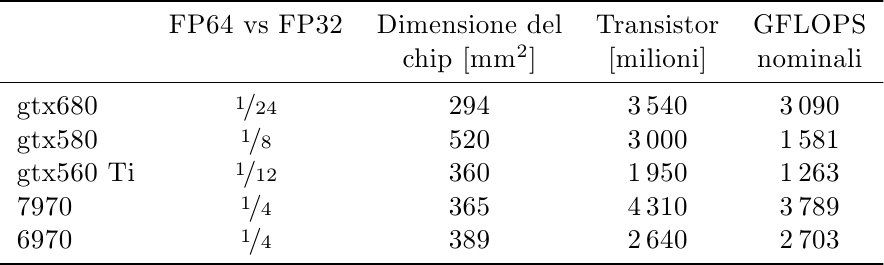
I dati di base che ho raccolto sono prestazioni in virgola mobile a doppia precisione, dimensione dei chip, numero di transistor e GFLOPS nominali:
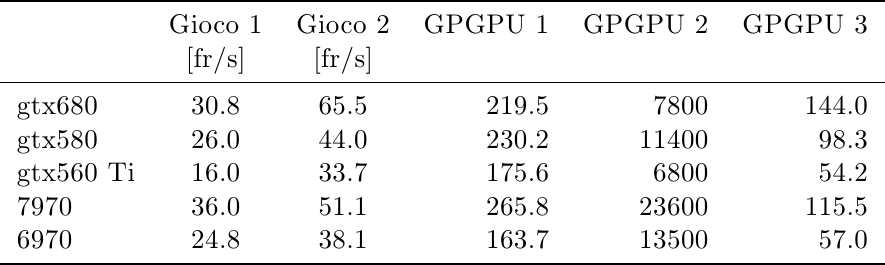
Per le prestazioni ho usato i dato di Anandtech: due giochi moderni e pesanti, uno favorevole ad AMD (Crysis Warhead) e l’altro a NVidia (Battlefield 3), più tre dei test GPGPU (Civilization V texture decompression, SmallLuxGPU, Fluid Simulation):
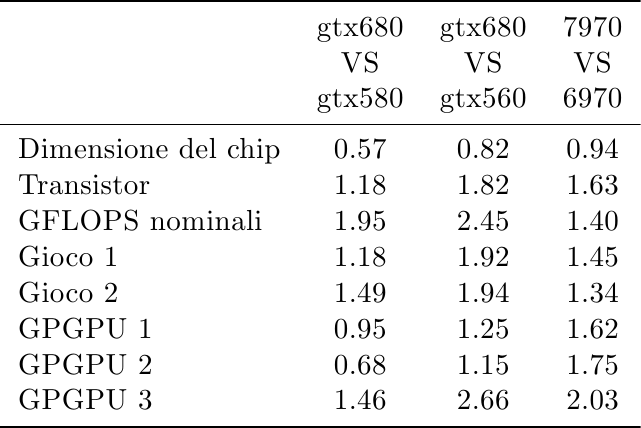
Di seguito, le variazioni dei nuovi chip rispetto ai vecchi:
Il primo dato considerato è il rapporto tra la potenza computazionale in virgola mobile a doppia precisione rispetto alla precisione singola. AMD offriva 1/4 delle prestazioni nella generazione precedente e non ha cambiato strategia con la nuova. L’offerta di NVidia è più complessa: gtx580 offre solo 1/8 perchè è la versione gaming, ma il chip è capace di 1/2, il resto è disabilitato per non cannibalizzare le vendite di schede Quadro e Tesla che sono un mercato molto redditizio. gtx560 offre solo 1/12 delle prestazioni: in questo caso non si tratta di unità di calcolo disabilitate bensì completamente mancanti, per ridurre l’area del chip e quindi il costo di fabbricazione. La vera sorpresa di gtx680 è stata l’ulteriore dimezzamento delle unità in doppia precisione (almeno nella versione gaming) rispetto a gtx560: NVidia con Kepler è stata estremamente aggressiva nell’inseguire la riduzione di area e l’aumento di efficienza in tutte le metriche (prestazioni per mm^2 e per Watt). Questo fatto, insieme al nome del chip (gk104 e non gk100 o gk110), suggerisce che NVidia aveva pianificato questo chip per equipaggiare l’erede di gtx560 e non di gtx580, e che abbia poi promosso il chip in fascia alta una volta che le prestazioni di 7970 sono diventate note.
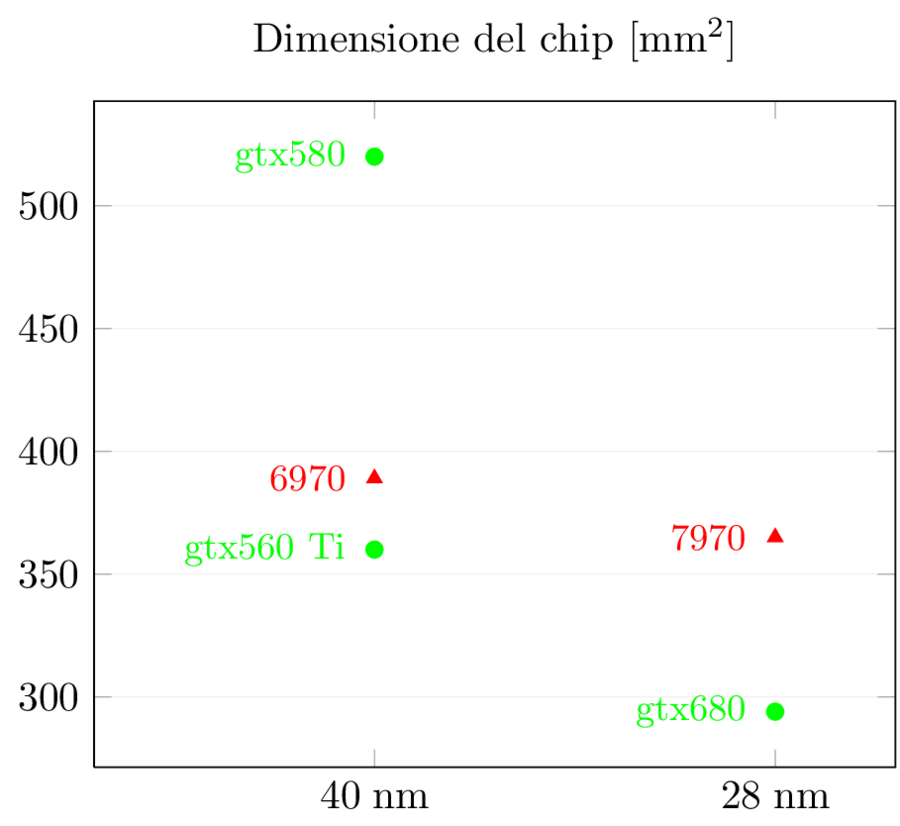
La dimensione dei chip è un altro dato molto interessante:
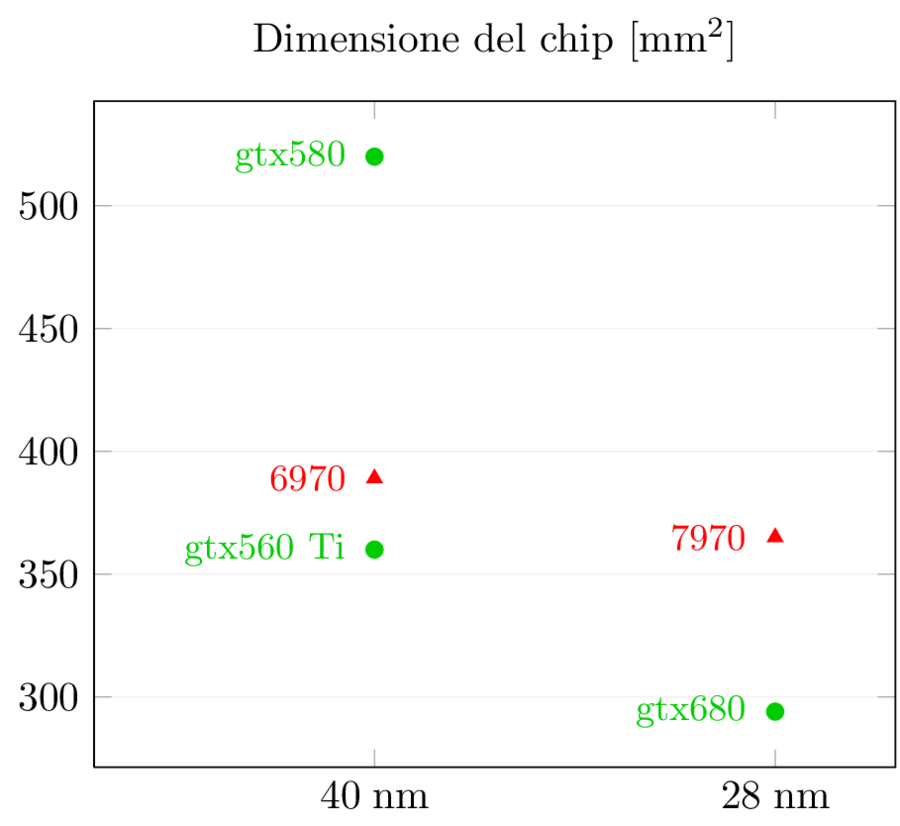 Mentre AMD è rimasta nello stesso range (una lieve diminuzione del 6%), NVidia ha cambiato completamente gioco: non solo è enormemente più piccolo di 580 (-43%!) ma è anche più piccolo di 560, e non di poco (-18%). Questo numero da solo mostra quanto NVidia sia stata aggressiva con Kepler nel risolvere i problemi di “obesità” di Fermi.
Mentre AMD è rimasta nello stesso range (una lieve diminuzione del 6%), NVidia ha cambiato completamente gioco: non solo è enormemente più piccolo di 580 (-43%!) ma è anche più piccolo di 560, e non di poco (-18%). Questo numero da solo mostra quanto NVidia sia stata aggressiva con Kepler nel risolvere i problemi di “obesità” di Fermi.
Il numero di transistor è un altro parametro di grande interesse: nuovi nodi mettono a disposizione una densità di transistor maggiore per unità di area e diverse compagnie hanno idee diverse in merito a come spenderli:
![]()
AMD ha deciso di tenere l’area del die circa costante e di aumentare (di un robusto 63%) il numero di transistor. Una buona parte di questi transistor in più sono il costo della nuova architettura orientata al compute. NVidia invece, come visto sopra, ha optato per un aumento modesto (il 18%) e ha sfruttato la maggiore densità per costruire un chip più piccolo, efficiente ed economico, sacrificando le capacità GPGPU (almeno per gk104).
La potenza grezza del chip in GFLOPS a precisione singola mostra dei numeri opposti, ma che confermano quanto detto sopra:
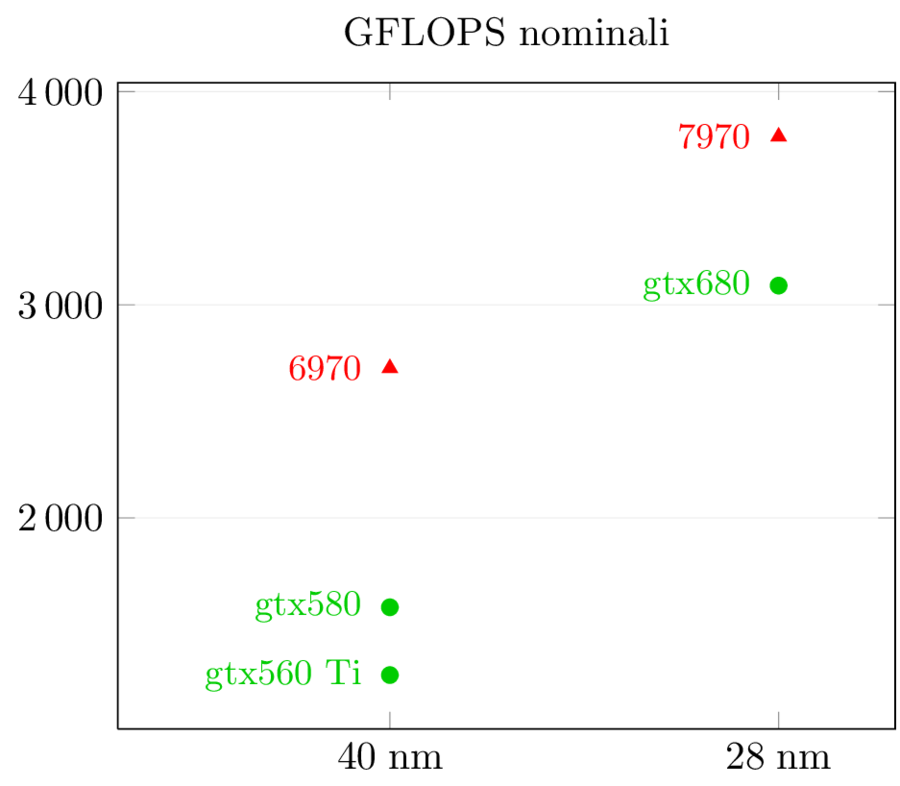
Kepler ha quasi raddoppiato i GFLOPS (+95%) usando solo il 18% di transistor in più: è evidente che c’è stato un enorme sforzo progettuale per aumentare l’efficienza dei CUDA core, al di là della riduzione delle capacità FP64 e della semplificazione dello scheduler che è tornato indietro da dinamico a statico; entrambe queste capacità non sono essenziali per i giochi e sono state rimosse da gk104. AMD invece ha seguito il cammino opposto, con un aumento di GFLOPS grezzi del solo 40% a fronte di un 63% di transistor in più: da una parte perchè i GFLOPS di AMD erano e rimangono superiori a quelli di NVidia, dall’altra perchè una buona fetta di quei transistor sono stati spesi in un’architettura molto più sofisticata che aiuta molto, come vedremo in seguito, nelle applicazioni GPGPU.
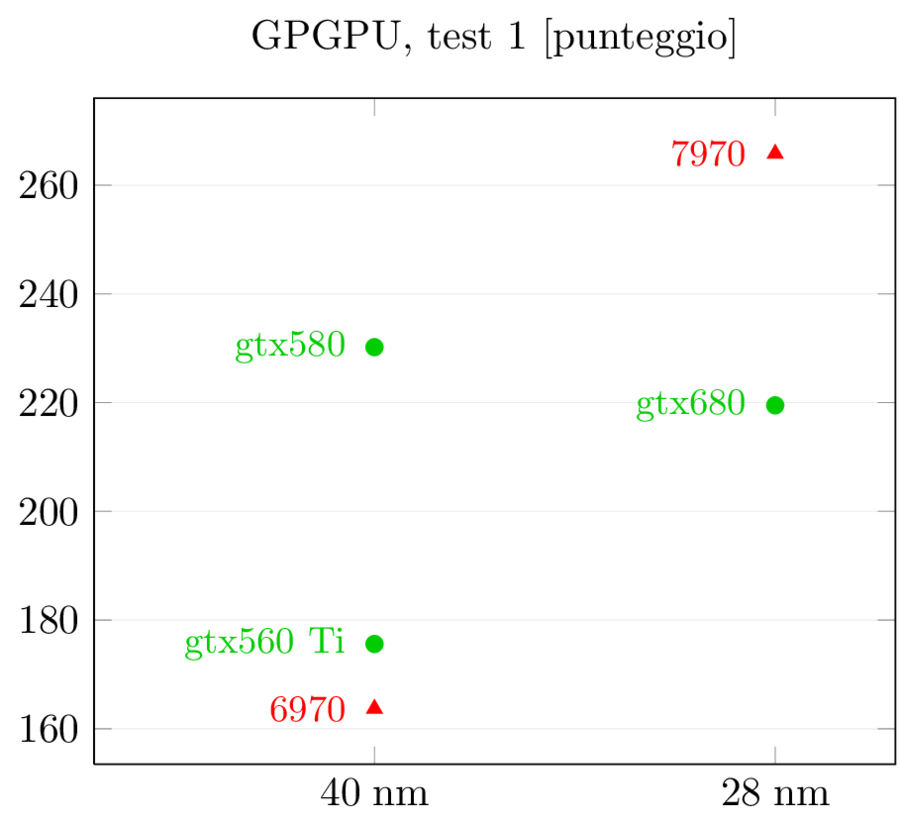
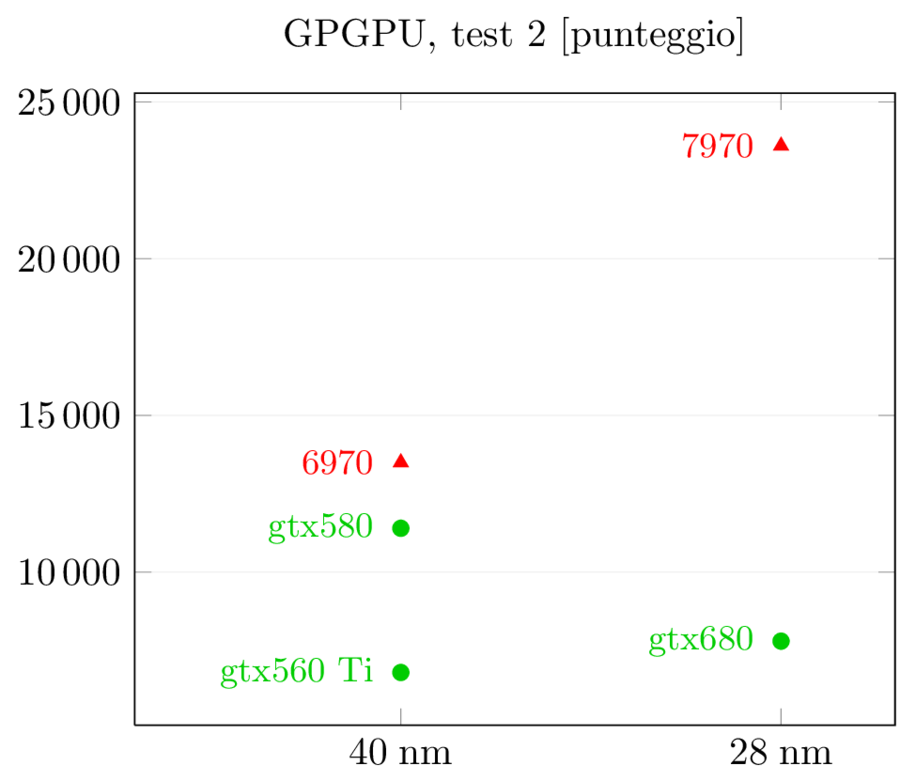
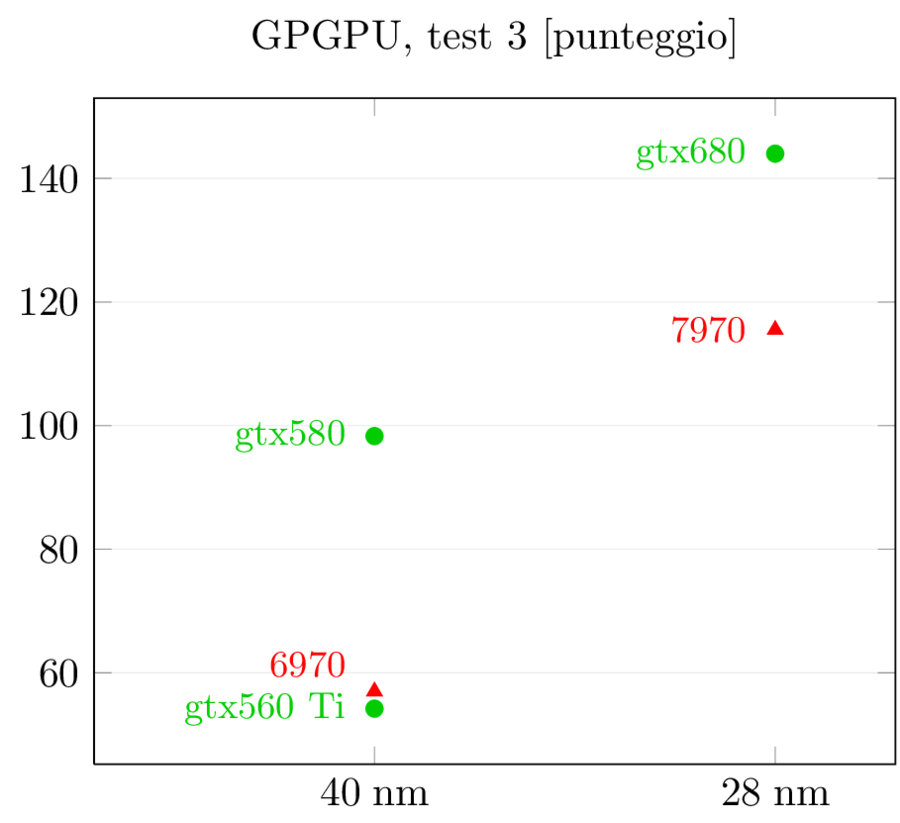
Per quel che riguarda le prestazioni, questi sono i risultati di Anandtech:
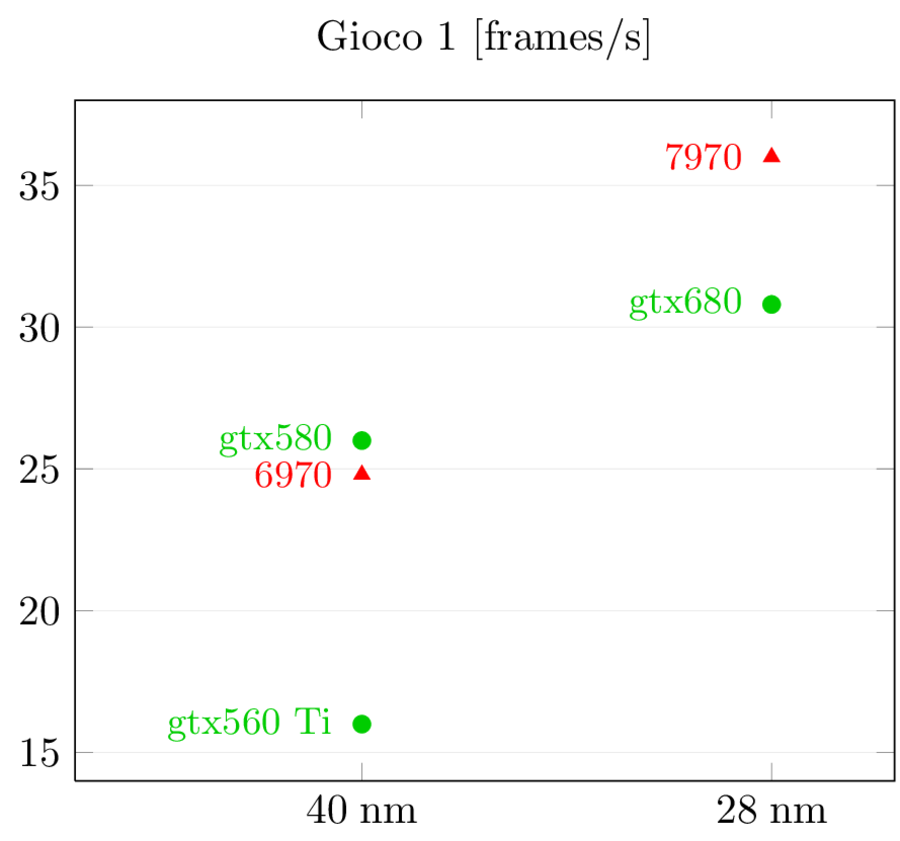
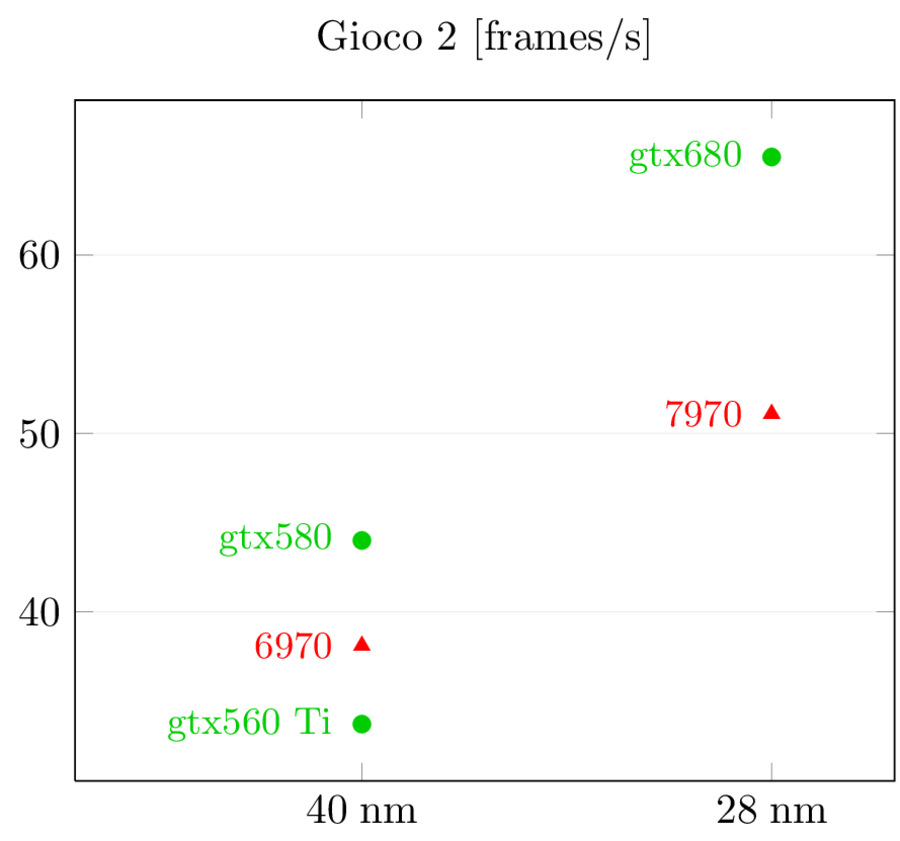
In Crysis, AMD inverte la situazione precedente, passando da un lieve svantaggio ad un vantaggio sostanzioso. In Battlefield 3, invece, NVidia mantiene la superiorità e anzi allunga. Evidentemente, le diverse architetture si adattano meglio a diversi tipi di giochi ed è difficile capire perchè senza un’analisi dettagliata dell’architettura e dell’interazione tra hardware e software, che purtroppo non sono in grado di fare (anche perchè i dati più gustosi non sono pubblici).
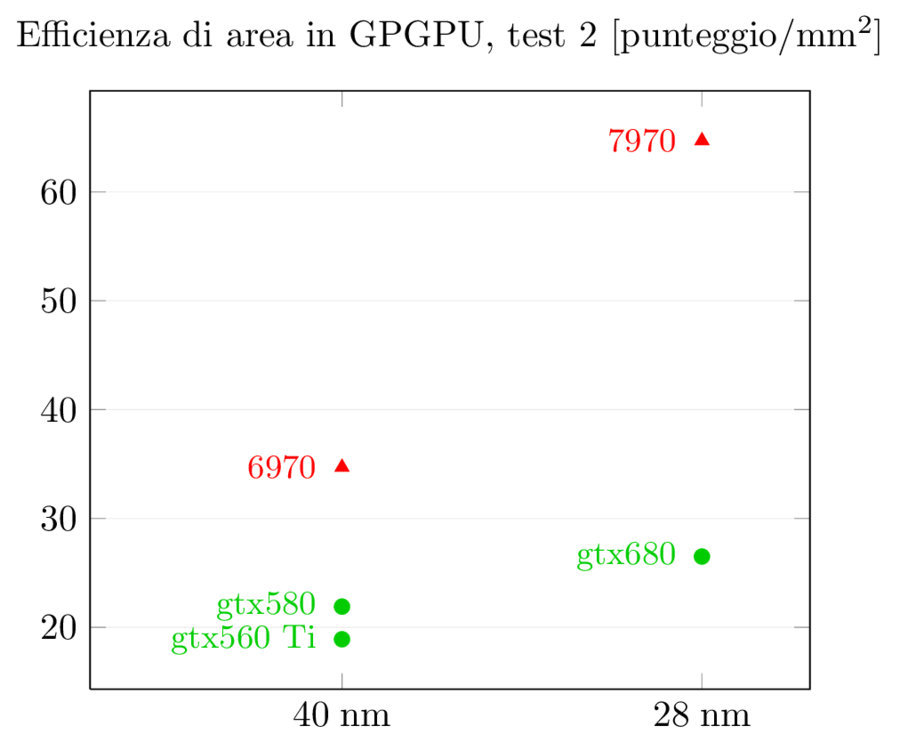
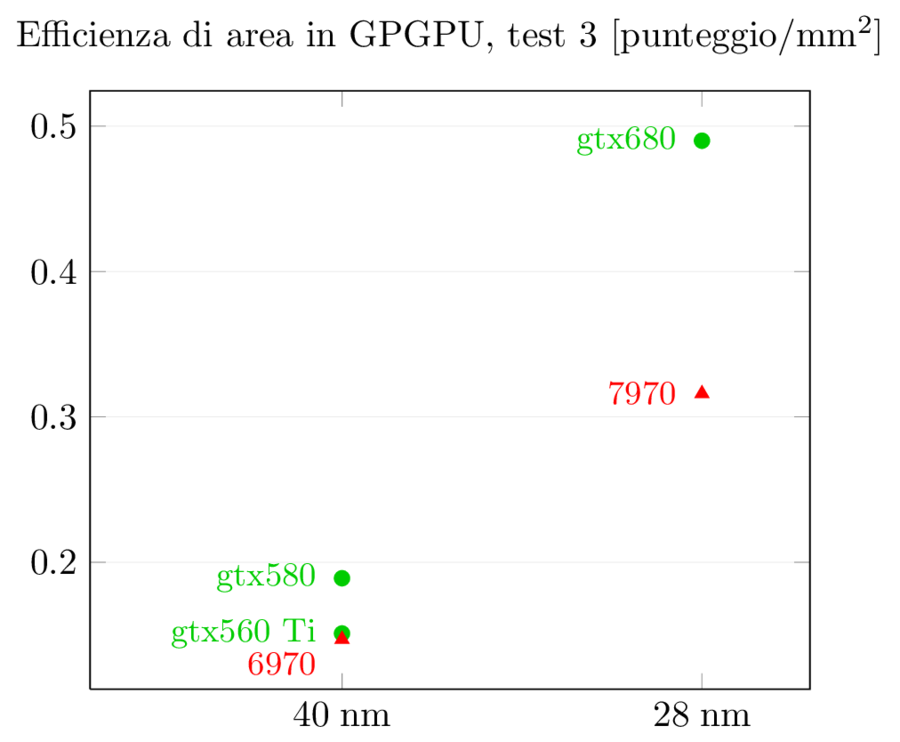
I risultati dei test GPGPU sono più interessanti: gtx580 aveva un netto vantaggio su 6970 nel primo e nel terzo test e un lieve svantaggio nel secondo. Con la nuova generazione i ruoli si invertono, come suggerito dai dati precedenti: 7970 si porta in vantaggio nel primo test, riduce lo svantaggio nel terzo mentre nel secondo allunga in modo imbarazzante, con prestazioni triple rispetto a gtx680. Viste le prestazioni generali, credo che in questo particolare test ci sia anche un effetto del software: visto che lo scheduler di Kepler è statico invece che dinamico come in gf114, l’ottimizzazione del compilatore è cruciale perchè le istruzioni e i warp non vengono più riordinati ed ottimizzati a runtime. Quello che penso sia successo è che il compilatore non sia ancora stato ottimizzato per questo tipo di task e stia ancora generando il codice ottimizzato per Fermi, che mal si adatta a Kepler. Mi aspetteri di vedere un miglioramento dei numeri in questo test nei prossimi mesi, ma fino a che punto è difficile dirlo.
Nello scontro tra 7970 e gtx680, ora è l’architettura di AMD quella ottimizzata per il GPGPU: gtx680 ha addirittura perso prestazioni rispetto a 580 in due test su tre, mentre 7970 ha incrementato rispettivamente del 62%, 75% e 103% rispetto a 6970 a fronte di un aumento dei GLOPFS grezzi del solo 40% (e del 63% dei transistor): è evidente che quei transistor in più sono stati spesi in logica di controllo e non in ALU (di cui 6970 ne aveva già in abbondanza) al fine di aumentare l’efficienza dell’architettura. La scelta, in ambito GPGPU, ha sicuramente pagato.
D’altro canto, gtx680 non è il vero erede di gtx580 per quel che riguarda il GPGPU: gk104 non è il “chippone” da 500+ mm^2 e con tutta la potenza FP64, quindi la cosa non deve sorprendere più di tanto. Al pari di gf1x4, è il chip ottimizzato per i giochi. L’erede di gtx580 per il compute sarà gk110, di cui avremo maggiori notizia al prossimo GTC e che dovrebbe equipaggiare i sistemi Cray che compongono il nuovo supercomputer dell’Oak Ridge National Laboratory.
Efficienza dei chip
Dopo aver visto i numeri assoluti è interessante normalizzare questi valori all’area dei chip, qui in formato tabulare:


e qui come grafico:
![]()
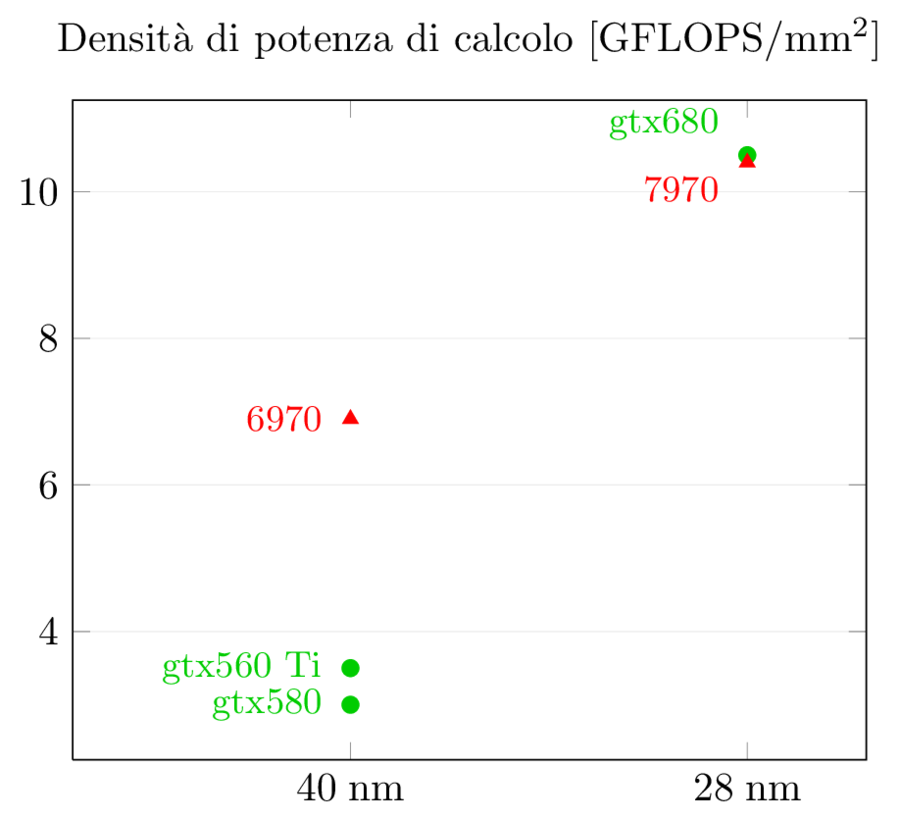
Passando da un nodo litografico al successivo ci si aspetta circa un raddoppio della densità di transistor per unità di area. NVidia ha poco più che raddoppiato (2.1x) mentre AMD si è fermata ad un incremento del 70%, facendosi così raggiungere. Considerando che certe parti di logica come le cache e le ALU hanno densità maggiore della logica di controllo, questo risultato è facilmente spiegato dall’analisi precedente su come le due compagnie hanno deciso di spendere i transistor.
Il risultato per la densità di GFLOPS per area è ancora più eclatante: mentre AMD era molto più efficiente nell’impaccare GFLOPS per mm^2 nella precedente generazione grazie all’architettura VLIW (6970 ha una densità doppia rispetto a gtx580!), NVidia riesce a raggiungere AMD nella nuova generazione, con un enorme aumento di 3.5x nella sua capacità di impaccare ALU (grazie anche, come visto sopra, alla semplificazione dello scheduler e alla riduzione di FP64, visto che questi numeri si riferiscono a FP32; ma è evidente il grosso lavoro che NVidia ha messo nel riarchitettare i suoi CUDA core per massimizzare l’efficienza).
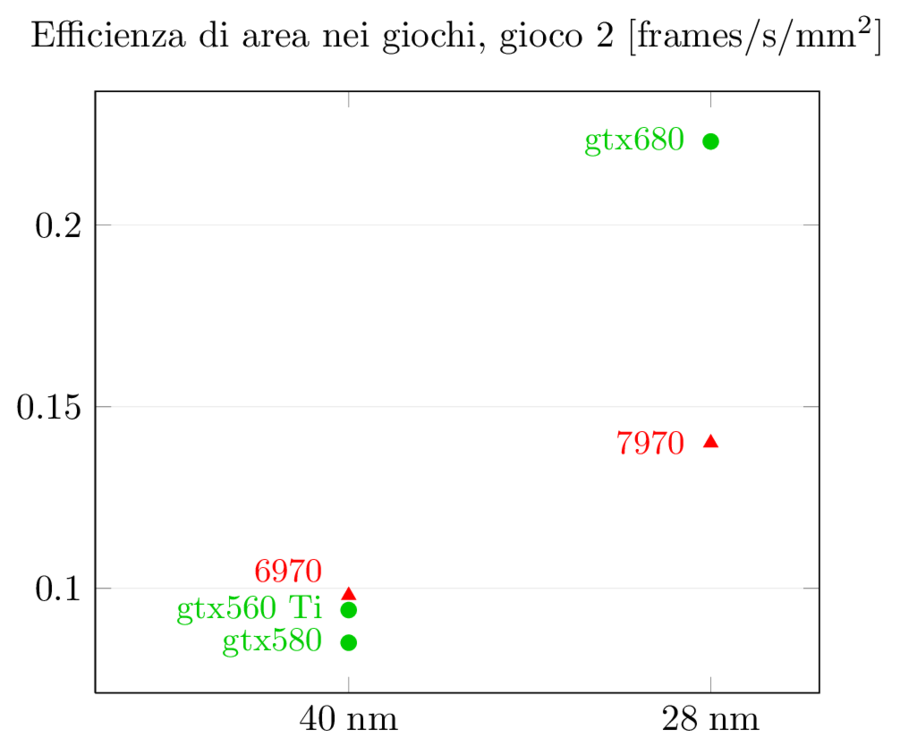
Possiamo fare la stessa normalizzazione per le prestazioni:
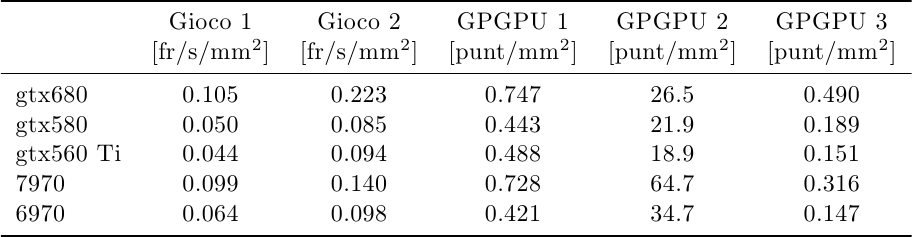

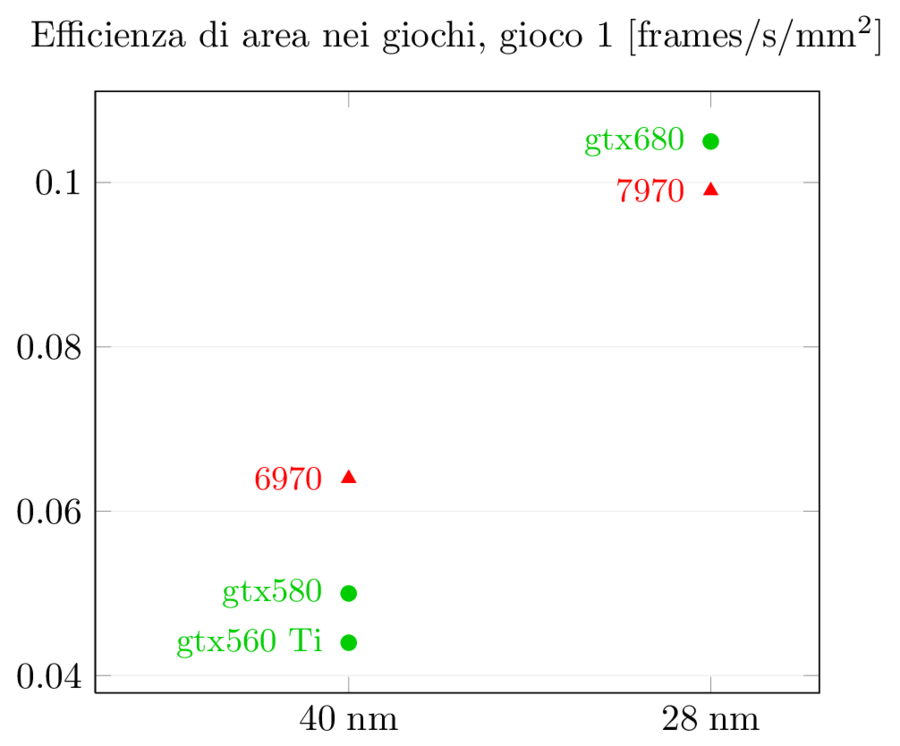
 Mentre nelle prestazioni pure AMD ed NVidia si alternavano, nelle prestazioni per mm^2 vediamo un trend netto: 6970 era più efficiente di 580 in entrambi i giochi, grazie al VLIW, mentre ora è 680 ad essere più efficiente di 7970 in entrambi i giochi. L’effetto della diversa organizzazione dell’hardware è evidente: 680 ha aumentato di 2.1x e 2.6x rispettivamente su 580, mentre 7970 si ferma a circa 1.5x su 6970.
Mentre nelle prestazioni pure AMD ed NVidia si alternavano, nelle prestazioni per mm^2 vediamo un trend netto: 6970 era più efficiente di 580 in entrambi i giochi, grazie al VLIW, mentre ora è 680 ad essere più efficiente di 7970 in entrambi i giochi. L’effetto della diversa organizzazione dell’hardware è evidente: 680 ha aumentato di 2.1x e 2.6x rispettivamente su 580, mentre 7970 si ferma a circa 1.5x su 6970.
La situazione per GPGPU, come visto prima, è diversa, ma è interessante notare come le prestazioni per area di gtx680 non sono così male: mentre in prestazioni assolute gtx680 viene schiacciata da 7970, in prestazioni per mm^2 gtx680 ha un lieve vantaggio nel primo test, un sostanziale vantaggio nel terzo test, e un enorme svantaggio secondo test (di nuovo, qui si sente l’effetto del software non ottimizzato). Per quel che riguarda l’incremento rispetto alla serie precedente, entrambi i chip aumentano del 70% nel primo test e più che raddoppiano nel terzo test, mentre il secondo registra il solito dominio di 7970.
Conclusioni
Questa nuova generazione di chip a 28nm è estremamente interessante perché mostra bene quali sono le strategie di AMD e NVidia:
- AMD aveva un’architettura VLIW estremamente efficiente nel gaming ma poco adatta al compute; con la nuova architettura ha invertito completamente i punti di forza e debolezza, sacrificando un po’ di efficienza e prestazioni assolute nei giochi per costruire un chip molto potente ed efficiente nel GPGPU. Questa è una scelta più che comprensibile: AMD si trova nella posizione unica di avere delle CPU x86 potenti e delle GPU altrettanto potenti (Intel ha delle CPU più potenti ma non ha GPU all’altezza e il suo progetto Larrabee/Knights Corner deve ancora mostrare di che cosa è capace, mentre NVidia ancora non ha una sua CPU abbastanza potente da affiancare alle sue GPU), e costruire un chip eterogeneo con una GPU potente sia nei giochi (per il mercato desktop) che nel GPGPU (per il mercato server/HPC) può portare ricchi frutti nei prossimi anni (il progetto Heterogenous Systems Architecture, precedentemente noto come Fusion)
- NVidia con Fermi aveva costruito un chip estremamente potente sia nei giochi che nel compute, a spese di efficienza ed area. Questo è un prezzo che non ci si può più permettere, dal momento che il costo del silicio continua a salire e che i chip sono ormai quasi sempre limitati dalla potenza dissipata. Con Kepler, NVidia ha cambiato direzione, dalla potenza pura all’efficienza, in modo da costruire chip più piccoli ed economici e poter in futuro integrare la linea GPU desktop all’interno della linea Tegra, per sfruttare i quasi 20 anni di esperienza nel campo delle GPU all’interno di quel mondo mobile che è in ascesa esponenziale e costruire così un SoC con prestazioni grafiche inarrivabili dalla concorrenza (specialmente per lo stack software, dove NVidia ha decenni di esperienza nello scrivere compilatori e driver per DirectX e OpenGL, al contrario di Qualcomm e Texas Instruments)
Nel prossimo articolo analizzerò i consumi dei chip e le loro efficienze energetiche; e quando gk110 uscirà sul mercato aggiungerò i suoi dati a quelli di gtx680 e 7970, per vedere come il nuovo “chippone” si piazza rispetto al resto, soprattutto per il GPGPU.







