Negli scorsi articoli abbiamo visto alcune tecniche utilizzate dai processori moderni per predire la direzione dei salti. Siamo partiti con le tecniche più vecchie e semplici e poi abbiamo visto predittori più sofisticati e predittori ibridi, che possono combinare predittori diversi per ottenere risultati ancora migliori.
Predire la direzione dei salti è però solo uno dei problemi che è necessario risolvere: bisogna anche predire il bersaglio dei salti presi e bisogna costruire tutti questi meccanismi in modo da interagire in modo efficiente con la cache e in modo da fornire più istruzioni per ogni ciclo di clock (dato che stiamo sempre parlando di processori superscalari).
Ci sono due casi in cui è necessario predire il bersaglio di salto: per i salti condizionali predetti presi e per i salti non condizionati. Può a prima vista sembrare strano che si debba “predire” qualcosa di un salto non condizionato (dato che è sempre preso), ma bisogna ricordare che la predizione avviene i testa alla pipeline, nello stadio di fetch, quando l’istruzione non è ancora stata nemmeno decodificata!
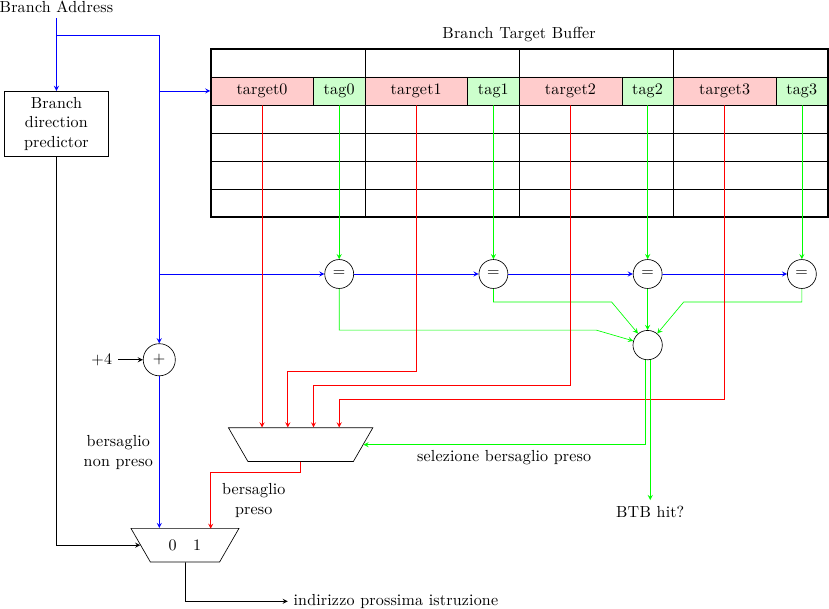
Branch Target Buffer
Per predire il bersaglio del salto si usa in genere una struttura simile ad una cache (chiamata Branch Target Buffer o Branch Target Address Cache) in cui viene salvato l’ultimo bersaglio visto per quel salto. Durante la predizione di salto, parallelamente alla generazione della predizione preso/non preso, si accede alla BTB usando il Program Counter corrente; la BTB ha in genere delle tag (parziali) per distinguere i diversi PC e può essere set-associativa.
Se il predittore di direzione predice non preso il bersaglio è semplicemente la prossima istruzione (per una macchina RISC sarà l’indirizzo corrente più la dimensione dell’istruzione, 4 byte nell’esempio in figura); altrimenti, se il salto è predetto preso e c’è cache hit nella BTB, allora il valore restituito dalla BTB viene usato come prossimo Program Counter.
Se invece il salto è predetto preso ma non c’è hit nella BTB, ci sono un paio di approcci possibili:
- il processore stalla fino a che il bersaglio non è noto: questo può prendere pochi cicli nel caso il bersaglio di salto sia relativo al PC (è necessario attendere il fetch e il decode dell’istruzione e quindi aggiungere il valore al PC) o più a lungo se il bersaglio va calcolato a partire da valori nei registri (in questo caso è necessario attendere il risultato dall’unità di esecuzione dei branch)
- scartare la predizione e continuare a fare fetch dalla prossima istruzione, come se il salto fosse non preso
La prima soluzione è più conservativa e risparmia energia, in quanto non si esegue nulla fino a che il bersaglio non è noto (a quel punto non si tratta più di una speculazione, il risultato è al 100% corretto perchè il salto è stato effettivamente eseguito). La seconda soluzione è più aggressiva e può dare prestazioni lievemente migliori, nel caso il predittore si fosse sbagliato e il salto fosse effettivamente non preso (aiuta anche nel caso di phantom branch, come vedremo in seguito); costa però più energia, perchè se il predittore aveva indovinato (e cioè il salto era preso) il processore ha eseguito istruzioni che devono essere cancellate (sprecando così energia).
Inoltre, ci sono diverse strategie riguardo quale informazione mantenere nella BTB. Un approccio semplice potrebbe essere quello di registrare nella BTB tutti i bersagli di tutti i salti incontrati. Un approccio migliore può essere quello di registrare solo i salti presi, dato che se un salto è non preso il bersaglio è facile da calcolare (è la prossima istruzione); questo risparmia spazio nella BTB e diminuisce la probabilità di interferenza tra salti, migliorando le prestazioni; per contro, prima di registrare un bersaglio nella BTB è in questo caso necessario attendere che il salto sia stato risolto completamente (in bersaglio e in direzione) per decidere se l’informazione va registrata o meno.
Un altro fattore molto importante di cui tenere conto è che in un processore moderno, che opera ad alta frequenza, la cache istruzioni non riesce a rispondere in un singolo ciclo di clock: anch’essa è pipelinizzata e ha un throughput di una cache line per ciclo di clock, ma la latenza è maggiore di un ciclo. Questo può creare uno strano effetto per cui il predittore predice un salto… che non esiste! Per esempio, supponiamo che la cache abbia un tempo di risposta di due cicli di clock:
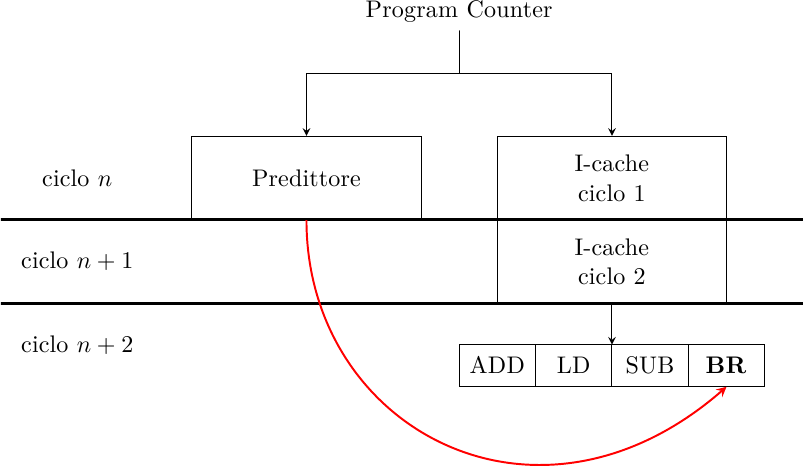
Al ciclo n il PC corrente viene fornito al predittore, che predice un salto preso; contemporaneamente comincia l’accesso alla cache istruzioni. Alla fine del ciclo n la BTB ha fornito il bersaglio per il salto evidenziato; questo valore viene caricato nel PC ed è il valore che verrà usato al ciclo n+1 per caricare la prossima istruzione. Ma al ciclo n+1 la cache non ha ancora risposto! E’ solo al ciclo successivo che la cache fornisce l’istruzione puntata dal PC al ciclo n: il salto è stato eseguito in modo speculativo prima ancora che ne venisse completato il fetch!
Questo significa che, quando il predittore si sbaglia, esso potrebbe fornire il risultato di salto per un salto che non c’è:
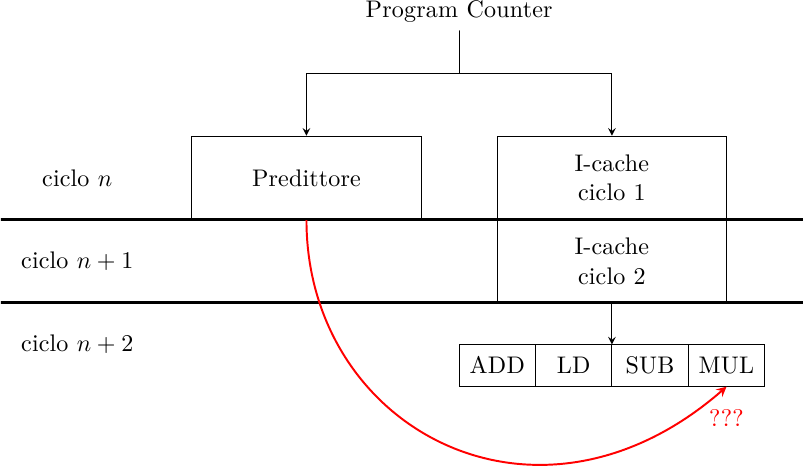
Solo al ciclo n+2 la cache restituisce il gruppo di fetch e si scopre che non c’è alcun salto. L’azione errata del predittore va cancellata: nella pipeline viene inserita una bolla e il PC viene ricaricato al valore corretto, perdendo così un ciclo di clock. Questo salto predetto ma inesistente è chiamato phantom branch.
Se il gruppo di fetch non ha salti, il prossimo Program Counter è il blocco di istruzioni successivo, che è equivalente ad una predizione di salto non preso. Se, come spiegato sopra, nella BTB vengono caricati solo i bersagli dei salti presi, ci sarà sempre un BTB miss quando un gruppo di fetch non contiene salti, mitigando il problema dei phantom branch.
Un’ultima cosa da notare è che gli indirizzi sono “larghi” (32 e ora anche 64 bit): questo occupa un sacco di spazio nelle tag della BTB. Per ridurre questo problema si può usare una tag parziale, cioè solo una parte dell’indirizzo di salto viene registrato nella tag. Questo riduce la dimensione della BTB, rendendola più veloce, ma crea la possibilità di avere aliasing (come visto qui). L’aliasing non inficia il corretto funzionamento del processore, rende solo meno preciso il predittore. Un effetto collaterale è il ritorno dei phantom branch: un gruppo di fetch senza branch potrebbe comunque avere uno hit nella BTB perchè, a causa della tag parziale, il PC corrente mappa sulla tag errata. Tuttavia, se il tasso di falsi hit è basso questo non è un grosso problema.
Return Address Stack
Uno dei casi più comuni di salto è la chiamata a funzione: salto nella funzione e salto (ritorno) dalla funzione. Il bersaglio di salto nella funzione è facile da predire perchè è sempre lo stesso; il ritorno dalla funzione è più difficile perchè la stessa funzione può essere chiamata da molti punti del programma (ad esempio, ogni volta che chiamiamo “printf” saltiamo nello stesso punto, ma quando usciamo da “printf” possiamo tornare ad un’infinità di punti diversi, tutti i punti in cui abbiamo chiamato “printf”).
Un modo efficace di risolvere questo problema e fornire una predizione accurata ad un salto che può cambiare bersaglio ad ogni esecuzione è il Return Address Stack: uno stack di indirizzi di ritorno delle subroutine. Ogni volta che si esegue il salto ad una subroutine l’indirizzo di ritorno viene messo su questo stack; ogni volta che si incontra un ritorno da funzione si esegue il pop da questo stack, ottenendo quindi il bersaglio esatto. L’uso di uno stack invece che un singolo registro permette di gestire chiamate di funzioni annidate.
Il RAS è quindi un predittore particolare che predice solamente i ritorni da funzione; esso integra la BTB e gli altri meccanismi di predizione, ma è necessario avere della circuiteria in grado di determinare esattamente quando accettare il valore fornito dal RAS e quando scartarlo. Inolre, dato che il RAS ha una capacità limitata alla dimensione massima dello stack (ad esempio 16 nel Pentium-4), è possibile che esso fallisca quando il numero di funzioni annidate è superiore alla dimensione dello stack; in questo caso si avranno predizioni errate, con conseguente scadimento delle prestazioni.
Conclusioni
In questo articolo abbiamo visto come predire il bersaglio di salto, che è la vera quantità che ci interessa calcolare per far proseguire il programma senza stalli.
Restano da vedere ancora un paio di cose: come eseguire predizioni a “larga banda” (cioè ottenere più istruzioni per ciclo di clock, necessarie ad alimentare pipeline superscalari) e ad “alta frequenza” (cioè ottenere una predizione ad ogni ciclo di clock anche quando cache e predittori occupano più stadi di pipeline).







