
 I database sono uno dei pilastri dell’informatica.
I database sono uno dei pilastri dell’informatica.
C’è chi li ama, chi li odia, chi li considera un repository che non deve condizionare l’architettura del software che li utilizza (come il sottoscritto) e chi li vede come il vero contributo dell’informatica al mondo. Fatto sta che i database, relazionali o non, sono lo strumento più utilizzato per conservare i dati i modo strutturale e consentirne la loro condivisione.
Cerchiamo di approfondire la loro origine e gli attori che più hanno influenzato lo sviluppo di questa tipologia di sistemi software.
Il nostro viaggio inizia intorno al 1964, quando viene coniato il termine “data base”. Come molte delle innovazioni nel settore della tecnologia, l’idea di questo nuovo strumento nasce all’interno degli ambienti militari statunitensi e denota una collezione di dati condivisa dagli utilizzatori finali dei terminali.
Un importante contributo all’analisi di quelli che sono stati i primi step evolutivi ci viene dall’ottimo articolo Data Base Technology, scritto da W. C. McGee dell’IBM Data Processing Division Laboratory, pubblicato nel “lontano” 1981. McGee evidenzia come una delle sfide maggiori fosse quella di trovare il modo di creare una “relazione” tra i dati, inizialmente provenienti da schede perforate e, successivamente, da flat file, ovvero file non strutturati. Inoltre le strutture erano sostanzialmente hardware-oriented così come le procedure utilizzate per la loro interrogazione.
Il primo data model è rappresentata dal flat data model, in cui i dati sono rappresentati da una semplice tabella (matrice), riga – colonna. Si tratta di un modello semplice che non permette il collegamento diretto tra le varie fonti.

Flat Model
Successivamente compaiono i database gerarchici (hierarchical model), che sostanzialmente disegnano una struttura dati ad albero, efficiente ma non adatta a gestire relazioni tra nodi che distando tra loro più di un livello, e i network database (network model) la cui struttura è assimilabile a quella di un grafo.
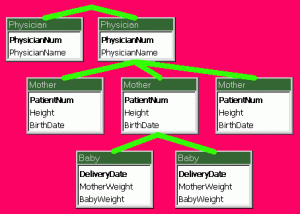
Esempio di database gerarchico
Nella seconda metà degli anni ’60, alcune società di prim’ordine come Honeywell Corp. e General Electric Corp. avviano lo sviluppo di proprie soluzioni basate sul modello a rete (network). In particolare, presso la General Electric è Charles Bachmann, ritenuto uno dei pionieri dei database, a progettare e guidare lo sviluppo di IDS (Integrated Data Store, network model), il primo DBMS.
Nel 1966 IBM avvia lo sviluppo dell’IMS (Information Management System), pensato specificamente per supportare il programma spaziale APOLLO e sviluppato per il mitico System/360.
 Non solo i Big del mondo elettronico si accorgono dell’importanza e delle potenzialità di questi nuovi sistemi. Infatti l’ascesa dei database fu ben cavalcata da Cincom, sostanzialmente la prima società a realizzare un DB non vincolato ad hardware specifico, ovvero TOTAL DBMS.
Non solo i Big del mondo elettronico si accorgono dell’importanza e delle potenzialità di questi nuovi sistemi. Infatti l’ascesa dei database fu ben cavalcata da Cincom, sostanzialmente la prima società a realizzare un DB non vincolato ad hardware specifico, ovvero TOTAL DBMS.
Resta il fatto che i due modelli appena descritti erano fortemente legati all’hardware per cui venivano realizzati, e presto comincia a palesarsi la necessità di avere un nuova organizzazione dei dati che ne superasse i limiti, così come McGee afferma in un passaggio della propria analisi:
“In the mid-1960s, a number of investigators began to grow dissatisfied with the hardware orientation of then extant data structuring methods, and in particular with the manner in which pointers and similar devices for implementing entity associations were being exposed to the users.”
Nel 1969 arriva la risposta: applicare un modello matematico alla relazione tra i dati. A proporlo sono alcuni ricercatori IBM, guidati da Edgar Frank “Ted” Codd, che rendono pubblica la loro teoria su un nuovo modo di organizzare i dati, presentandolo sotto il cappello di “relational model”. Sostanzialmente, si tratta di una modellazione basata su regole matematiche ben precise in cui a farla da padrone sono la coppia Entità-Relazione.
“The key new concepts in the entity set method were the simplicity of the structures it provided and the use of entity identifiers (rather than pointers or hardware-dictated structures)… In the late 1960s, [IBM’s] E.F. Codd noted that an entity set could be viewed as a mathematical relation on a set of domains D1, D2,. . .,Dn, where each domain corresponds to a different property of the entity set.”

Edgar Frank (Ted) Codd
La teoria di Codd è rivoluzionaria perché permette di gestire dati in una maniera assolutamente impensabile fino ad allora, ma la tecnologia non è ancora pronta per fornire sistemi sufficientemente potenti da metterla in pratica. IBM impiega quasi 5 anni per sviluppare un primo prototipo di database relazionale, definendo, nel frattempo, il nuovo linguaggio di interrogazione SQL (Structured Query Language).
Nel 1970 Codd pubblica A Relational Model of Data for Large Shared Data Banks, dove afferma:
“It provides a means of describing data with its natural structure only–that is, without superimposing any additional structure for machine representation purposes. Accordingly, it provides a basis for a high level data language which will yield maximal independence between programs on the one hand and machine representation on the other.”(Codd 1970)
Il primo sistema di tipo relazionale più essere considerato INGRES dell’Università di Berkeley , ma, in realtà, la prima metà degli anni ’70 fu puramente di ricerca. IBM promuove il progetto sperimentale System R (poi SQL/DS ed infine DB2) portando allo sviluppo di concetti come le viste (1975), le policy di security (1975) e le transazioni (1976), ma non capitalizza da subito il frutto delle ricerche di Codd e soci, perché ritiene IMS strategico e non intende promuovere lo sviluppo di un DBMS antagonista.
Ad approfittarne è la piccola startup Software Development Laboratories (Redwood Shores, California), guidata da Larry Allison e dal co-fondatore Robert Miner. Allison aveva avuto l’occasione di studiare approfonditamente le ricerche del team di Codd e riesce a coglierne da subito le grandi potenzialità commerciali. La società cambia presto nome in Relational Software Inc., accettando la sfida di produrre il primo database relazionale commerciale e trovando nella CIA il suo più importante finanziatore. Alcuni anni dopo Relational Software Inc. diventerà Oracle Corporation..

Larry Ellison
Chiudiamo questo primo post segnalando l’interessante articolo scritto nel 1976 da Peter Chen dal titolo: “The Entity-Relationship Model – Towards a Unified View of Data” che riassume lo stato dell’arte del modello relazionale fino a quel periodo.







