In-order o out-of-order, superscalare o meno, il viaggio delle istruzioni all’interno di qualsiasi CPU comincia nello stesso modo: il fetch (cioè il prelevamento) delle istruzioni dalla memoria, e più precisamente dalla I-cache di primo livello.
Il numero di istruzioni che la CPU è in grado di caricare per ogni ciclo di clock è chiamata fetch bandwidth e fissa il limite massimo delle prestazioni del processore: è evidente infatti che la CPU non può eseguire più istruzioni di quelle che carica dalla memoria. Una macchina superscalare capace di eseguire s istruzioni per ciclo di clock deve quindi anche prelevare s istruzioni dalla I-cache per ciclo di clock. Lo scopo dello stadio di fetch è quindi quello di fornire la massima fetch bandwidth possibile, per alimentare tutte quelle pipeline parallele.
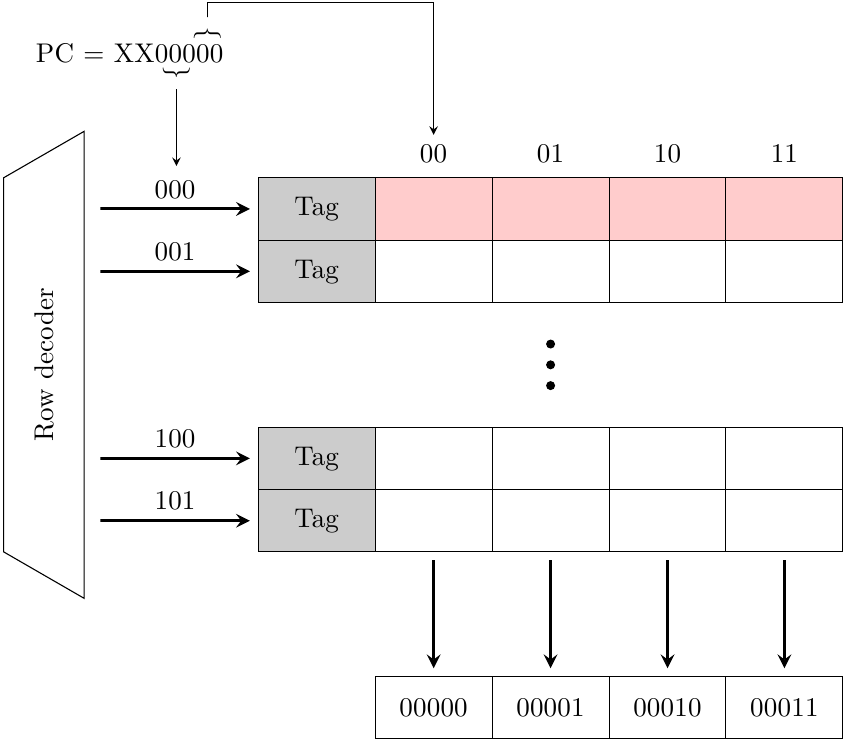
L’insieme delle s istruzioni caricate in un ciclo di clock sono dette fetch group e idealmente occupano una sola linea fisica nella cache:
In figura vediamo un modellino di una cache con istruzioni tutte della stessa dimensione, una cache line di 4 istruzioni e un fetch group anche di 4 istruzioni, perfettamente allineato con la cache line. In questo esempio ideale il processore può procedere a caricare 4 istruzioni ogni ciclo di clock, alla massima velocità.
Purtroppo questo è ben lontano dalla realtà. Ci sono 3 problemi principali che limitano la banda di fetch:
- I-cache miss: quando le istruzioni necessarie al programma non sono nella cache L1 il processore deve cercarle nel resto della gerarchia di memoria (cache L2, L3, memoria centrale, ecc.); nel frattempo la CPU rimane senza istruzioni da eseguire e deve stallare
- branch e jump: se nel fetch group esistono una o più istruzioni che modificano il flusso del programma, il processore deve scartare le istruzioni del gruppo che non vengono utilizzate e capire da dove riprendere il flusso di esecuzione
- disallineamento del gruppo di fetch: il gruppo di fetch non è necessariamente allineato alle cache line, perchè branch e jump possono far saltare il flusso del programma ad una istruzione qualunque; questo può ridurre la dimensione del gruppo di fetch, come mostrato in figura:
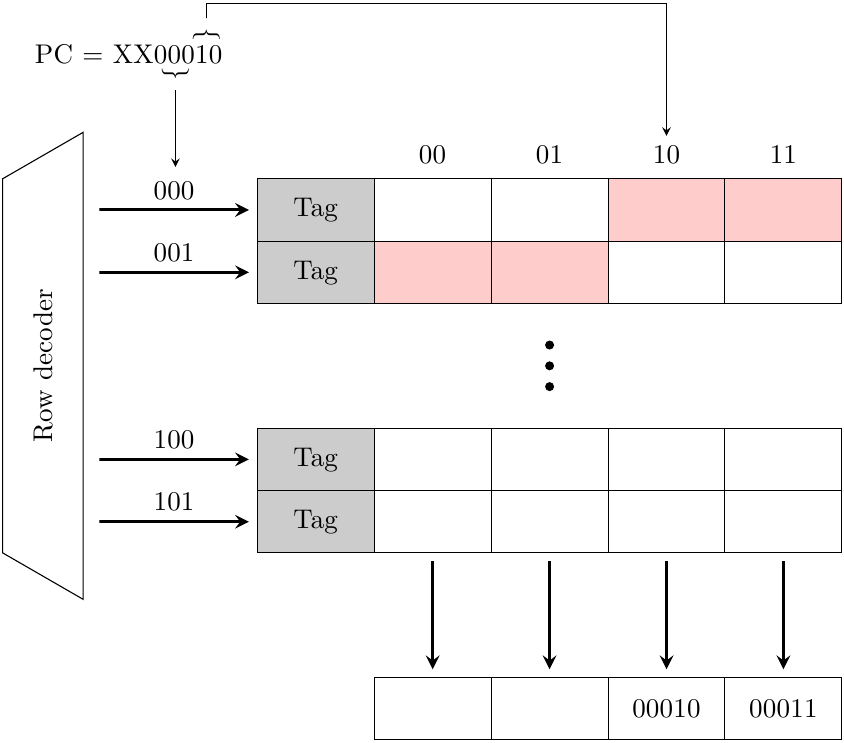
In questo esempio il fetch group si estende su due cache line, ma se la I-cache può accedere ad una sola cache line alla volta allora puo’ restituire solo 2 istruzioni, e la fetch bandwidth effettiva viene ridotta.
Branch e jump
La modifica del flusso del programma è uno dei peggiori problemi che limitano le prestazioni del processore, in quanto:
- portano al sottoutilizzo del gruppo di fetch, perchè le istruzioni che seguono un salto preso sono inutili (quindi non solo riducono la fetch bandwidth, ma causano anche lo spreco dell’energia che è stata necessaria per prelevare quelle istruzioni inutili)
- interrompono il flusso sequenziale delle istruzioni, costringendo il processore a capire dove andare a prendere le prossime
- riducono il numero di istruzioni medie in-flight nella CPU, riducendo quindi l’ILP (Instruction Level Parallelism) che la CPU può sfruttare
Per rendere le cose ancora peggiori, i salti vengono risolti verso la fine della pipeline, ma agiscono sull’inizio della pipeline: i salti modificano il Program Counter, che dice allo stadio di fetch dove accedere nella I-cache, e lo stadio di fetch è il primo in testa alla pipeline. Secondo quello che abbiamo visto qui (seconda e terza figura) questo è il caso peggiore possibile: il primo stadio deve stallare fino a che il branch non è arrivato (e risolto) all’ultimo stadio, cioè il massimo numero di stalli possibile. E in un processore supescalare, ogni ciclo di clock di stallo si traduce in s slot sprecati (s istruzioni avrebbero potuto essere eseguite nelle s pipeline parallele, e non lo sono state).
Per fare un esempio molto semplificato, consideriamo un processore con una ventina di stadi di pipeline (un numero ragionevole per i processori moderni); supponiamo inoltre che ci sia un branch ogni 5 istruzioni (anche questo è un valore medio tipico per una larga classe di programmi) e supponiamo che il processore sia molto largo (moltissime pipeline parallele). Date le molte pipeline parallele ci aspetteremmo prestazioni molto elevate; ma a causa dei salti, il processore può in effetti eseguire solo le 5 istruzioni tra un branch e l’altro, e poi deve aspettare i 20 cicli di clock che il branch ci mette dal suo fetch al suo completamento. Di fatto, questa ipotetica CPU sta eseguendo una media di 5/20 = 0.25 istruzioni per ciclo di clock (e senza tenere conto dei cache miss)! Questo è parecchio peggio di una pipeline in-order, che è più piccola, più economica, più facile da progettare e che consuma meno!
Da questo esempio è chiaro che non sarà mai possibile costruire un processore superscalare veramente funzionante fino a che non risolveremo questo problema, e cioè come fare a continuare a prelevare ed eseguire istruzioni che seguono un branch prima ancora di aver risolto il branch.
La risposta esiste e dovrebbe essere nota a tutti (almeno di nome): si chiama branch prediction e sfrutta il fatto che la maggior parte dei salti è predicibile perchè si comporta secondo dei semplici schemi ripetitivi. È possibile usare il comportamento passato di un salto (preso/non preso) per predire il suo comportamento futuro, con una precisione notevolissima (anche superiore al 98% in certi programmi).
La branch prediction è un argomento vasto, con molte tecniche sofisticate che sono state sviluppate nel corso degli ultimi decenni. Per questo non ne parlerò oltre qui, ma dedicherò a queste tecniche tutto il prossimo articolo.
Disallineamento del gruppo di fetch
Come visto nella figura precedente, nel caso il Program Counter non punti all’inizio della cache line potrebbe non essere possibile prelevare il massimo numero di istruzioni (nell’esempio, solo 2 invece che 4). Possiamo cercare di risolvere il problema sia con soluzioni software che hardware.
Soluzione software
Una tecnica statica, utilizzata a compile time, è quella di dare al compilatore informazioni sulla struttura della I-cache, in particolare il modo di indirizzamento e la dimensione della cache line. Il compilatore può quindi allineare tutti i gruppi di fetch con le cache line in modo molto semplice: basta ad esempio mettere tutte le istruzioni che sono bersaglio di un salto in una locazione di memoria che, durante il runtime, verrà mappata all’inizio di una cache line. In questo modo lo scenario precedente (salto nel mezzo di una cache line) non può verificarsi.
Questa tecnica è semplice da implementare ma ha due svantaggi:
- il codice assembly è ottimizzato per una particolare struttura di cache: portare il codice su un diverso processore porterà ad una perdita di prestazioni; per mantenere sempre le prestazioni al massimo bisognerà ricompilare il codice per ogni processore con una diversa I-cache, che è una pessima idea
- per forzare l’allineamento dobbiamo inserire del padding, cioè dello spazio vuoto che serve solo a spostare le istruzioni nel posto voluto; questo aumenta la dimensione del codice e quindi il miss rate della I-cache, che peggiora le prestazioni
Soluzioni hardware
Visto che lo stadio di fetch è così strettamente connesso alla I-cache, possiamo cercare di risolvere il problema modificando l’architettura della cache.
Un’idea che potrebbe venire in mente è quella di aumentare la dimensione della cache line: se ad esempio quadruplicassimo la dimensione della cache line avremmo più probabilità di avere un fetch group di dimensione massima:
Per la precisione, avremmo una probabilità di 13/16 di avere un fetch group di dimensione 4, e 1/16 di avere un fetch group di dimensioni 3, 2 e 1. In media riusciremmo a caricare 13/16 * 4 + 1/16 * 3 + 1/16 * 2 + 1/16 * 1 = 3.625 istruzioni per ciclo di clock, abbastanza vicino al massimo teorico di 4.
Questo però può essere un problema a seconda di come è fisicamente costruita la cache. Se fossimo costretti ad accedere ad un’intera cache line alla volta, dovremmo prelevare sempre 16 istruzioni dalla cache per poi tenerne solo 4 (o meno) e scartare il resto, un evidente spreco di risorse (sia di energia necessaria per accedere la cache, che di dimensione del bus verso la I-cache che sarebbe 4 volte più grande di quel che serve).
Un’altra soluzione potrebbe essere quella di accedere a più cache line contemporaneamente: quella puntata dal Program Counter e la successiva. Questo è difficile per diversi motivi:
- per ogni cache line da accedere bisogna prima tradurre l’indirizzo virtuale nell’indirizzo fisico, poi accedere alla cache, recuperare la tag, controllare che sia giusta, e quindi recuperare i dati; accedere a due cache line contemporaneamente significa avere due porte di lettura sia per la I-cache che per la TLB (per la traduzione degli indirizzi)
- non è detto che la prossima cache linea sia contigua in memoria alla precedente (per un ripasso rimando a questo articolo di Yossarian, settima immagine); nel caso di una cache set-associativa, le istruzioni che seguono quelle di questa cache line potrebbero essere in una qualunque delle cache line del set successivo; in ogni caso, bisogna prima scoprire se le istruzioni successive sono presenti nella cache, e poi prelevarle
- le due cache line andranno “fuse” per tenere solo le istruzioni “buone” da ognuna (nella seconda immagine di questo articolo le istruzioni “buone” sono le ultime due della prima cache line e le prime due della seconda cache line); questo può essere fatto con un collapsing buffer, ma allunga il tempo necessario a ottenere le istruzioni, tempo che vorremmo invece tenere al minimo possibile: vogliamo avere le prossime istruzioni in fretta, prima che la pipeline si svuoti di quelle vecchie!
La soluzione è interessante, ma richiede una cache molto più sofisticata.
La soluzione dell’IBM RS/6000
Finora ho dato per scontato che la cache line si estenda su di un’unica linea fisica all’interno della cache, ma non deve essere per forza così. Ad esempio:
In questo caso la cache line contiene 8 istruzioni, ma la circuiteria interna della cache è organizzata in modo tale che queste 8 istruzioni si estendono su due linee fisiche (che hanno due diversi indirizzi di riga). Prelevare un’intera cache line prende ora due cicli di clock, uno per la prima linea e uno per la seconda. Questo però non è importante, perchè quello che conta è prelevare in un ciclo di clock l’intero fetch group, non l’intera cache line. Questo ci dà un grado di libertà che possiamo sfruttare nella progettazione della cache.
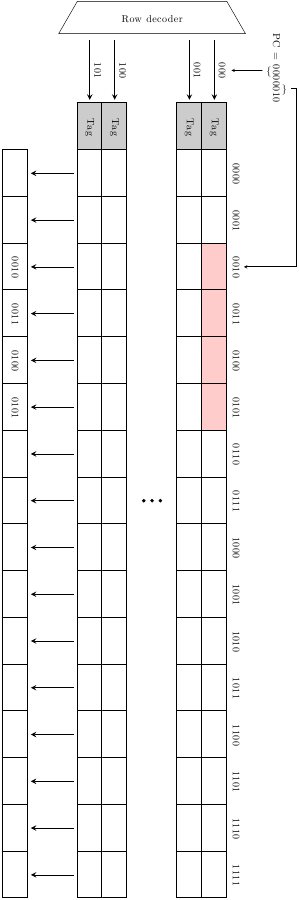
Una soluzione classica molto astuta è quella dell’IBM RS/6000, nato nel 1990, dove la I-cache è in grado di restituire 4 istruzioni per ciclo di clock anche se il fetch group si estende su diverse linee fisiche (a patto che non superi i limiti di una cache line). Questo processore aveva una I-cache set-associativa a 2 vie e 4 banchi, una cache line di 64 byte che si estende su 4 linee fisiche e un fetch group di 4 istruzioni di 4 byte l’una:
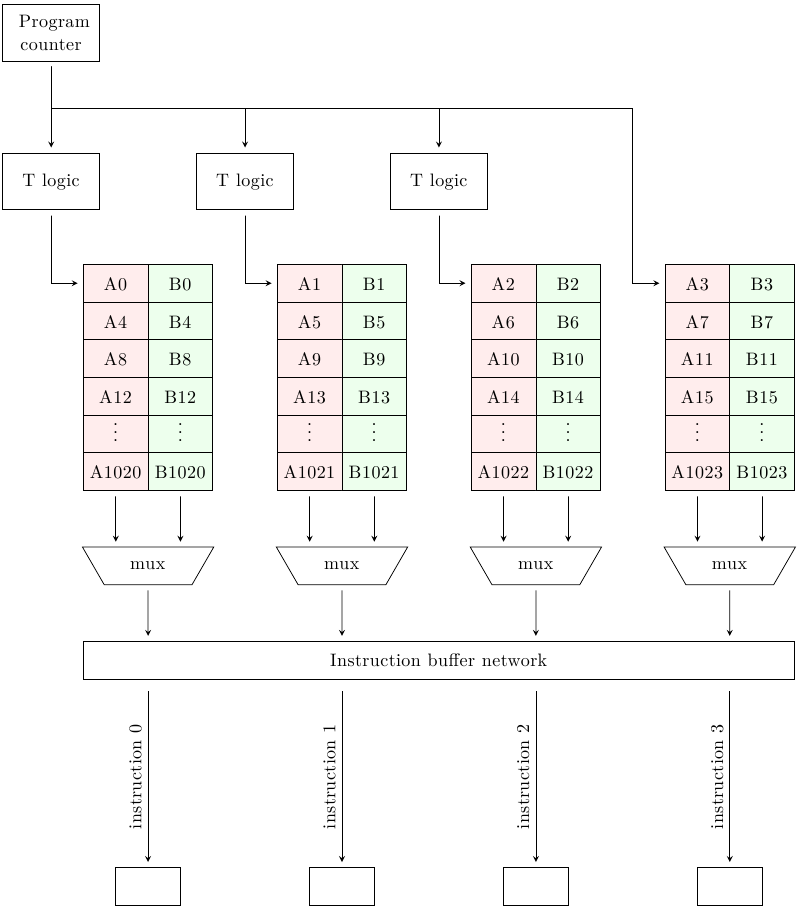
A e B si riferiscono alle 2 vie. Per ogni via, le 16 istruzioni (64 byte / 4 byte per istruzione) si estendono su 4 linee fisiche e si alternano sui 4 banchi. In figura è mostrata una cache line per ogni via (istruzioni da 0 a 15), cioè le 4 linee fisiche consecutive che condividono la stessa tag.
Il trucco che permette al sistema di funzionare è dato da quella che IBM chiamava T-logic e dall’instruction buffer network (di fatto un circuito che esegue l’operazione rotate left). Se il Program Counter punta ad una delle istruzioni del primo blocco (istruzioni 0, 4, 8, 12) allora 4 istruzioni consecutive possono essere prelevate usando lo stesso indirizzo di riga, una per blocco. Se invece punta ad una delle altre, allora il fetch group si estenderà su due righe consecutive: la T-logic di ogni blocco deciderà, dato il valore del PC, se quel blocco deve restituire l’istruzione alla riga del PC o quella alla riga successiva; inoltre, il rotatore riordina le istruzioni in modo che vengano consegnate in ordine allo stadio di fetch. Ad esempio, se il Program Counter punta all’istruzione A2, la cache risponde in questo modo:
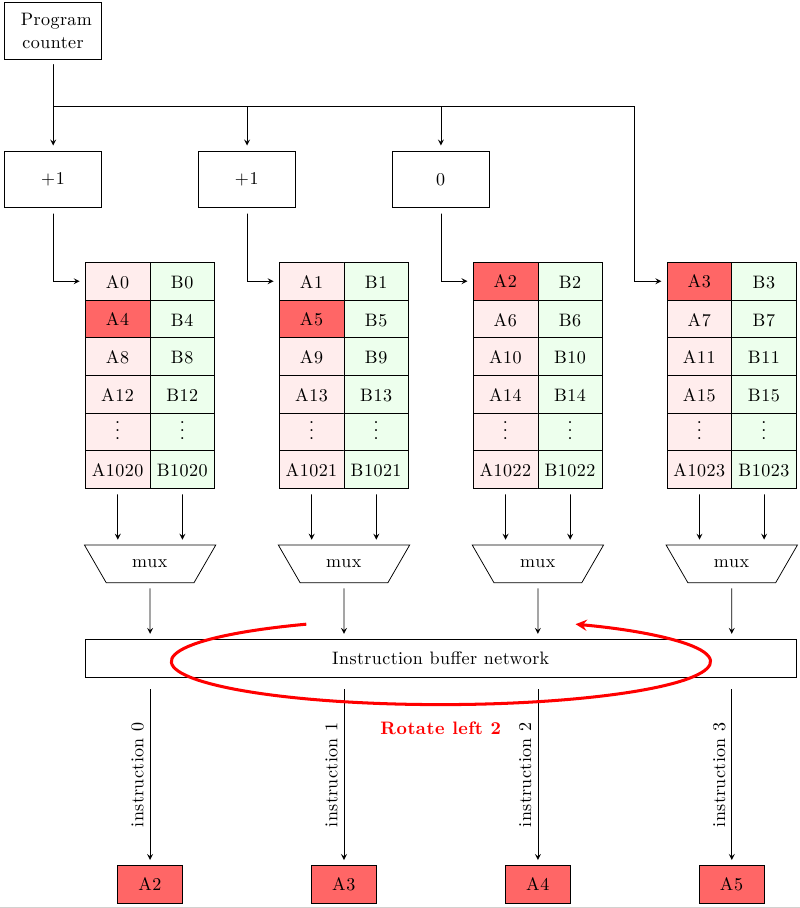
Questo funziona finchè il fetch group non supera i confini di una cache line, e quindi la fetch bandwidth media è lo stesso 3.625 calcolato prima.
Conclusioni
In questo articolo abbiamo cominciato a seguire le istruzioni nel loro viaggio nel processore. Abbiamo visto come il fetch delle istruzioni dalla memoria imponga il limite superiore alle prestazioni del sistema (perchè non si possono eseguire più istruzioni di quelle che si riesce a caricare), e come branch e disallineamenti nella cache limitino la velocità della macchina.
In tutti gli esempi ho supposto che le istruzioni abbiano tutte la stessa dimensione, tipico delle ISA RISC. Per una ISA CISC il discorso non cambia: comunque bisogna massimizzare la fetch bandwidth e anzi questo compito è facilitato perchè le istruzioni hanno una dimensione media più bassa (il codice CISC è solitamente più piccolo dello stesso codice scritto in RISC, perchè le istruzioni più comuni sono codificate con meno byte). Prelevando lo stesso numero di byte dalla cache preleveremo in media più istruzioni, a tutto vantaggio della fetch bandwidth.
Nel prossimo articolo mostrerò alcune delle principali tecniche usate per la branch prediction e poi proseguirò con lo stadio successivo: la decodifica delle istruzioni.







