Finalmente, dopo una lunga peregrinazione tra pipeline semplici e diversificate, oggi comincia una nuova serie di articoli che andranno a spolpare un boccone molto più succulento: i processori superscalari out-of-order, ovvero le CPU che hanno spinto la computazione ad alte prestazioni negli ultimi 15 anni.
Nello scorso articolo abbiamo visto come avere pipeline diversificate sia l’idea vincente per ottenere maggiori prestazioni: ogni pipeline può essere ottimizzata per una particolare classe di istruzioni, può avere un numero di stadi diversi, ed è (in teoria) possibile avere molte più istruzioni in-flight (cioè in transito in diversi stadi della macchina) contemporaneamente. Abbiamo visto come lo scoreboarding permetta di risolvere in maniera relativamente semplice i problemi di dipendenze tra istruzioni, e come questa soluzione impatti negativamente sulle prestazioni. Infatti, pur potendo completare fuori ordine, le istruzioni devono partire in ordine di programma e devono attendere fino a che i registri sorgenti e di destinazione non sono disponibili.
Questa soluzione è poco meno “rigida” di una pipeline semplice in-order e non permette di sfruttare una larga parte dell’ILP (Instruction Level Parallelism) disponibile nei programmi. Per risolvere il problema una volta per tutte dobbiamo cambiare completamente paradigma e passare ad un’architettura dataflow.
L’idea dietro l’architettura dataflow è semplice ed elegante, ed è stata brevemente sintetizzata qui: invece di eseguire le istruzioni in ordine di programma, è sufficiente eseguirle nell’ordine in cui gli operandi diventano disponibili. È un paradigma producer-consumer: appena un’istruzione finisce l’esecuzione, producendo un valore, sblocca tutte le istruzioni che dipendono da essa. L’esecuzione procede alla massima velocità direttamente lungo l’albero delle dipendenze.
Nonostante questa architettura permetta in teoria di ottenere il massimo IPC (Instructions Per Clock) possibile, essa è irrealizzabile in pratica per motivi tecnologici: la memoria CAM e la rete di distribuzione necessarie sono così grosse e lente da rendere un tale processore totalmente inefficiente.
Ricapitolando:
- pipeline parallele, diversificate e in-order sono pratiche da implementare, ma il controllo tramite scoreboarding è troppo rigido (sfrutta poco l’ILP, ottenendo basso IPC)
- un’architettura dataflow permette di sfruttare tutto l’ILP disponibile in un programma, ma è irrealizzabile
La soluzione sta nel prendere il meglio dei due mondi e costruire una macchina ibrida: un processore dotato di pipeline parallele (ognuna in-order al suo interno) che operi in “modo dataflow” su una piccola porzione del codice alla volta (da qualche decina a qualche centinaio di istruzioni). Ad ogni istante il processore mantiene una Instruction Window, cioè una piccola porzione di codice sequenziale: al suo interno il programma viene eseguito in modo dataflow, mentre la Instruction Window si muove in avanti una istruzione alla volta, in-order.
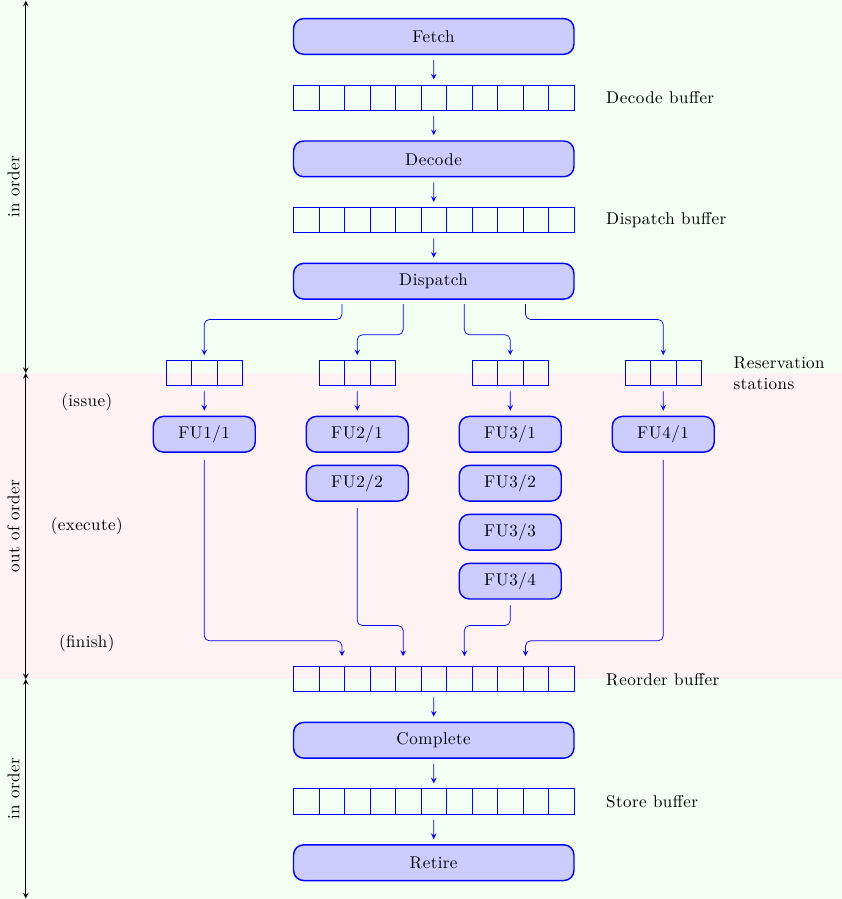
Il concetto è schematizzato in figura:
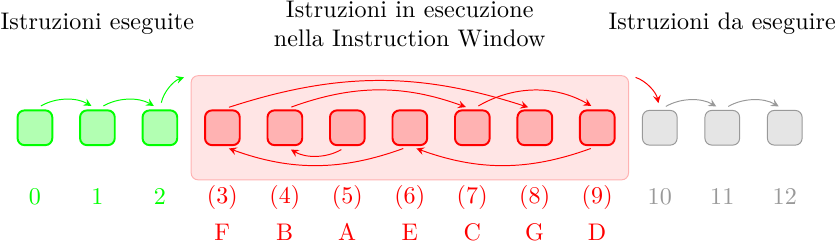
È importante ricordare che il processore deve mostrare al software l’illusione che le istruzioni vengano eseguite in ordine e una alla volta. In verde sono evidenziate alcune istruzioni che sono già state eseguite “in ordine” e “una dopo l’altra” (o così il software crede). In rosso sono le istruzioni che si trovano al momento all’interno della Instruction Window: esse possono eseguire in qualunque ordine, al dataflow limit, limitate unicamente dalle dipendenze reciproche. Questo non è un problema perchè il software non vede le istruzioni in questo stato di esecuzione: mentre eseguono, le istruzioni aggiornano i registri interni ma non quelli architetturali, e quindi il software è completamente all’oscuro di questa esecuzione fuori ordine. Tuttavia le istruzioni non possono uscire dalla Instruction WIndow in ordine arbitrario: devono uscire nell’ordine del programma, per ricostruire (a beneficio del software) l’illusione di una esecuzione sequenziale. Questo risolve anche il problema di avere eccezioni precise, che avevamo incontrato con lo scoreboarding.
Questo significa che le istruzioni A, B, C, D ed E, anche se hanno finito di eseguire, non possono uscire dalla IW fino a che l’istruzione F non ha completato. A quel punto la IW scatterà in avanti di 5 posizioni e le istruzioni {A, B, C, E, F} verranno ritirate in ordine (istruzioni 3, 4, 5, 6 e 7, sequenziali). L’istruzione D, benchè completata, non può essere ritirata fino a che l’istruzione G non ha finito di eseguire, e resterà nella Instruction Window fino ad allora. Quando la IW si muove in avanti, nuove istruzioni, mostrate in grigio, entrano nella IW e cominciano ad eseguire in ordine dataflow.
Che faccia ha un processore di questo tipo? Dato che le istruzioni eseguono in ordine dataflow ci aspettiamo che le pipeline di esecuzione operino out-of-order; e dato che le istruzioni entrano ed escono dalla IW in ordine di programma, ci aspettiamo che la sezione out-of-order sia infilata in “stile sandwich” tra due sezioni in-order che mantengono l’illusione di una esecuzione sequenziale del programma.
Se prendiamo come riferimento il processore a pipeline diversificate mostrato nello scorso articolo, allora esso viene modificato in questo modo:
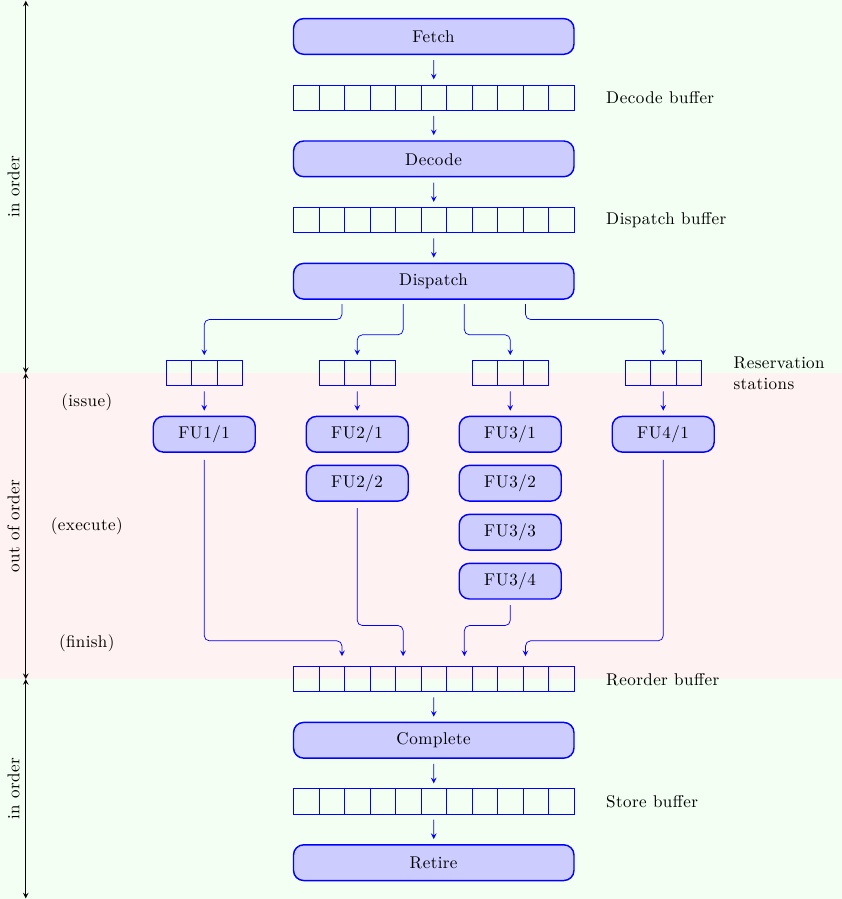
Prima di addentrarci nei dettagli dei singoli stadi è necessario avere visione d’insieme:
- come sempre le istruzioni cominciano il loro viaggio dagli stadi di fetch e decode, dove le istruzioni vengono prelevate dalla memoria e decodificate per capire come manovrare gli stadi successivi
- a questo punto le istruzioni potrebbero non essere ancora pronte pronte per eseguire (qualche operando potrebbe non essere ancora disponibile); vengono allora accodate ad un buffer di attesa (Reservation Station) dove aspettano il loro turno
- una volta pronte le istruzioni vengono lanciate nelle pipeline di esecuzione, in ordine dataflow; il termine “out-of-order” si riferisce alle istruzioni tra di loro, non alla struttura delle pipeline di esecuzione: le singole pipeline sono strettamente in-order (ad esempio un’istruzione che entra nella terza pipeline attraverserà i 4 stadi in sequenza, uno stadio per ciclo di clock, senza scavalcare o essere scavalcata da altre istruzioni, e senza stalli)
- una volta completata, l’istruzione viene inserita nel Reorder Buffer dove aspetta di completare in ordine (cioè uscire dalla IW in ordine di programma)
Come si vede, l’idea di fondo è piuttosto semplice. Come sempre, il diavolo è nei dettagli: progettare un sistema del genere è talmente complesso che ancora oggi, dopo decenni di studio e ingegnerizzazione di questa classe di CPU, solo una manciata di aziende sono in grado di farlo (IBM, Intel, AMD, Fujitsu con lo SPARC64, ARM col recente Cortex A9) e lo sforzo progettuale richiesto si misura in decine di milioni di ore-uomo e centinaia di milioni di dollari.
Una delle cose più curiose che qualcuno potrebbe aver notato è che le istruzioni non completano in un solo passo, ma in due se non tre passi differenti, qui indicati coi termini di finish, complete e retire. Il motivo è che le istruzioni devono prima finire di eseguire in ordine dataflow e poi uscire dalla Instruction Window in ordine di programma. Inoltre, gli store (le uniche operazioni capaci di scrivere in memoria, dato che all’interno di queste CPU “vivono” solo istruzioni simil-RISC) devono non solo terminare nel processore, ma anche aspettare che i loro dati attraversino la gerarchia di memoria fino a scrivere nella locazione corretta: per questa operazione è opportuno avere uno stadio dedicato.
Ora è il momento di immergersi un pò più a fondo nell’architettura e investigare stadi e operazioni in maggior dettaglio. La nomenclatura adottata in questo articolo viene da Shen, Lipasti, “Modern Processor Design”, forse l’unico libro che analizza in dettaglio l’architettura di processori superscalari out-of-order; altri libri e diverse compagnie usano termini differenti.
Fetch Il fetch delle istruzioni dalla Instruction Cache non è concettualmente diverso da quello delle pipeline più semplici, salvo il fatto che ora è assolutamente necessario prelevare più istruzioni per ciclo di clock: il numero di istruzioni lette dalla I-Cache limita la massima performance della CPU (non è possibile eseguire più istruzioni di quelle che sono state caricate dalla memoria e mandate in macchina). La fetch bandwidth è però limitata dalle dipendenze di controllo: bisogna eseguire i branch per sapere da dove prelevare le prossime istruzioni. Per questo motivo per i processori superscalari è fondamentale avere degli ottimi meccanismi di branch prediction, per continuare a prelevare istruzioni corrette (con alta probabilità) anche se i branch non sono ancora stati risolti. Le istruzioni lette dalla memoria vengono accumulate nel Decode Buffer, in attesa di essere decodificate.
Decode Anche in questo caso, la decodifica non è concettualmente diversa da quella di una pipeline singola; anche in questo caso, la differenza è il numero di istruzioni che devono essere decodificate. Per un processore superscalare è ovviamente necessario decodificare più istruzioni per ciclo di clock, e risolvere le dipendenze reciproche in “orizzontale” oltre che in “verticale” (cioè fra istruzioni decodificate nello stesso ciclo di clock, oltre che tra quelle decodificate in cicli successivi). Questo è particolarmente complesso per ISA CISC, dove le istruzioni hanno lunghezza diversa: come si fa a decodificare l’istruzione N+1 se non si sa dove finisce l’istruzione N? Ma visto che la necessità aguzza l’ingegno, sono state trovate tecniche per risolvere questo problema in modo molto efficace (a discapito di un maggior consumo di energia). Le istruzioni decodificate vengono accumulate nel Dispatch Buffer, in attesa di essere mandate alle unità funzionali.
Dispatch In una pipeline singola, tutte le istruzioni devono attraversare la stessa, unica pipeline. In un processore superscalare, invece, bisogna decidere verso quale unità funzionale instradare le istruzioni. Mentre le operazioni di accesso alla cache e decodifica sono eseguite in maniera centralizzata (una unità per tutte le istruzioni), le pipeline di esecuzione possono eseguire in parallelo in modo del tutto disaccoppiato: da qui la necessità di uno stadio che prelevi le istruzioni da un unico buffer di accumulo (il Dispatch Buffer) e le instradi alla corretta unità funzionale.
Reservation stations Un altro meccanismo necessario tra la decodifica e l’esecuzione di istruzioni è il buffering temporaneo in attesa degli operandi. Mentre nel Dispatch Buffer le istruzioni aspettano di essere inoltrate alla unità funzionale corretta, nelle Reservation Stations esse aspettano di avere a disposizione tutti gli operandi. Infatti è possibile che un’istruzione non possa prelevare i propri operandi dal Register File subito dopo la decodifica perchè qualche altra istruzione è in-flight nella pipeline e non ha ancora aggiornato i registri. Naturalmente sarebbe possibile stallare la decodifica fino all’aggiornamento del Register File, ma questo vanificherebbe tutti i vantaggi di questa architettura. Molto meglio stallare solo le istruzioni che non hanno ancora tutti gli operandi pronti e far proseguire le altre. Questo è il cuore dell’esecuzione fuori ordine: modificare on-the-fly l’ordine di esecuzione dall’ordine di programma all’ordine dataflow.
Issue, Execute, Finish Quando un’istruzione ha tutti gli operandi disponibili è pronta per essere lanciata nella sua pipeline. Il meccanismo di Issue sceglie, ad ogni ciclo di clock, una tra le istruzioni pronte e la manda in esecuzione. Una volta partita essa attraversa l’intera pipeline della sua unità funzionale (Functional Unit, FU) senza più stalli. Una volta uscita dall’ultimo stadio (Finish) l’istruzione aggiorna la propria entry nel Reorder Buffer, e lì attende il riordino.
Complete La Instruction Window avanza in ordine, ma le istruzioni completano fuori ordine: esse devono aspettare (dopo il Finish) nel Reorder Buffer fino a che non possono essere “completate” (cioè fatte uscire dalla IW) in ordine. A questo punto l’istruzione aggiorna i registri architetturali (cioè quelli descritti dall’ISA e visibili dal software) e termina l’esecuzione. Questo potrebbe essere vero per tutte le istruzioni, ma c’è un’ottimizzazione molto importante che può essere fatta per gli Store, e che necessita di un altro step.
Store buffer Mentre le normali istruzioni vivono e operano solo all’interno della CPU, gli Store operano anche al livello della memoria. Uno Store è completo quando ha terminato le sue operazioni nella pipeline di load/store e anche le operazioni nella gerarchia di memoria, scrivendo il suo valore nella locazione di memoria opportuna. Tuttavia non è necessario che le due operazioni vengano completate nello stesso momento. È possibile disaccoppiare le due operazioni mettendo in mezzo un buffer (come sempre!). Lo Store completa quando ha scritto il suo valore nello Store Buffer, un piccolo buffer all’interno della CPU. Da qui il valore verrà inoltrato alla memoria non appena questa sarà in grado di servire la richiesta. Una volta che la richiesta è stata servita, lo Store verrà ritirato (Retire) e sarà finito per davvero. Questo permette alla CPU di procedere alla massima velocità senza dover aspettare la memoria ad ogni Store. Questo passo si presta ad ottimizzazioni molto interessanti che permettono di ridurre la banda richiesta verso la memoria (e anche di alleviare la register pressure, particolarmente sentita in x86); presta anche però il fianco a problemi estremamente sottili e pericolosi in configurazioni multiprocessore (ad esempio: come è possibile sincronizzare l’accesso alla memoria tra i processori se il processore e la memoria vedono lo Store completarsi in due momenti diversi?).
Limiti alle prestazioni
Per la pipeline semplice avevamo identificato 3 limiti principali (qui, quinta figura):
- dipendenze dati nei registri (anello “ALU penalty”): bisogna fornire i risultati di un’istruzione di ALU alle prossime istruzioni di ALU il più in fretta possibile
- dipendenze dati dalla memoria (anello “load penalty”): bisogna portare i dati dalla memoria alle istruzioni che li necessitano il più in fretta possibile
- dipendenze di controllo (anello “branch penalty”): per continuare a fetchare istruzioni bisogna risolvere i branch il più in fretta possibile
Queste limitazioni sono intrinseche in qualsiasi macchina e quindi le ritroviamo anche nei processori superscalari. A causa del cambio di architettura, queste dipendenze si trovano in posti un po’ diversi:
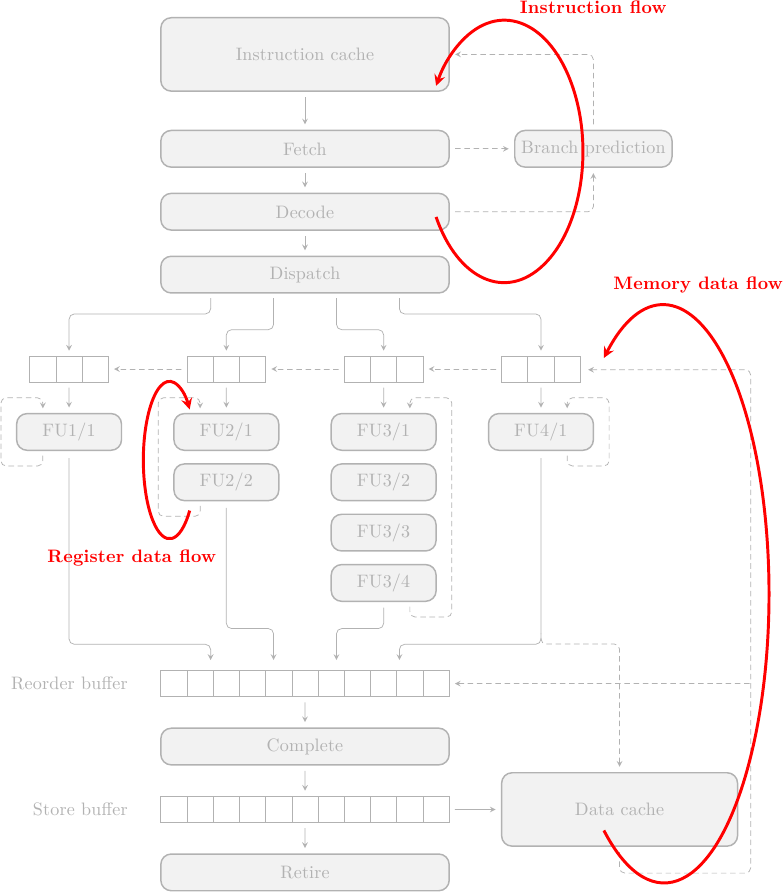
La risoluzione dei branch (Instruction Flow) può avvenire nel front-end o alla fine della pipeline di branch, a seconda di dove vengono prodotti il bersaglio e la decisione di salto; per un processore superscalare, tuttavia, risolvere i branch il prima possibile non è più sufficiente: la perdita di prestazione sarebbe tremenda (intuitivamente: dato che vengono eseguite N istruzioni in parallelo, per ogni ciclo di clock perso perdiamo non 1 ma N istruzioni). È assolutamente necessario spezzare le dipendenze di controllo tramite predizione dei salti, ovvero il processore deve eseguire istruzioni speculativamente, prima che il salto sia stato risolto, e deve azzeccarci molto molto spesso (più del 90% delle volte). Questo è possibile, ma richiede un intero armamentario di tecniche sofisticate.
La propagazione dei dati è simile al concetto di forwarding path visto per la pipeline semplice. Le ALU vivono nella zona di esecuzione della CPU, in quello spazio tra le Reservation Station e il Reorder Buffer. Tutti i movimenti dati tra registri non architetturali avvengono qui dentro: i valori prodotti vengono scritti nel Reorder Buffer e da qui propagati alle Reservation Station, dove le istruzioni in attesa posso “catturarli”. Esattamente come nel caso dei forwarding paths, questo permette di propagare i valori all’interno della macchina senza dover aspettare che questi vengano scritti nei registri architetturali.
La stessa cosa avviene per la memoria: i dati caricati dalla Data Cache vengono inoltrati sia al Reorder Buffer, dove i Load li stanno aspettando, sia alle Reservation Station, dove le istruzioni che dipendono da quei load li stanno aspettando. Di nuovo, riuscendo a bypassare i registri architetturali si riescono a risparmiare preziosi cicli di clock ad ogni accesso.
Conclusioni
In questo primo articolo abbiamo visto i concetti principali dietro la realizzazione di un processore superscalare out-of order e abbiamo visto come questo abbia le potenzialità per schiacciare (in termini di prestazioni) tutte le altre pipeline viste finora.
L’architettura è estremamente complessa e ogni stadio richiede tecniche complesse per raggiungere le prestazioni desiderate e non diventare il collo di bottiglia dell’intera macchina.
Nei prossimi articoli entrerò nei dettagli dei singoli stadi, analizzando le tecniche principali usate nei processori high-end che tutti ormai abbiamo nei nostri personal computer.







