Nello scorso articolo abbiamo visto come pipeline profonde diventino rapidamente inefficienti a causa dell’aumento del numero di stalli necessari al loro corretto funzionamento, e come pipeline più corte ma più larghe (“superscalari”) possano ottenere prestazioni molto migliori ad un costo più basso.
Abbiamo anche visto come nella maggior parte dei programmi esista abbastanza ILP da alimentare queste ipotetiche “pipeline multiple”. Rimane la domanda: che aspetto hanno queste pipeline? Sono semplicemente tante pipeline semplici incollate l’una di fianco all’altra, identiche tra loro, o è qualcosa di più complicato?
Prendere la stessa pipeline semplice in-order e fare copia-incolla è sicuramente facile, ma non è molto efficiente. Per poter eseguire tutti i diversi tipi di operazioni, la pipeline singola ha più stadi di quelli strettamente necessari: ad esempio, un’operazione di ALU non userà lo stadio di accesso alla memoria, mentre un branch potrebbe non usare la ALU, eccetera.
Inoltre, alcune operazioni sono così più complesse di altre (si pensi ad una divisione floating-point rispetto ad una somma tra interi) da aver bisogno di molti cicli di clock in più per poter essere completate. Ciononostante, tutte le istruzioni nella pipeline semplice devono attraversare tutti gli stadi, per mantenere la corretta sequenza.
Allargare il datapath ci offre quindi un’interessante opportunità: fare sì tante pipeline affiancate, ma diverse, ognuna specializzata per una diversa classe di istruzioni. La pipeline per l’esecuzione degli interi potrebbe essere composta da solo uno o due stadi, mentre le pipeline per le operazioni floating-point sarebbero più lunghe e più complesse.
Questo permette da un lato maggiore libertà sul dove spezzare la logica in stadi (consentendo di raggiungere più facilmente frequenze maggiori) e dall’altro di far attraversare ad ogni istruzione il minor numero di stadi possibile (solo quelli che le servono), consentendo di risparmiare tempo ed energia.
Sul numero e tipo di pipeline ottimale si potrebbe discutere all’infinito: esso dipende dalle prestazioni che vogliamo ottenere, dal costo in denaro ed energia che siamo disposti a pagare, dal tipo di programmi che dovranno girarci sopra, eccetera. I tipi di pipeline specializzati più comuni sono quella per gli interi (spesso divisa tra somma/sottrazione e moltiplicazione/divisione), quella per i floating point (anche qui divisa per operazioni), quella per i load/store, e quella per i branch (spesso fusa insieme a quella degli interi).
È anche comune avere più pipeline dello stesso tipo: CPU orientate ad applicazioni scientifiche avranno più pipeline floating-point (ad esempio 2 per le somme, 2 per i prodotti e 1 per le divisioni, oppure una MAF che fonde insieme somma e moltiplicazione), mentre CPU dedicate ad applicazioni webserver avranno più pipeline per interi e load/store, e magari neanche una pipeline floating-point (il Niagara aveva un solo coprocessore FP condiviso tra ben 8 core e 32 thread).
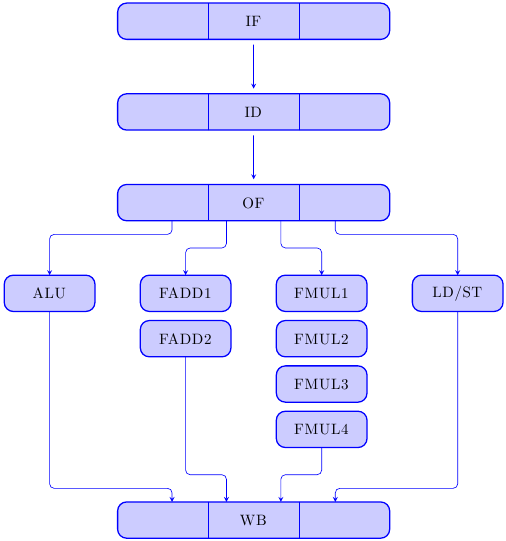
Il datapath del processore comincerà ora ad assomigliare a qualcosa del genere:
dove i primi stadi sono rimasti uguali e l’esecuzione è “esplosa” in pipeline multiple dedicate.
Una volta deciso che fare pipeline parallele e specializzate è il modo migliore di spendere i nostri transistor, resta da capire come alimentarle. Di quante istruzioni bisogna fare il fetch per ogni ciclo di clock? Possiamo sempre fare il fetch di più istruzioni? Di quali dipendenze bisogna tenere conto?
La nostra vecchia pipeline in-order era facile da trattare: una sola istruzione per ciclo di clock, tutte in ordine, e ogni istruzione deve controllare solo quelle davanti a sè per risolvere le dipendenze. Ma ora? Se facciamo comunque il fetch di una sola istruzione per ciclo di clock, il vantaggio è minimo (se esiste): è appena più veloce della pipeline singola, dato che le istruzioni non devono attraversare stadi inutili, ma in compenso usa molto più hardware.
Se facciamo invece il fetch di più istruzioni per ciclo di clock dobbiamo cominciare a controllare le dipendenze non solo “verticalmente” (cioè tra istruzioni caricate in diversi cicli di clock) ma anche “orizzontalmente” (cioè tra le istruzioni caricate nello stesso ciclo di clock).
Purtroppo, ora tutti gli hazard che avevamo risolto per la in-order pipeline tornano a insidiare la nostra architettura. Supponiamo di stare lavorando con la CPU illustrata sopra; allora dobbiamo fare i conti con:
- control hazard: come sempre i branch possono modificare il flusso delle istruzioni, quindi bisogna collegare la pipeline dei branch allo stadio di fetch, per ridirigere il controllo di flusso
- structural hazard: supponiamo che la CPU faccia fetch di 2 istruzioni per ciclo di clock, e supponiamo che siano entrambe degli ADD interi; una volta arrivate allo stadio di esecuzione entrambe vorrebbero entrare nella pipeline intera, ma ce n’è solo una! Quale istruzione andrà in esecuzione? Come fare a decidere? Cosa succede all’altra istruzione? In qualche modo dovrà aspettare il prossimo ciclo: o stalliamo il processore a monte, per assicurarci che non ci siano altre istruzioni dello stesso tipo in arrivo e garantire che ogni istruzione abbia la sua chance di andare in esecuzione, oppure dobbiamo costruire un buffer che raccolga le istruzioni in attesa che la loro unità funzionale si liberi (nei processori OOO si usa questo sistema, e i buffer prendono il nome di “Reservation Station”)
- RAW (read after write): la situazione è molto simile a quella della pipeline in-order: un’istruzione che dipende da un’altra dovrà aspettare che la prima abbia completato; ad esempio:
f1 <= f2 * f3 (parte al ciclo 1, termina al 5) f4 <= f1 + f5
La seconda istruzione vorrebbe partire al ciclo 2, ma deve aspettare che l’operando f1 venga prodotto e reso disponibile al ciclo 5. Questa situazione è uguale a quella della pipeline in-order, ma con una complicazione in più: ora le dipendenze vanno controllate (e i forwarding paths abilitati) anche tra le diverse pipeline (come nell’esempio, oppure quando un load dipende dal risultato di un calcolo intero, eccetera)
- WAW (write after write): questa è una situazione nuova: la in-order pipeline non soffre di questo tipo di hazard perchè tutte le operazioni di memoria avvengono nello stesso stadio (stadio MEM), così come tutte le operazioni sui registri (sempre letti nello stadio RF, sempre scritti nello stadio WB, da tutte le istruzioni); ora però diverse pipeline hanno profondità diverse, e quindi possono verificarsi situazioni spiacevoli. Consideriamo questo esempio:
f1 <= f2 * f3 (parte al ciclo 1, termina al 5) store f1 f1 <= f2 + f3 (parte al ciclo 3, termina al 5) store f1
Entrambe le operazioni vogliono scrivere il registro f1 al ciclo 5! Chi deve farlo? E come garantire che i diversi store (che sono in esecuzione su una pipeline separata e nulla sanno del conflitto che si è verificato tra le pipeline floating point) ottengano ognuno il suo valore corretto? Anche qui serve un controllo esaustivo di tutte le combinazioni che possono generare hazard.
- WAR (write after read): questo hazard è più sottile, e può verificarsi nel caso un’istruzione più “giovane” scavalchi una più “vecchia” andando a sovrascrivere un registro prima che la più “vecchia” possa leggerlo. Esempio:
f3 <= f1 * f2 f1 <= f4 + f5
La situazione sembra a prima vista perfettamente regolare: il prodotto parte al ciclo 1 e termina al ciclo 5, leggendo il registro f1 al ciclo 1; la somma parte al ciclo 2, e produrrà il nuovo registro f1 al ciclo 4. Consideriamo però questo caso:
- si esegue il fetch di 2 istruzioni contemporaneamente
- c’è stata un’abbondanza di istruzioni FMUL (“floating point multiply”) appena prima di questa coppia di istruzioni
- esite un buffer (Reservation Station) abbastanza grande da accodare tutte le FMUL senza stallare la macchina a monte
- le istruzioni caricano il valore degli operandi appena prima di andare in esecuzione (può sembrare strano, ma è una tecnica usata)
Allora, il prodotto verrà accodato in un buffer in attesa di poter eseguire, mentre la somma andrà subito in esecuzione perchè la sua pipeline è libera. Supponiamo che il prodotto venga ritardato di 3 cicli di clock; allora lo scheduling sarà:
- ciclo 0: la somma va in esecuzione
- ciclo 2: la somma completa e scrive il registro f1
- ciclo 3: il prodotto va in esecuzione, caricando il valore sbagliato di f1!
Il problema è che la somma ha sovrascritto f1 prima che la moltiplicazione avesse l’opportunità di leggerlo. Come si vede, questo hazard è più sottile perchè richiede che tutta una serie di condizioni nell’hardware e nel software si verifichino contemporaneamente. Ma visto che può succedere, anche in questo caso è necessario un controllo esaustivo di tutte le combinazioni che possono generare questo hazard.
Fetch in-order, completamento out-of-order: lo Scoreboarding
Tenere traccia di tutte le condizioni descritte sopra per tutte le istruzioni in-flight nella pipeline non è banale, ma esiste almeno una soluzione concettualmente semplice che risolve tutte le dipendenze RAW, WAW e WAR. Bastano poche semplici regole e un “tabellone segnapunti” che tenga traccia dello stato dei registri (è sufficiente un bit per registro: mettiamo il bit a 0 se il registro contiene dei dati validi, a 1 se invece il registro contiene dei dati “sporchi”, cioè che verranno sovrascritti da un’istruzione che è attualmente in-flight nella CPU).
Chiamo Rs e Rt i registri degli operandi, Rd il registro di destinazione, FU l’unità funzionale per l’istruzione, e sb[x] lo stato dello Scoreboard per il registro x. Le regole sono:
- dispatch in-order
- Rd <= FU(Rs, Rt)
- se sb[Rs] o sb[Rt] vale 1 => RAW, stall
- se sb[Rd] vale 1 => WAW / WAR, stall
- altrimenti manda l’istruzione alla FU e setta sb[Rd] a 1
- complete out-of-order
- aggiorna register_file[Rd], resetta sb[Rd] a 0
Il significato di queste regole è:
- lancia le istruzioni in esecuzione in ordine (ci possono essere stalli tra loro, ma sono sempre in ordine di programma)
- per ogni istruzione, controlla se i suoi registri operandi sono “puliti”: se non lo sono vuol dire che qualcuno li sta calcolando (RAW hazard), quindi stalla l’istruzione fino a che non vengono aggiornati al valore corretto
- per ogni istruzione, controlla se il suo registro di destinazione è “pulito”: se non lo è vuol dire che qualcuno lo sta per scrivere (WAW / RAW hazard), quindi stalla l’istruzione fino a che non viene scritto
- se non ci sono hazard, lancia l’istruzione in esecuzione e segna come “sporco” il registro di destinazione
- quando l’istruzione ha finito, aggiorna il registro di destinazione e segnalo di nuovo come “pulito”
In questo modo non può succedere che un registro venga letto o scritto prima del dovuto. Prendiamo come esempio questo pezzo di codice:
i0: FDIV R3, R3, R2 i1: LD R1, 0(R6) i2: FMUL R0, R1, R2 i3: FDIV R4, R3, R1 i4: FSUB R5, R0, R3 i5: FMUL R3, R3, R1
dove la sintassi è: <istruzione>, <registro di destinazione>, <operando/i>.
Supponiamo delle pipeline un po’ diverse da quelle viste sopra, con 1 ciclo di clock per le addizioni floating point, 3 per le moltiplicazioni e 4 per le divisioni (mi scuso per l’inconsistenza, ho sviluppato i due esempi separatamente per far risaltare bene i casi speciali e solo quando li ho messi insieme mi sono accorto di non essere stato consistente). L’evoluzione temporale dello Scoreboard è la seguente:
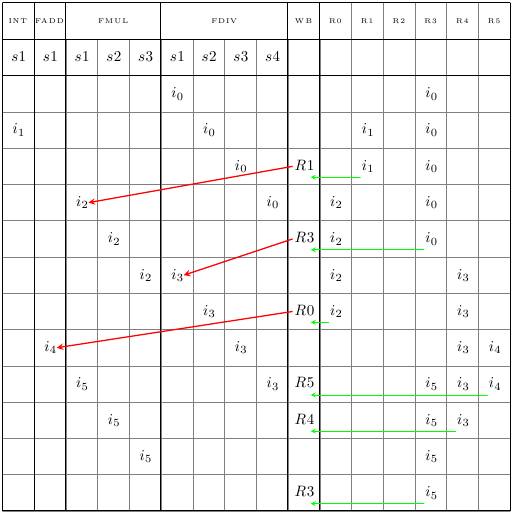
Nelle colonne dei registri ho segnato l’istruzione che sta usando quel registro in quel ciclo di clock, e nella colonna del WriteBack il registro che viene aggiornato. Ho anche assunto per semplicità di rappresentazione che non ci siano forwarding paths (nemmeno nel register file) e che venga fatto il fetch di una sola istruzione alla volta. Inoltre, nella tabella ho rappresentato per semplicità solo gli stadi della fase di esecuzione.
Seguiamo il percorso delle prime istruzioni, per capire bene come funziona lo Scoreboarding:
- al primo ciclo di clock la prima istruzione (i0) può andare subito in esecuzione, ed entra nel primo stadio della pipeline floating-point dedicata alla divisione; immediatamente viene bloccato il registro di destinazione R3; l’istruzione attraversa tutti gli stadi per 4 cicli; al quinto ciclo R3 viene aggiornato e “rilasciato” (freccia verde)
- nel frattempo la seconda istruzione (i1) non ha alcun conflitto con i0 e può partire, occupando per un solo ciclo la pipeline degli interi; essa blocca il registro di destinazione R1 per due cicli, aggiornandolo e rilasciandolo al terzo ciclo (freccia verde)
- la terza istruzione (i2) vorrebbe partire al terzo ciclo, ma non può: essa dipende da R1, che non è ancora stato reso disponibile al register file (infatti la sua flag nello scoreboard è ancora asserita); al quarto ciclo i1 rilascia il registro R1 e i2 può iniziare l’esecuzione (la freccia rossa mostra la risoluzione della dipendenza)
… e così via. In questo esempio ho mostrato solo dipendenze RAW, ma la cosa funziona allo stesso modo anche per le WAW e WAR. Per gli hazard strutturali invece bisogna bloccare le istruzioni in qualche modo (ce ne sono molti) nel caso manchino le risorse hardware.
La cosa interessante da notare è che mentre nella pipeline in-order classica le istruzioni stallano all’interno della pipeline quando necessario, qui invece stallano alla testa della pipeline (nella Reservation Station, per abusare un po’ del termine), ma una volta entrate nelle unità funzionali proseguono fino alla fine senza stalli. È anche importante notare che le istruzioni possono davvero terminare fuori ordine: nell’esempio, l’istruzione 1 termina prima della 0 e la 4 prima della 3. Tuttavia, grazie al check preventivo dei registri, il risultato finale è sempre corretto.
Questa soluzione semplice ed elegante nasconde però alcuni problemi:
- lo scoreboard può diventare facilmente il collo di bottiglia: se facciamo il fetch di più istruzioni contemporaneamente, e abbiamo molti registri, ci sono un sacco di controlli che devono essere fatti in modo centralizzato, accedendo sempre allo Scoreboard; inoltre, lo Scoreboard deve sostenere, per ogni ciclo di clock, scritture e letture multiple senza glitch o conflitti
- le eccezioni sono imprecise: in genere, quando si verifica un’eccezione (trap, fault, interrupt, exception) è bene che la CPU sia in uno stato “preciso” in cui tutte le istruzioni _prima_ dell’eccezione hanno completato e aggiornato i registri architetturali, e tutte le istruzioni _dopo_ l’eccezione non sono state eseguite; con lo Scoreboarding questo non è possibile, perchè le istruzioni completano fuori ordine (ad esempio, se la terza istruzione fosse una divisione per zero genererebbe un’eccezione, ma la quarta istruzione avrebbe già completato e aggiornato il register file, portando la CPU in uno stato ambiguo). Avere eccezioni precise non è strettamente necessario, ma aiuta enormemente i progettisti di sistemi operativi e permette di gestire le eccezioni più rapidamente
- l’incremento di prestazioni c’è, ma comunque molte occasioni di ottimizzazione vengono perse; nello scampolo di codice precedente, scambiare di posto le prime due istruzioni porterebbe la terza istruzione (FMUL) a partire un ciclo di clock prima; tuttavia questo tipo di macchina non può sfruttare questa ottimizzazione perchè le istruzioni vengono lanciate in esecuzione strettamente in ordine
La tecnica dello scoreboarding è relativamente semplice e funziona bene in molti casi. Per spremere il massimo delle performance dall’hardware e risolvere il problema delle eccezioni imprecise bisogna però passare al “Santo Graal” dell’architettura delle CPU, il meglio disponibile ancora oggi: le CPU superscalari out-of-order, di cui mi occuperò nel prossimo articolo.







